




几年前AHBA的基因表达数据在neuroimaging领域开始火起来,简单来说就是发现显著的brain pattern后和AHBA的基因表达数据做下相关。
开始有类似candidate gene的玩法,选一个基因和brain map做相关。这里的问题在于从2万多个基因表达中可能随便选一个都和brain pattern相关,怎么证明选的candidate gene的相关就是真的相关呢。如果审稿人不了解AHBA的话,可能不会要求做Null模型。就这样选一个基因表达和brain做相关的研究2020年了还在发。有的研究仍然在用alleninf这个2014年开发,基于python2.7的工具做分析,有点落伍了。

随后的玩法就更高级一点了,就是用一组brain phenotype和所有的基因表达做PLSR,找到一组基因和brain phenotype相关。进一步做基因富集等分析就是生信中的常规操作了,常规到只需要把显著的基因粘贴到网页里就出结果的程度。

2021年5月的这一篇Nature Communications的文章,探讨了基因表达数据和大脑模式做相关之后富集分析假阳性的问题,并提出了解决的方案和基于matlab的工具包。作者都是领域的专家,参考文献大部分都是使用AHBA的高质量的文章。
文章做了以下几件事情:
1. 简要的说明了常规的套路
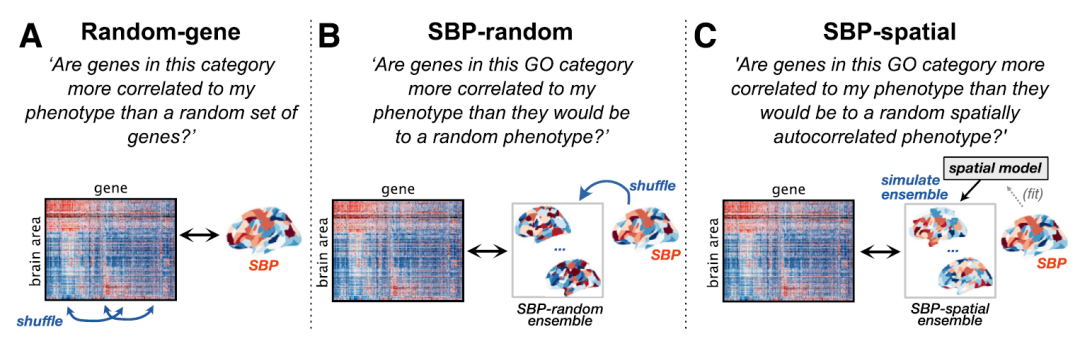
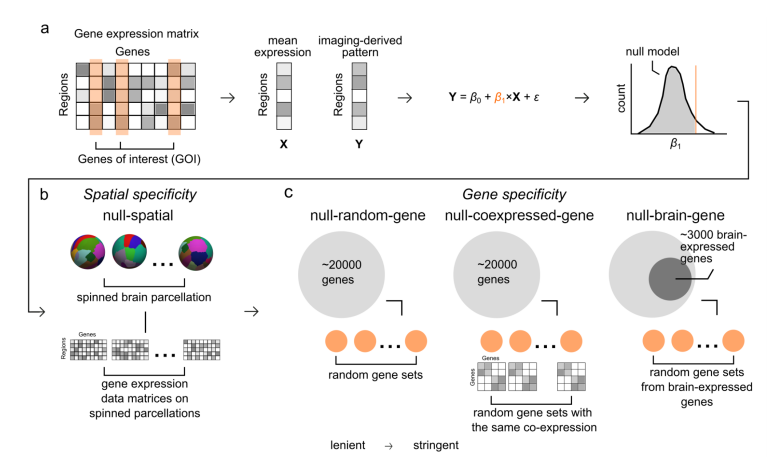
如👇图(A),先找brain phenotype,它可以是各种模态,功能连接,条件间的差异,病人和正常人的差异,然后和基因表达的模式做相关,对基因做富集分析。
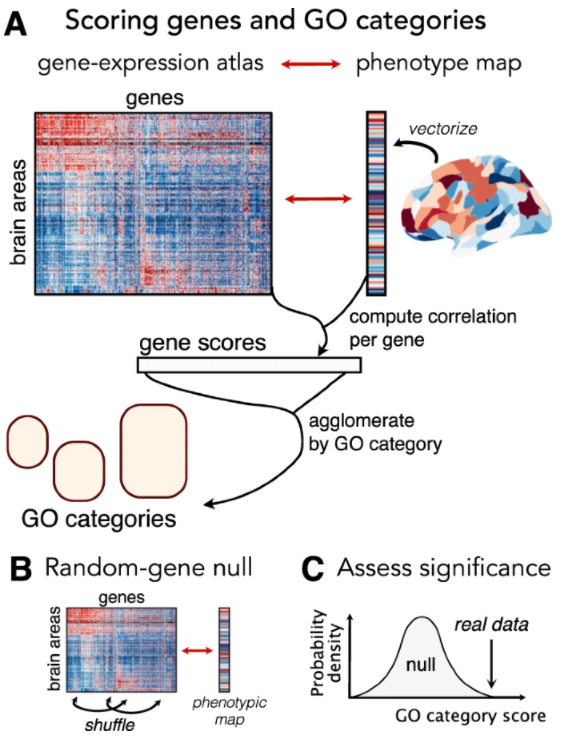
注意⚠:文章中讨论的富集算法是Gene score resampling (GSR),和另外一种常用Over-representation analysis (ORA) 是有区别的。GSR做富集,计算每个基因分数,然后计算每个GO类别的分数。显著性看GO类别内的分数是否显著高于Null模型的分数,原理相当于👆图(B/C)的表示的Random-gene Null模型。
ORA基于前景基因和背景基因富集到某一GO类别的比例是否存在显著性差异。假设有10个前景基因【找到和brain phenotype显著相关的基因,这里需要自己确定阈值和矫正的方法】,其中有4个都归类到某一GO term中或者落在某一通路中(pathway);而在整个基因组中(假设为100个,背景基因)有30个都对应该GO term中或者落在该通路中(pathway)中。4/10与30/100间是否有统计学差异,即待测功能集在基因列表中是否显著富集。
常用的enrichr,David和clusterprofile应该都是ORA。enrichr提供了一站式的解决方案,网页输入显著基因名就行,除了GO还有很多的anotation可以做。David所有人都在提,只不过GO的数据库似乎已经停滞在了2016年。Y老爷的clusterProfiler基于R,既然需要写点代码,自然灵活性会高很多。
enrichr结果

clusterProfiler结果
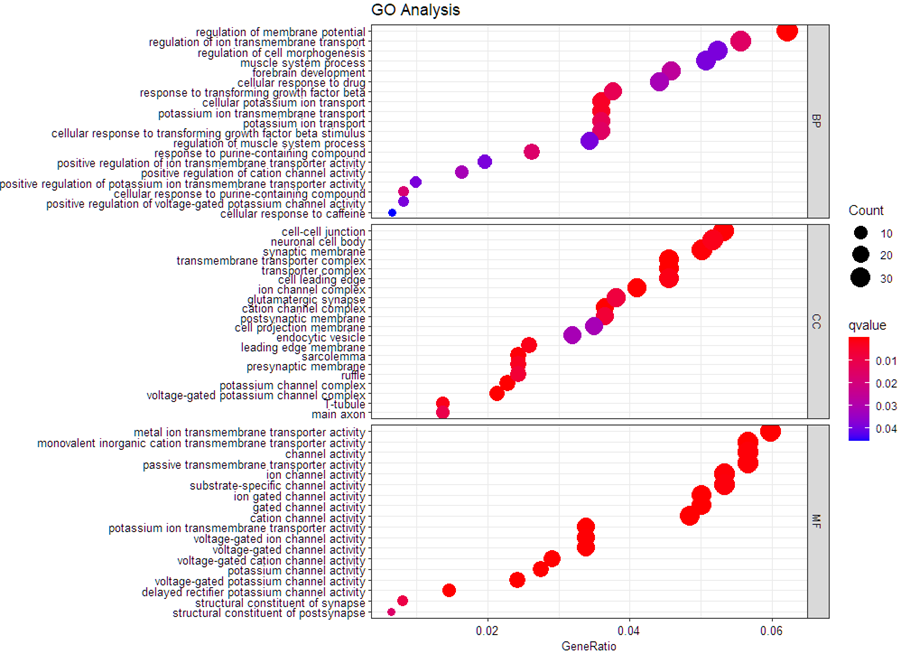
GSR做富集分析不需要设定阈值选择用哪些基因做前景基因,每个基因的信息都会被考虑在富集分析中,相比ORA可以保留更多的信息。实际使用中GSR和ORA两种方式的结果都会得到类似的结果,GSR会更稳健。
2. 简单综述之前的文章
发现不同的brain phenotype都富集到了GO的几个生物过程的类别中,
chemical synaptic transmission
potassium ion transmembrane transport
learning or memory
electron transport chain
这几个过程看起来可以和任何brain phenotype都能扯上关系,那么是不是在做富集分析时产生的偏差呢?
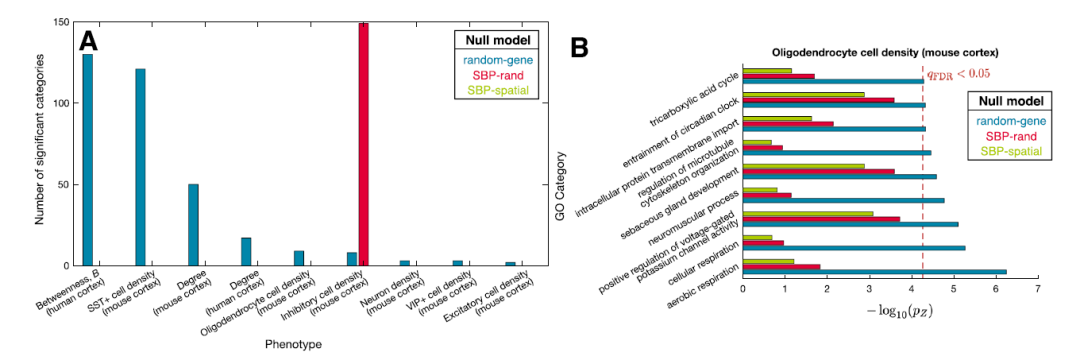
3. 量化不同Null模型的假阳性
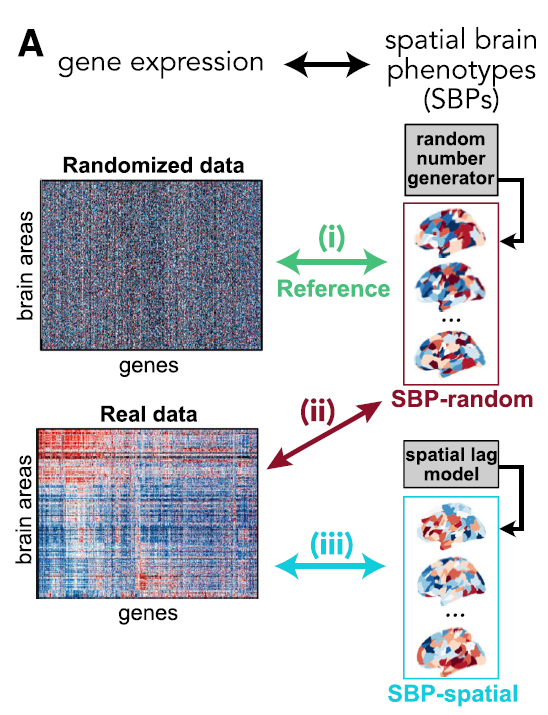
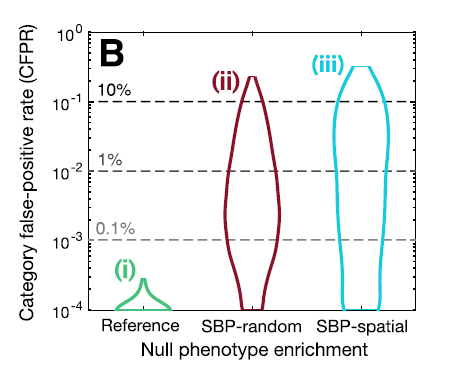
图A(ii)-SBP-random,如果所谓的brain phenotype是完全随机的,那么做富集分析发现显著的GO类别就是假阳性的,这样的随机实验做10000次,计算每个GO类别的假阳率 (category false-positive rate: CFPR)。如果富集分析是无偏差的,SBP-random结果可能是所有的GO类别都有相似的CFPR,需要有一个参照标准。
图A(i)-reference, 在SBP-random的基础上打乱基因的标签,这样破坏了基因-基因之间的coexpression。
图A(iii)-SBP-spatial,使用的是spatial lag模型对brain phenotype做permutation,进一步加入了空间自相关的信息。一个类似于spatial lag模型的方法是spin test👇,这类方法旨在保留最多的空间自相关信息。
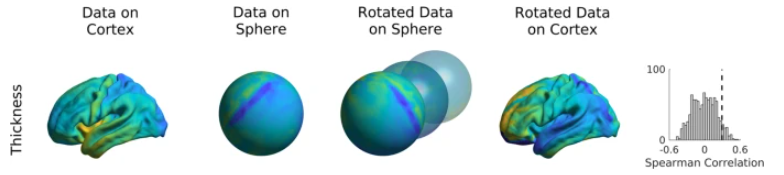
结果表明,👇图(B)几种Null模型的结果表明SBP-random和SBP-spatial相比reference都有更高的CFPR。注意⚠:这里指的是几种方法建立Null模型的表现,也就是说在Null模型中考虑尽可能多的混淆因素(CFPR越多越好),才能降低True模型中的假阳性。
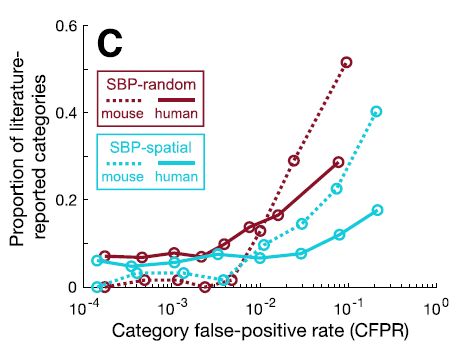
而且之前研究报告的GO类别和CFPR是有关系的(C),也就是那些有更高的CFPR也出现在之前研究的结果中。
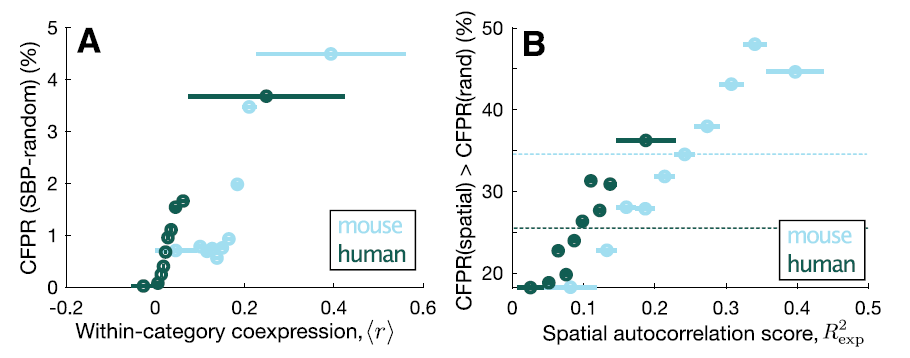
4. GO类别内的基因coexpression和空间自相关是假阳性偏差的主要原因。
A. 把类别内的基因之间的相关做平均,发现和SBP-random的CFPR相关。
B. 计算空间自相关得分,发现和CFPR(spatial)>CFPR(rand)相关。
如果建立Null模型的时候,没有考虑这两点的话,有可能提高富集分析的假阳性。
5. 小结几种建立Null模型的方式。
使用C SBP-spatial模型,随机brain phenotype并保留它们的空间自相关,这样在Null模型中,可以保留了空间自相关和GO类别内的基因coexpression的信息,从而降低True模型的假阳性。
6. 实际使用的效果
最后运用到了实际的数据分析中,对比几种方式的差异。
本文的作者关注的是富集分析中类别的假阳性问题,类似的讨论还有直接关注基因表达和脑数据相关的。

思考题
如果在基因和脑数据的相关时,就用SBP-spatial的方式建立Null模型寻找显著相关的基因,之后对显著相关的基因用ORA的方法做富集分析还会有假阳性偏差的问题吗?


