




数据质量的一个重要组成部分就是对数据完整性的要求。它是通过数据完整性规则来产生作用。所以,对完整性规则的理解,设计,以及应用也显得尤为重要。
精确的数据完整性规则可以分为六类:无条件和有条件的数据规则,无条件和有条件的数据结构规则,数据获取规则和增量获取规则,数据保留规则,数据选择规则,数据换算规则。

数据规则
无条件的数据规则指无条件的数据值域,它可以在所有条件下应用,没有任何特例。而有条件的数值规则,顾名思义,则指在一定条件下或特殊情况下才应用,它会指定允许值的范围。
数据的值域是指一种数据特征下的允许值的集合,它可能是数据枚举值,或是数据规则。数据规则指数据值域以表达式的形式存在,或者说是给定最大、最小值。如:
“利率”>=4%,100<=“主办单位”<=200等
而数据值域则一般指定一系列的枚举值,如下图“性别”。
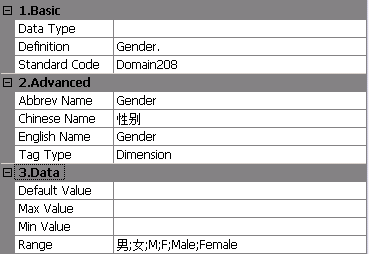
在一些数据资产平台中,扩展了这个数据规则域,如正则表达式。

数据结构规则
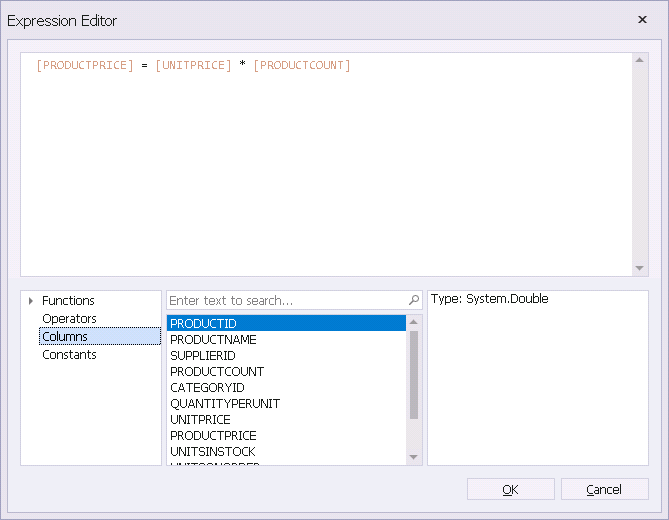
无条件的数据结构规则指两个数据主题(一般是列)间的关系可以在所有条件下无条件应用,比如:商品总价应该是单价*商品数量。
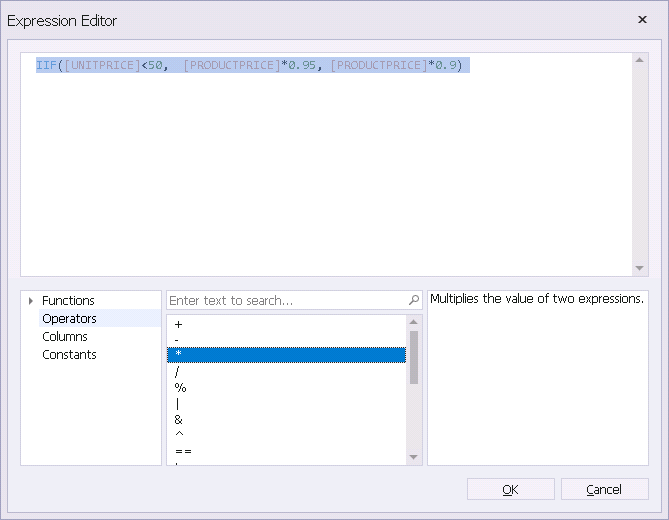
有条件的数据结构规则指两个数据主题间的关系只在一定条件或特殊场景中应用,比如:一次促销活动中,低价商品打95折,高价商品打9折。
而价格高低的定位是看价格是否高于50元。
那么两列之间的关系可以表示为:
IIF([UNITPRICE]<50, [PRODUCTPRICE]*0.95, [PRODUCTPRICE]*0.9)
如下图。
数据获取规则
数据获取规则指定从哪些地方来获取数据,用什么样的逻辑获取,以及在什么条件下获取。数据增量获取规则指当首次获取之后,如何再次获取时的规则。
数据获取规则可以由获取数据的逻辑产生。一个简单的源,一个简单的数据特征值,一个生成数据值的规则;或是多个数据源,许多数据特征来生成数据;或是能获取数据的所有源中具备统一数据特征数据值的聚合。
数据源可能是活跃的或非活跃的。活跃数据源是指数据仍然存在,而且它的值可能会发生变化。非活跃数据源中的数据已经不存在或是它的值不会变变化,对这样的源,首次完成之后不需要重新获取。
现在有很多工具都开始了对多数据源的表进行数据抽取及融合的操作,如Datablau就支持多个异构的数据源: 结构化(如EXCEL),关系型(如Oracle),NoSQL(Hive)等,它可以对每个数据源及融合操作指定获取规则。
数据保留规则
数据保留规则指数据需要保留多久,并且,如果数据无用后,如何处理它们。它指为了防止重要数据在更新或删除操作时丢失而创建的条件。可能运营不再需要的数据,但对评估仍然需要。数据特征保留规则可以规定每个数据特征值的保留情况。如:活动结束时间在3年前的数据所有特征值自动丢弃。
[活动结束时间]>ADDYEARS(NOW(),-3)
数据发生保留规则指在数据的一个属性出现(非空)时保留其所有数据特征。如:一次逾期的数据保留。
!ISNULLOREMPTY([PayOverdue])
数据选择规则
数据选择规则是指在特定的选择标准下通过的数据。如:只选择符合以下条件的数据。
商品价格 <= ‘50’ & 存贮时间 >= ‘10个月’
数据换算规则
数据换算规则定义数据从一个单元到另一个单元的所有步骤。它把一个简单事实数据转移到不同的单元中,与生成的区别是它不会对原数据的值进行任何改变,只是单位换算。
换算可以分为两种:静态数据和动态数据换算。
静态换算指基于相同换算条件,如时、分,秒之间的换算,固定为60进制。
动态换算指换算条件可能是变化的。如货币兑换,人民币兑美元。
了解数据完整性规则后,在设计和应用完整性规则的时候,还要注意四个原则:继承性、显示或隐式、避开规则锁、违规操作。

继承性
数据完整性规则可以像数据定义一样被继承。基础的数据完整性规则可以复用在许多具体的完整性规则上,但不是直接作用在数据上。具体的数据完整性规则可以独立生成,也可以从基础规则上继承,并且作用于数据。如果对基础规则做修改,它的变化会自动应用在所有继承它的具体规则上。基础数据完整性规则的设计原则是从最小的一组规则中提取最大公共的部分。
显示或隐式
数据完整性规则可以是隐式的或显式的。隐式的规则隐含在数据结构中,但不能明确的称作数据完整性规则。比如,主键。而显式的规则使用正式的数据规则表示方法表示出来。所有的隐式完整性规则必须明确说明,以确保应用时的一致性,这样才能维护好高质量的数据源。
规则锁

数据完整性规则锁在两个以上的规则同时生效时可能会出现。如果产生了某种条件,在这种条件下,数据不能通过验证规则,注定失败,这就是触发了规则锁。在生成数据完整性规则时必须要复查来防止锁定。
违规操作
每一个规则必须指定违规后的操作,及该操作对应通知处理。完整性规则违规操作指当数据违规发生时,应该采取的行为。一般情况下,可以采用以下几种方式:替换错误信息为一些有逻辑的有用的提示;挂起数据等待进一步修复;应用默认值;接受数据,但打个标记,再或是删除数据。
数据完整性规则通知指在数据未通过校验或是违规操作发生时,需要指派到对应的人。典型的操作可以是提醒负责人来进行修复,或是在失败日志中记录下来以备日后检查。其主要原因就是告知相关人员来采取防护性措施,来保证以后不会再出现同样错误。
有的工具会提供这方面详细的质量报告,可以把具体违规的数据及规则生成质量任务,并且提供邮件通知,在负责人把问题修复后,可以手工触发或通过计划任务触发质量监控,来确认问题的修复程度。从而做到有效防护。
对于业务活动而言,数据违规应该尽快的修复才会有价值。我们应该主动进行数据防范 - 识别错误并防止问题再次发生,即便不能完全防止,也要显著降低错误发生的机率。
在很多既有系统中两种方式可能都会引入不必要的对生产环境影响,这个时候可以用逆向工程,通过质量任务,随时监控数据,只修改需要的数据这种方式,也是有效应用完整性规则的一个重要思路。
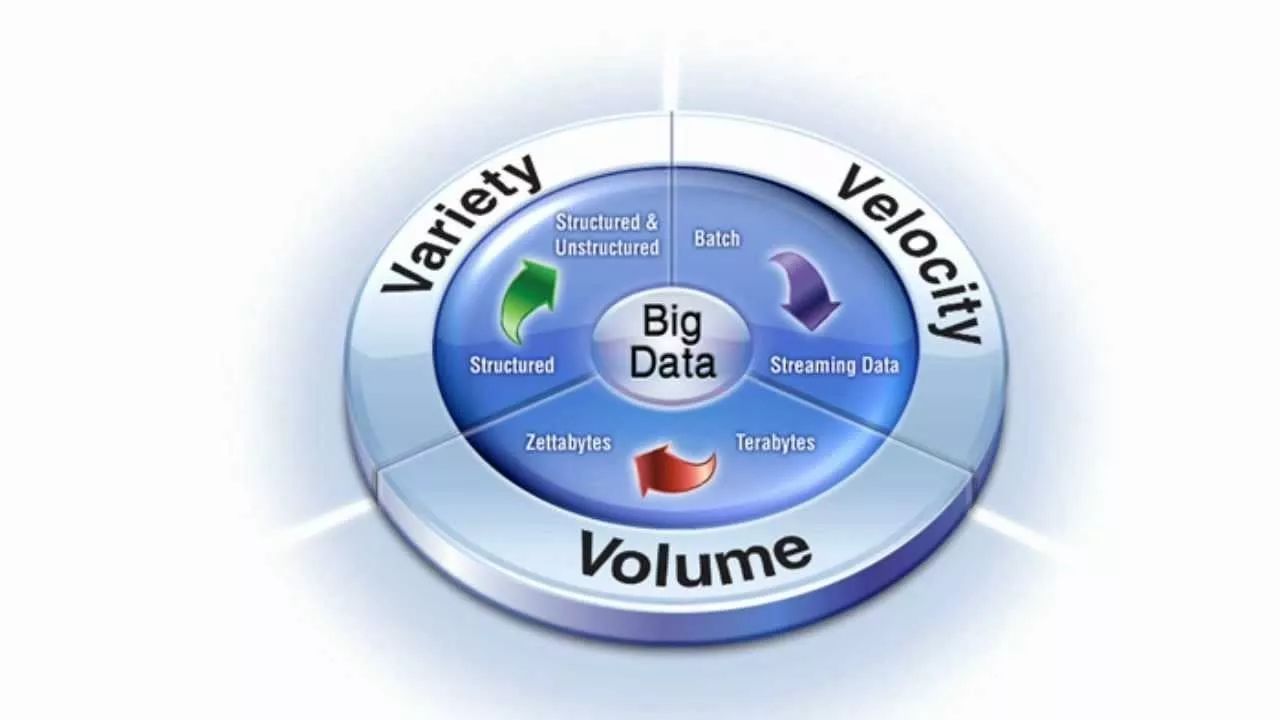
大数据量(Volume),快速(Velocity)和多样性(Variety)被称为数据的三V属性,会在看上去有些排斥精确数据完整性规则,这被称为3V合理避规。人们或许不能实时地复查并且更正这种大量,快速和多样的数据,但是,不可否认,这些规则的运行可以实时提供一致地规范操作指导。
其实,一些典型的3V违规操作可以采用算法自动修复,如设默认值,或删除非法数据等。3V的通知操作,因其违规则数据量太大,所以一般只会提供一个列表,说明所有错误类型和已进行的操作,或是提供总结性的数据:错误数量及修复操作的数量。
许多人常常强烈报怨难以描述清楚违规操作和通知操作。他们的观点是,指定精确数据完整规则费时费力,但找到违规和提供通知操作却没什么用处。对于这些报怨的最好方法好像只能是删除数据,并忽略所有未通过数据完整性规则的通知。但这么做的现实往往会回到讨论建立完整性规则本身是否有必要。
最后,数据管理的专家必须正规地开发精确数据规则,并且不断地应用到进入组织内的所有数据源上。数据规则引擎正在兴起,解决这方面的工具也越来越多,都可以通过对精确规范文档的自动化来实现并增强这些规则。精确数据完整性规则,如正式的数据名称、综合的数据定义以及恰当的数据结构是确保高质量数据源的基本要求。
更多精彩文章关注DatablauTech与您分享

