




也是上一篇的SQL改成not exist 把SQL秒杀, 还是此SQL
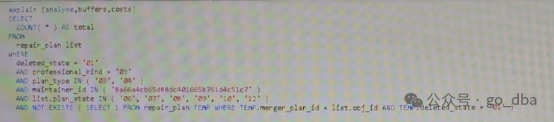
SELECT COUNT(*) AS total FROM repxxx_plan listWHERE deleted_state = '01' AND professional_kind = '02'AND plan_type IN ('03', '04')AND city_org_id IN ('16810251XXXXC6DCE050E60A50273290')AND list.plan_state IN ('06', '07', '08', '09', '10', '12')and not exists ( select 1 from repxxx_plan TEMPwhere TEMP.merger_plan_id = list.obj_idAND TEMP.deleted_state = '01' )
又再次恶化到10S。我记得上次优化该SQL还是在上次,让现场反馈执行计划:
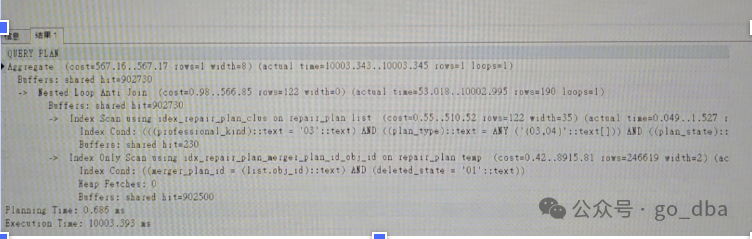
看到的是 Nested loop 的执行计划,但是他的第二个子节点集中了绝大数成本, 熟悉NL执行计划的都知道, 这个表示循环执行, 其执行方式只能是 索引唯一扫描,或者索引范围扫描。最忌讳全表扫描,也忌讳索引全扫描 熟悉oracle执行计划的都知道类似 index fast full scan 这边最值得怀疑的。那么查询index 结构。
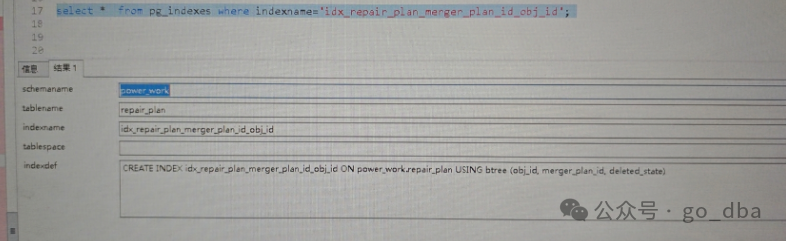
果然发现其引导列不是 merger_plan_id。
优化方案:
CREATE INDEX idx_repair_plan_merger_plan id_del ON power.work.repxxx_plan USING ( merger_plan id, deleted_state)
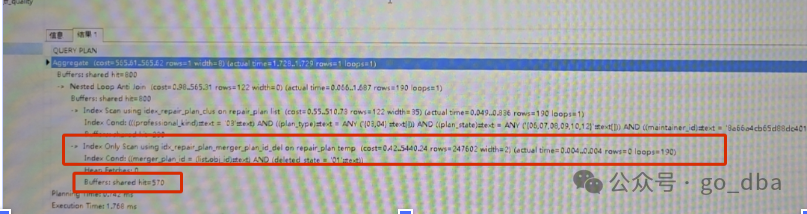
当时预期是秒杀的。果然1.7ms
文章转载自godba,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
