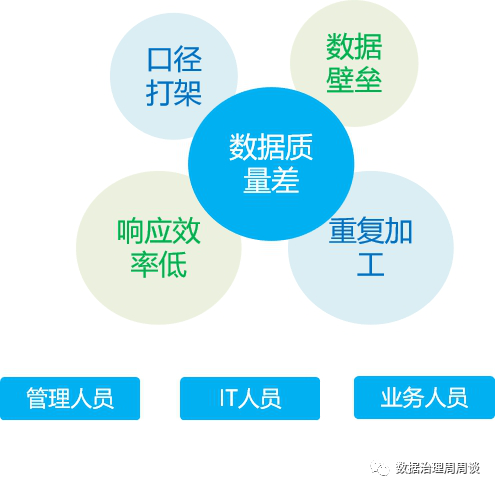
在没有数据指标体系之前,往往由业务人员作为指标的提出方和使用方,同时成为指标的管理方。但由于业务不同条线之间的不互通和对指标管理缺乏整体概念,往往导致以下各类问题层出不穷。
在数字化转型的背景下,需要不断缩短数据供应和数据应用之间的距离,让每一个业务人员都能自主使用数据。而指标体系正是连接基础数据和数据应用之间的桥梁,它可以随着业务扩展而同步,随着应用建设逐步完善,统一数据业务口径,不但提升业务数据服务准确性,而且从被动服务变成主动服务,实现数出同源、人人用数的目标。
标签是根据业务场景需求,通过对目标对象(含静态、动态特性)运用抽象、归纳、推理等算法得到的高度精炼的特征标识,用于差异化管理和决策。由此可见标签是体现目标对象特征的标识,往往集中在客户、产品等具有营销价值的目标对象上,且不局限于描述数量特征,还包括属性特征等。而指标描述的是目标对象的数量特征,是能表征企业某一业务活动中业务状况的数值指示器,对可描述目标对象范围更广。
现有指标是企业数据资产的重要组成部分,是企业级指标体系建设过程中必须要考虑的部分。目前指标分散在各个系统中,用户很难知道这些指标的含义、口径、应用场景,这样的指标很难满足用户数据分析的要求。在盘点的过程中,需要明确指标的名称、业务含义、业务口径、应用场景、主管部门、创建日期、最近更新日期、来源、权限等信息。考虑大部分指标存在于分析管理类系统中,因此可以考虑先从这类系统入手。盘点结果需要及时导入数据治理平台,使用指标应用工具,实现“可搜索、可分析”。当指标应用工具可以满足业务需求的场景下,完全不需要总行开发,直接在指标应用工具中实现需求。
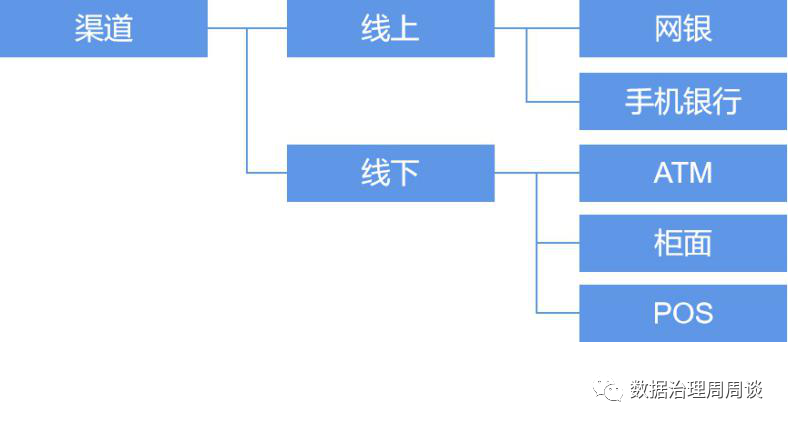
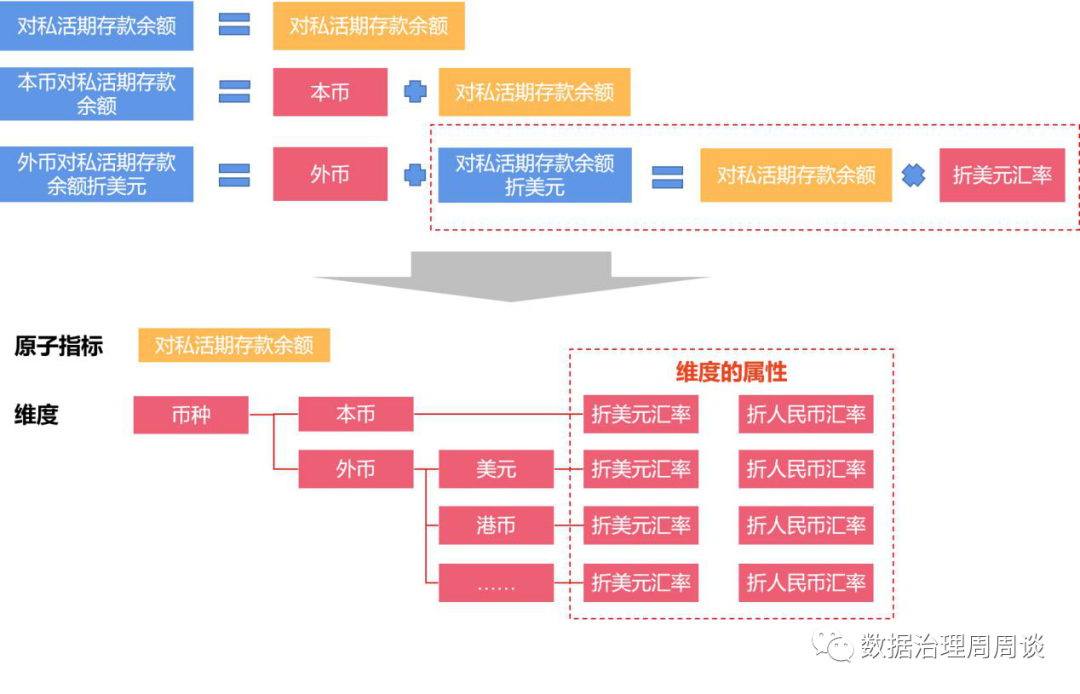
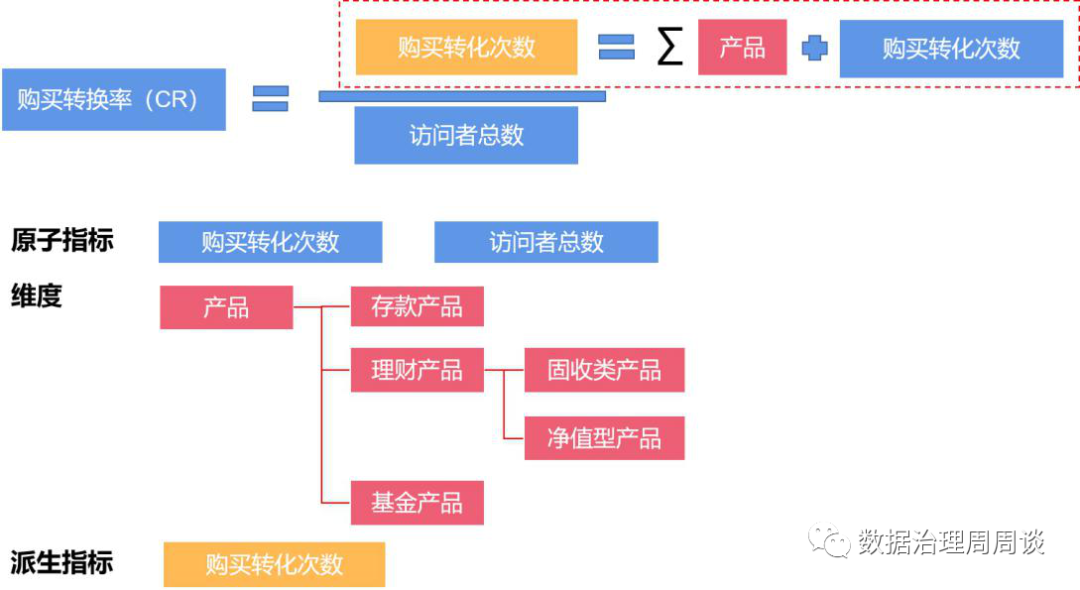
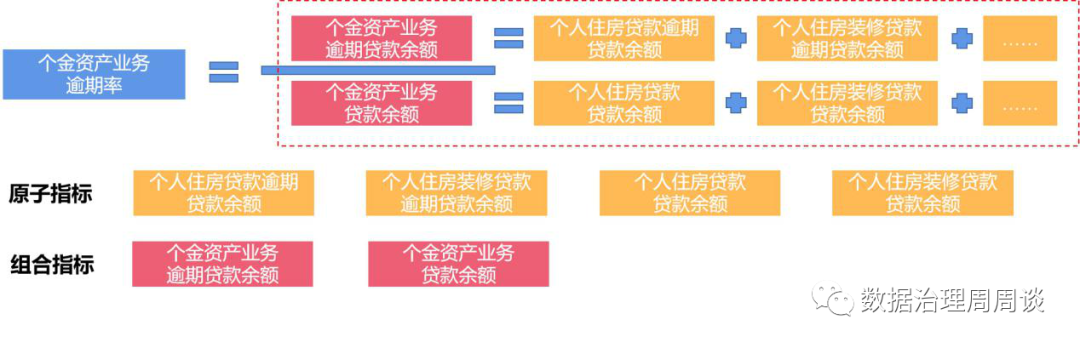
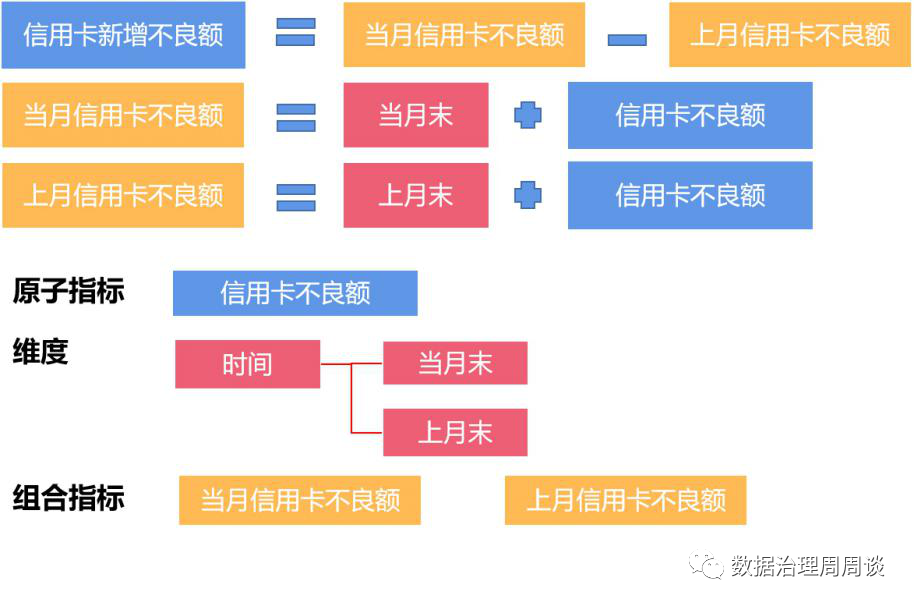
指标是衡量目标总体特征的统计数值,一般由指标名称和指标数值两部分组成。指标名称及其含义体现了指标在质的规定性和量的规定性两个方面的特点;指标数值反映了指标在具体时间、地域、条件下的数量表现。根据指标计算逻辑,可以将指标分为原子指标、派生指标、组合指标三种类型。维度是人们观察事物的角度,可以反映业务的一类属性,这类属性构成一个维度。一般常用的维度包括时间维度、渠道维度、地域维度等。当原子指标加上维度后,便可以形成派生指标,相当于某一维度上限定了一个值,则形成原有数据的一个切片,如果对多个维度进行限定,每个维度限定为一组取值范围,则是原有数据的一个切块。 从上表我们可以发现维度是有层次结构的,可以认为它是一个树形结构,它具有自下而上收敛或自上而下分解的特点。在建立符合企业自身情况的指标标准时,需要根据指标盘点的结果,对现有指标进行分解,得到目前业务场景涉及到的所有原子指标与维度,以此作为最基础的指标标准。有了基础指标标准后,随着业务的不断开展,势必会有新的指标需求不断出现,因此建议在需求环节增加对指标的管控。首先,业务部门提交的需求说明书中应包含专门的数据需求章节,数据需求章节需包括以下内容:
从上表我们可以发现维度是有层次结构的,可以认为它是一个树形结构,它具有自下而上收敛或自上而下分解的特点。在建立符合企业自身情况的指标标准时,需要根据指标盘点的结果,对现有指标进行分解,得到目前业务场景涉及到的所有原子指标与维度,以此作为最基础的指标标准。有了基础指标标准后,随着业务的不断开展,势必会有新的指标需求不断出现,因此建议在需求环节增加对指标的管控。首先,业务部门提交的需求说明书中应包含专门的数据需求章节,数据需求章节需包括以下内容:| 中文名称 | 业务定义 | 业务规则 | 主管部门 | 更新周期 |
| …… | …… | …… | …… | …… |
(2)补充要求,包括:历史数据保留要求、数据时效性要求、数据安全要求、数据质量校验等内容。
(3)需求原因:业务优化,专项整改(例如业务优化,专项整改(例如EAST问题整改、人行基础信息报送等)等。
其次,在需求分配环节区分出需求类型,涉及指标变更或新增的需求必须提交指标管理团队进行分析,协同业务部门与技术部门,对指标进行标准化,最终纳入指标资产统一管理。
由此可见,指标体系建设是一个循序渐进、不断完善的过程,是技术手段与管理手段相互协作的产物。
传统的建模工具主要是面向设计,而新一代的建模工具将数据治理理念融入其中,把数据治理流程推进到开发流程中,从而在开发态的源头进行治理,解决了指标标准落地的问题,可以从根本控制增量的数据问题。建模工具与数据标准、指标标准进行融合,在建模的时候可在线查询、智能推荐,提高标准的覆盖率,提升模型质量,又一定程度减轻了模型设计的工作量。
前面我们提到指标由指标名称和指标数值两部分组成,因此当指标上线后,需要对指标数值进行监控。指标监控有两种,一种是基于风控要求,当指标出现异常波动,超出合理的阈值时的监控和预警,另一种是为了检查指标数值的准确性进行的监控,本文主要说的是第二种。对指标缺失率进行统计,对于缺失率过高的指标,需要确认是开发引起的还是口径有误,因为过高的缺失率说明有部分信息缺失,影响后续数据分析结果的可靠性和稳定性。所谓倾斜率是指指标数值的结果相对集中在某几个特定值或特定区间中,这种情况同样需要特别关注,因为如果指标数值是准确的,那么该指标的分析价值可能不大。异常值一般指处于特定范围之外的数值,当出现异常值的时候,需要对业务场景进行分析,它往往代表在业务发生的环节中出现了特殊情况。勾稽关系是指报表中有关数字之间存在的,可据以相互考察、核对的关系。例如总账的期末余额等于各分户账期末余额之和。勾稽关系检查是最常用的指标检查手段,可以最快发现数据质量问题,但是需要在指标需求中提供检查公式。
(欢迎大家加入知识星球获取更多资讯。)
我们的使命:普及数据管理知识、发展数据管理工程师行业、改变中国企业数据管理现状、提高企业数据资产管理能力、推动企业走进大数据时代。
我们的愿景:凝聚行业力量、打造数据工程师全链条平台,培养不同层级数据工程师人才、构建数据工程师生态圈。
我们的价值观:分享数据管理知识,持续提升数据管理和运营能力。
了解更多精彩内容
长按,识别二维码,关注我们吧!
数据工程师
微信号:sjgcs
构建数据工程师生态圈