




我们的考量
基于以下的几点的考量,我们选择开发出一套一站式的机器学习平台,服务于推荐、搜索、风控、AI等等各种业务场景
1. 工程问题
算法模型从开发到上线经历着复杂的过程,其中每个过程都需要耗费算法工程师们大量的时间,算法同学真正用的模型开发及模型优化的时间上很少,同时这些过程中大量的工作都是很重复性的工作,有的可能只是变更数据集,有的可能只是变更一些参数。
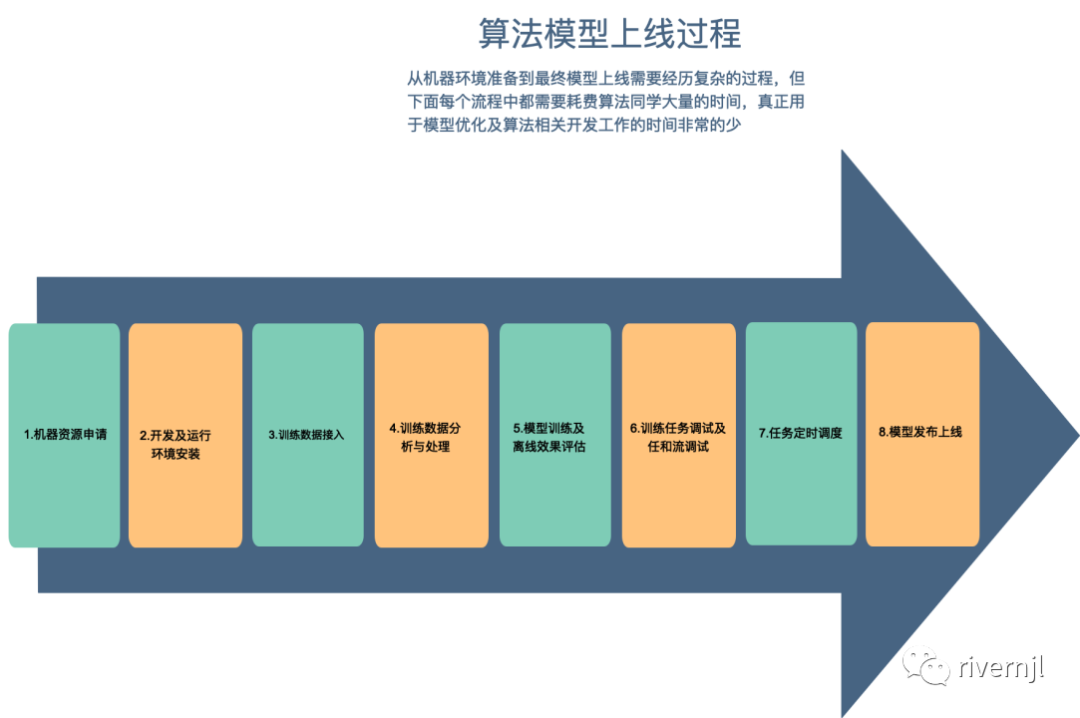
2. 资源问题
各种资源散落在不同的团队及个人开发手上,资源无法得到有效的利用,各开发人员经常出现资源使用排队,但是整体资源的利用率又非常的低
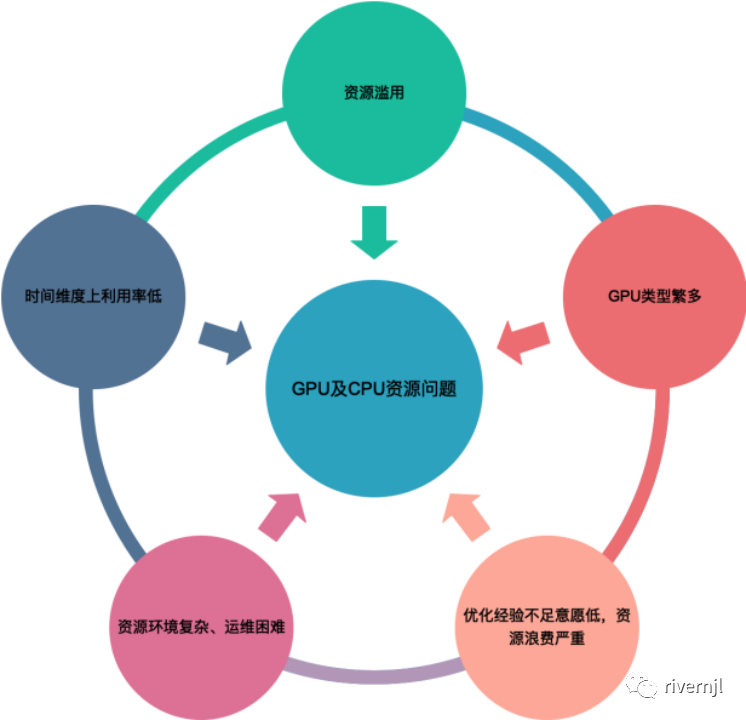
如生产环境、预发环境上的在线服务独占GPU,但是在很多小业务场景下GPU资源使用率非常低下特别是在一些预发环境下经常出现偶尔才有请求的情况。
资源在时间维度利用率低下
有很多团队下的训练是单机多卡的模式训练,任务之间的训练无法跨越单机的限制,任务之间的训练靠人工去控制资源,多台机器在同一时刻无法达到最大化利用率,比如A机器上的任务把机器资源已经跑满负荷了,B机器上当前可能资源剩余很多
GPU机器当作CPU机器使用
超大型CPU任务在GPU机器上跑或者是GPU任务流中的大型CPU计算过程在GPU机器上执行(占用磁盘、机器网络资源、GPU任务计算过程中所需要的CPU及内存资源等等)
资源环境运维困难,机器迁移扩容效率低下
很多时候开发人员的任务开发及运行环境与固定机器绑定,如果机器出现损坏、裁撤、扩容机器等这些复杂的环境都需要重做一遍,有时出现几天甚至更久才能交付一台机器,同时单机资源有限在大型算法模型情况下经常会出现如磁盘,内存等资源不足
业务开发人员对代码及架构的优化经验、意愿不高,导致资源无法有效利用,机器成本上升快于业务发展
大部分情况下相关算法人员对资源利用优化经验或者意愿并不高,基本上是通过加机器来满足计算资源的不足,但有时候能过技术架构和代码的小小优化能节省大量的资源成本
3.技术型问题
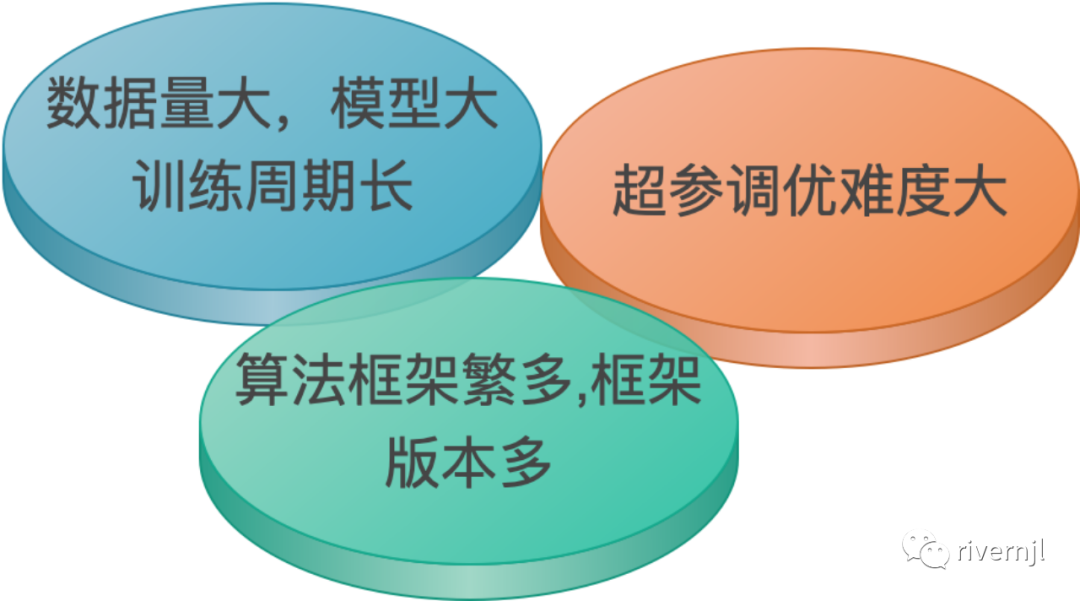
数据量大,模型大单机无法支撑,同时模型训练周期过长,线上模型线新缓存,影响业务
单模型训练周期长,无法进行超参搜索,模型参数优化难度大,工作效率低下
算法框架多,不同团队对算法框架要求不一样,如TF、Pytorch、Sklearn、XGBoost等等,各自版本要求不一样,环境复杂,运维难度和工作量极大
基于上述的一些问题我们需要
1: 资源统筹与边缘计算
统一资源管理,将以人管理资源改变成机器进行资源管理,平台管理资源申请及资源调度,对不合理资源申请进行智能修正,同时采用合理的智能的调度算法对行计算资源调度,使资源达到最大化利用
边缘计算,减少大数据量传输
对GPU进行虚化,减少GPU资源浪费
2: 提供一站式模型训练功能
开发、运行等环境模版化,达到只需几秒钟就能复制一套新环境
提供便捷的开发工具,开发人员可以快速的进行环境安装制作及代码开发、调试、发布上线
提供任务流编排功能,使用者通过组件拖拉的形式即能编制出一套复杂的训练流程
提供训练任务定时调度功能,支持各种的定时任务操作(补录,忽略,重试,依赖,并发限制)
3: 将复杂技术模版化、组件化
提供超参数搜索组件,算法同学能方便快捷的进行超参数调优,提高工作效率
提供模版化如Pytorch\TF\XGBoost\Spark\Ray\Horovod\Volcano等等分布式训练组件,使用者能过简单的拖拉组件就可以完成复杂的分布式计算过程
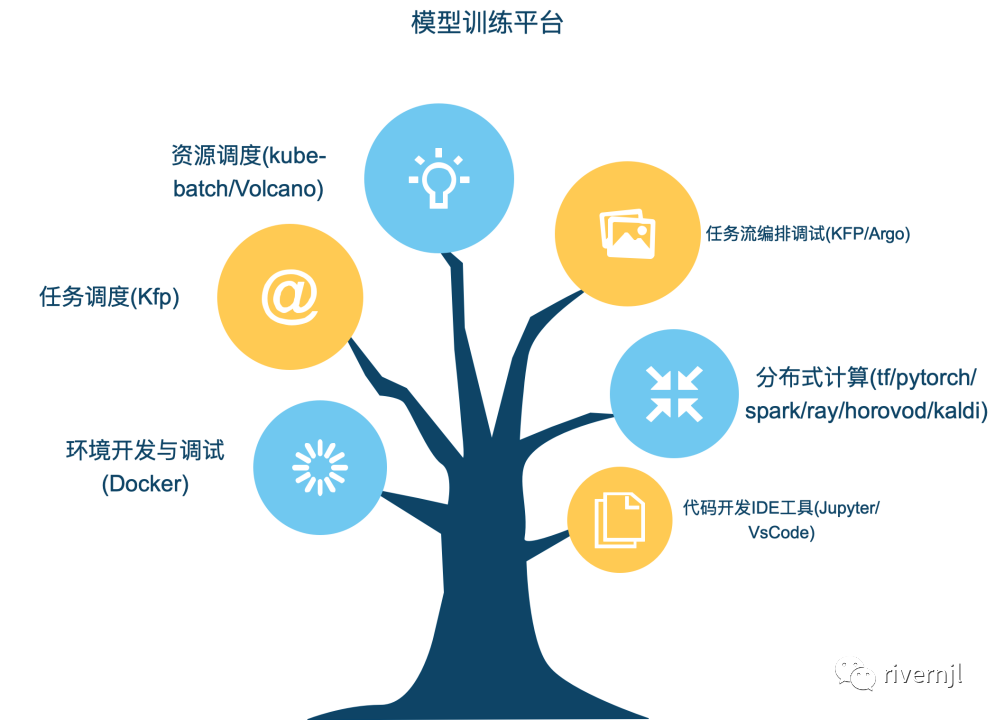
基于云生态架构,搭建一站式机器学习平台
技术的选型
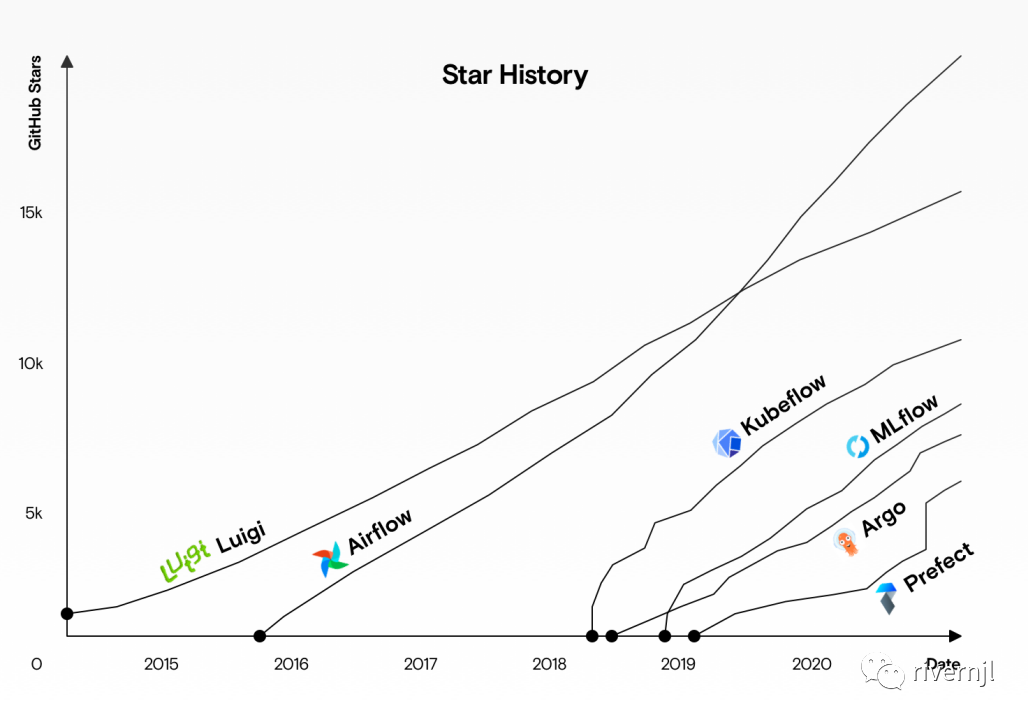
在机器学习领域,大家可能接触到最多的有Airflow\MLflow\Kubeflow等等,除了MLflow和Kubeflow大部分的开源框架都只是偏向于任务流编排及任务定时调度的,对于机器学习相关的支持没有或者是很弱,其中的MLFlow在机器学习领域内应用比较还是比较多的,但是MLFlow只适合于小规模团队与小规模的模型训练,对于大型分布式计算、资源统筹调度等等支持还是比较弱。
1: 基于行业发展趋势
Kubeflow是由Google开源出来,Kubeflow 旨在通过提供一种直接的方式将用于机器学习的同类最佳开源系统部署到各种基础设施,从而使机器学习工作流在 Kubernetes 上的部署变得简单、便携和可扩展,同时有两大 IT 趋势开始升温——云原生架构的主流化,以及对数据科学和机器学习的广泛投资,Kubeflow 完美地定位于这两种趋势的汇合点。它是云原生设计,专为机器学习用例而设计
2: 基于公司现状的需要
由上面我已经介绍过了我们的痛点及需要解决的问题点,基于Kubernetes 的原生架构能构更好更快的集成开源组件运用到机器学习平台中,以满足业务的需要,如与Volcano集成能更好的进行资源调度、基于Kubflow提供的Train-operator快速搭建起TF\Pytorch\MXNet等分布式训练能力,基于Kubernetes我们能在上层打造更贴合用户的功能,如训练机器创建与销毁,用户只填入简单的资源需求后台就能秒级的创建出一套用户所需要的新环境出来供使用者进行开发、测试、模型训练、模型发布上线等等。
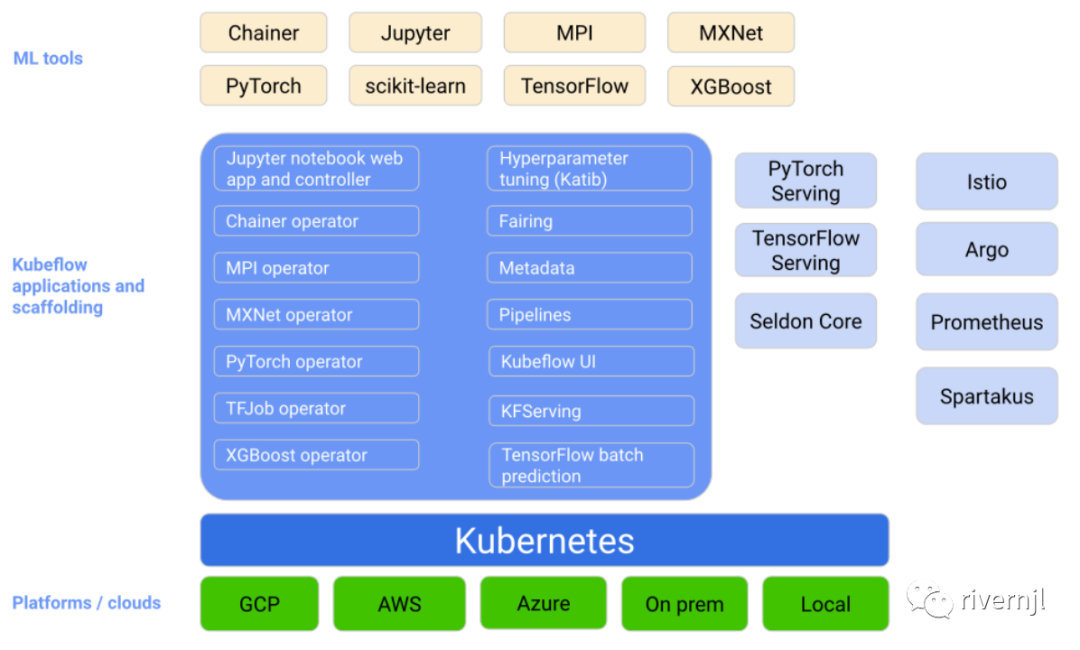
Kubeflow从架构上来说基本上能满足我们的需要,但是Kubeflow的对于使用者来说并不是那么的友好:
任务流构建使用复杂、需要通过python脚本构建任务、同时设置TASK运行过程中的参数复杂,比如磁盘挂载、资源配置等等,使用成本比较高
缺少环境开发相关组件,比如用户自定义的开发环境的开发工具等等
无法集成除Kubeflow支持以外的组件,比如集成Spark/Ray/Volcano,还比如对GPU虚化后无法应用到平台当中去
无法按分组进行资源调度管理,比如按线上机器集群进行资源调度,按训练集群进行资源调度、按项目分组进行资源调度等等
最终我们选择以Kubeflow做为平台的基础,在Kubeflow的上层我们进行层装及扩展,打造公司级的机器学习平台
新一代基于云原生的机器学习平台架构
最终我们选择的系统框架如下图
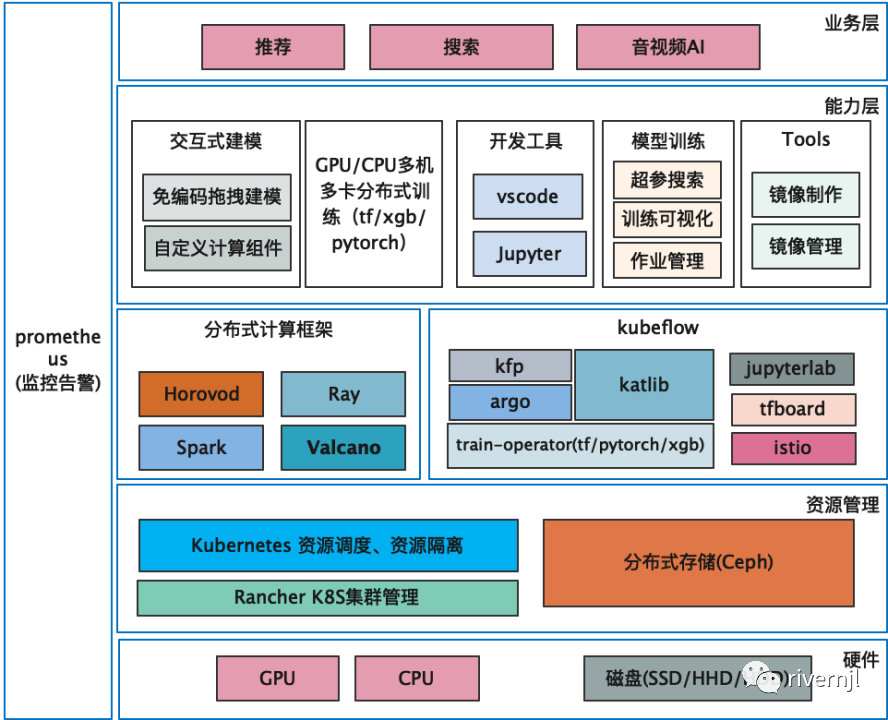
资源管理层
硬件层主要是实机机器上的资源,比如磁盘、GPU\CPU等等资源管理主要是利用Kubernetes进管理集群的资源,在存储方面选择使用Ceph来管理集群中的存储资源
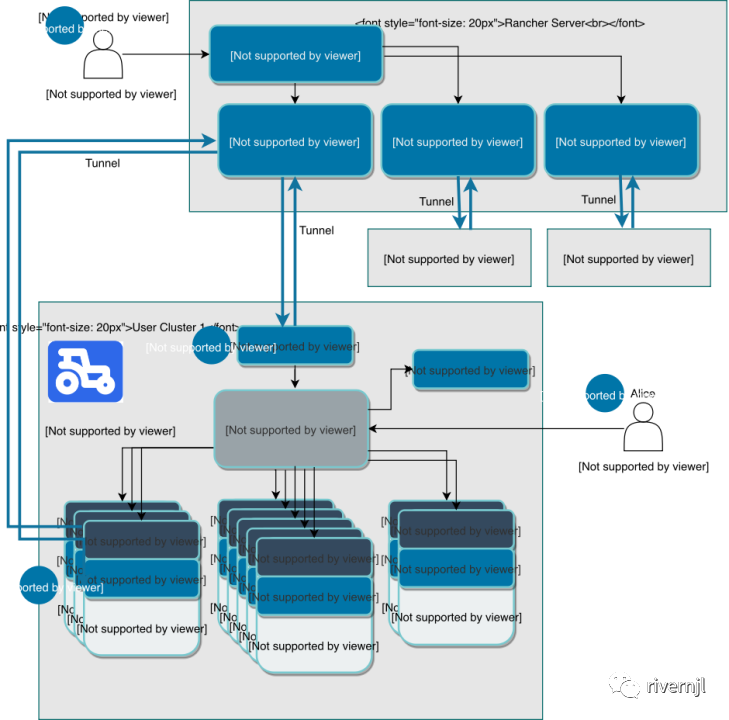
Rancher :
为了降低kubernetes的安装及维护的复杂度,我们基于Rancher来搭建及管理K8S集群。
Rancher不仅可以集中管理部署在任何基础设施上的Kubernetes集群,还可以实行统一的集中式身份验证和访问控制。由于无法确定资源运行的位置,我们可以轻松地在不同的基础设施之间调用集群,并在它们之间进行资源迁移,同时更方便于K8S集群的扩容、升级、运维等等。Rancher 中文官网地址:https://docs.rancher.cn/docs/rancher2.5/overview/_index
Ceph:
其实选择Ceph并没有太多的逻辑,ceph的读写性能并不高,大概只有50M-60M/秒,相对于Cfs等等性能还是比较差,在立项前期发现Ceph在k8s中安装比较方便简单,能很快的集成到系统中来,还有就是Ceph通过系统挂载后,用户能像访问本地文件系统一样访问Ceph集群上的文件,使用起来也方便简单,当时只是考虑利用Ceph来放置训练任务中的配置文件及需要执行的代码,这样分布式下进行训练会变得更简单方便,训练数据可以放置在HDFS等等之类的存储集群上,这样50M-60M/秒写性能完全能满足需求。
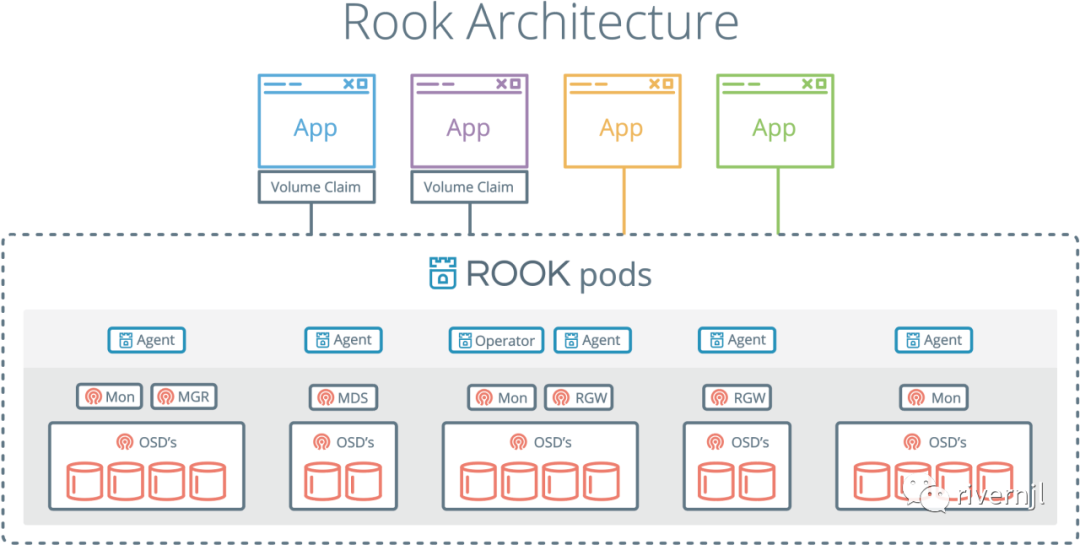
kubeflow
kubeflow中我们主要使用到了kfp/argo/katib/train-operator/tf-board等组件,istio后期需要从kubeflow 中进行剥离,单独进行独立部署
Argo:
Argo是一个开源原生容器工作流引擎 用于在Kubernetes上开发和运行应用程序。Argo Workflow流程引擎,可以编排容器流程来执行业务逻辑
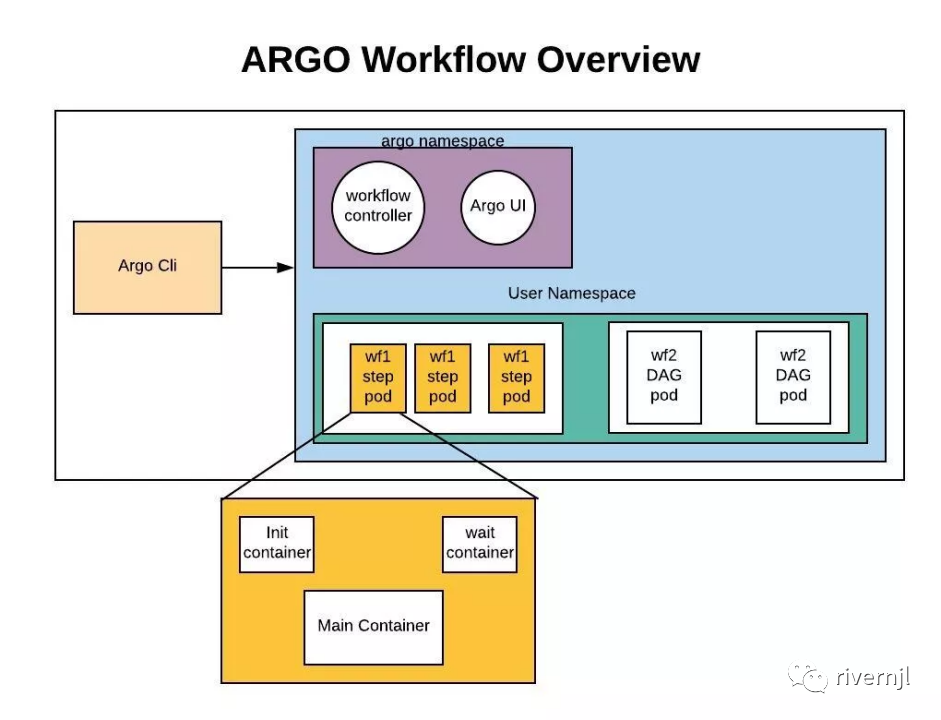
KFP:
Argo 已经有了一整套任务流处理流程了,KubeFlow为什么还要在argo上进行再次开发呢?首先就是Argo中的数据都是保存在ETCD中的,但是ECTD中的数据有大小的限制,数据总大小及每条记录大小在ETCD中都是有限制的,但是像流程模板,历史执行记录,这些大量的信息很明显需要一个持久化层(数据库)来记录,明显ECTD是不能满足需求的,这样就需要对这些功能进行增强,同是在ML的领域的用户界面层,KFP也做了较多的用户体验改进。包括可以查看每一步的训练输出结果,直接通过UI进行可视化的图形展示
未完待续
