





LME中的random effects经常用于解决longitudinal数据中intra-visit的相关。同时,在combat没有在imaging数据上普及之前,它也经常用于处理多中心(site)问题。LME用的是迭代的算法(iterative algorithms),运行效率低,而且常常遇到无法收敛的问题。
另一个方面,确定LME的random effect也很复杂,用random slopes还是random intercepts,还是同时使用。如果在longitudinal的设计中还有site的时候,是否需要使用嵌套的random effect?一些样本除了有site,还有race/family ID需要控制,是不是都要加成random effect?结果往往是设置过于复杂的random effect,模型根本无法运行。因此大部分的fMRI分析只考虑了random intercept的情况,也就是最常用的 (1| site)或者(1| subid)。
相对于传统的LME模型,Marginal model只估计模型中的fixed effect,使用sandwich estimator处理family/race/site等带来的方差不一致问题,不会有收敛问题,能绕过permutation。不关注这些应该加为random effect的变量,意味着它只做population level的inference和prediction。
比如两个被试来自于同一个家庭,有同样的family ID,用LME做permutation的时候有可能需要考虑将family ID作为一个约束条件。样本越大,类似的约束条件就可能越多,使得permutation的成本升高。
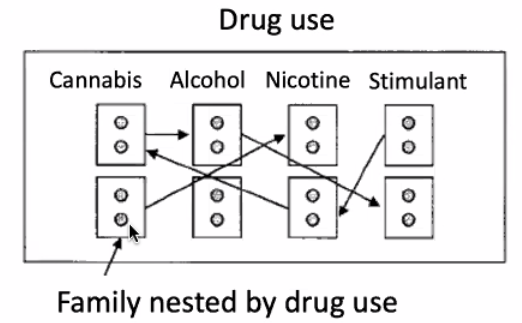
除此之外,permutation消耗大量时间和计算资源,大概2600被试的1000次voxel-wise permutation在1000核的HPC上大概需要2天。如果是ABCD或者UKB这样的样本,时间会更长。
Marginal Model步骤
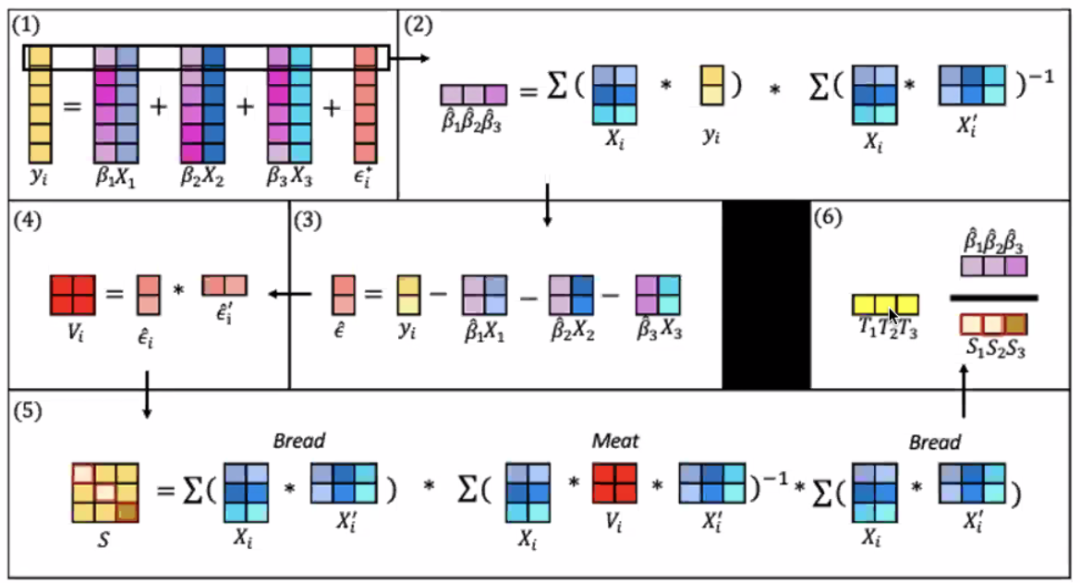
(1) 只有fixed effect的多元线性回归
(2) 向量化求解beta
(3) 求残差
(4) 残差求协方差矩阵
(5) sandwich estimator获得beta的se的估计值
(6) 标准化beta得到t统计量
(7)对于统计的显著性,可使用wild bootstrap的方法建立null模型(无需进行permutation),原理是随机化误差项。
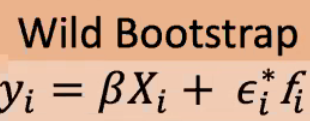
经典假设下方差同质且不相关(如下图左),而这里使用实际获得的残差做协方差矩阵,计算beta估计量的标准误。
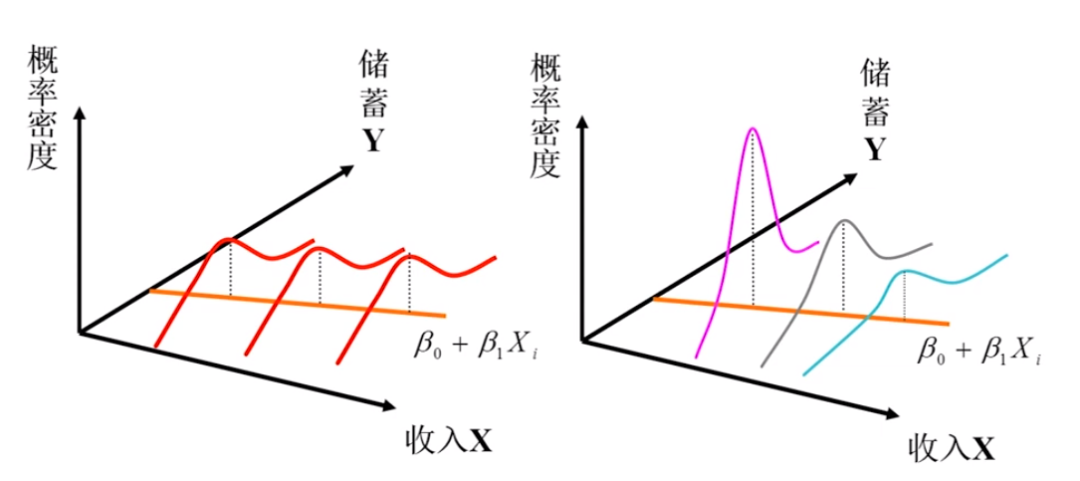
OLS经典假设,无异方差的情况下:
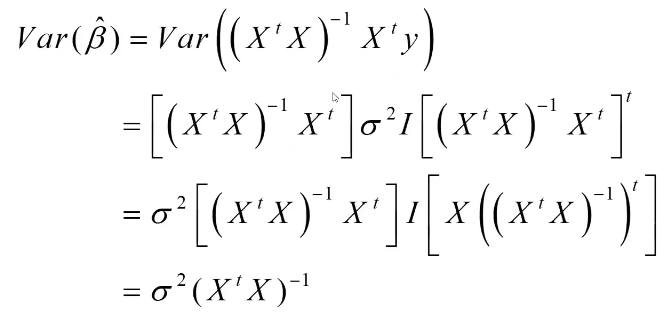
异方差存在时,每个观测残值都有自己的方差:
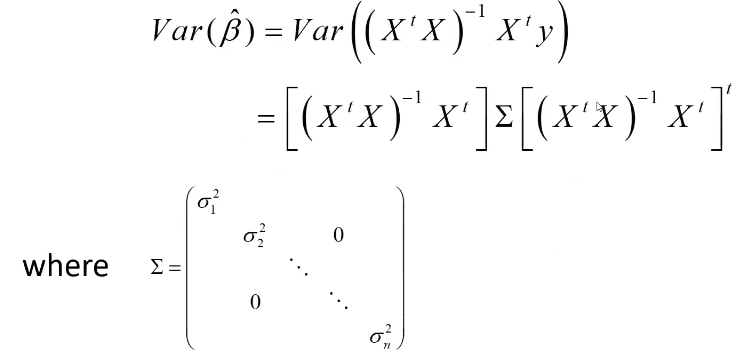
使用实际值计算残差,随后即可获得残差的协方差矩阵Σ,从而进一步计算beta估计值的t统计量。
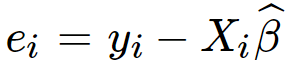
sandwich estimator是从形式上的命名,两片面包🍞夹一块肉🥩。这个名称让方法和食物建立起联系。显然sandwich estimator比marginal model更吸引人,便于传播。当然对某些只吃open sandwich的人来说可能并不是那么直观。应该是👇这篇文章首次提出将sandwich estimator用于neuroimaging数据,他们也做了toolbox,后面会提。
Guillaume, B., Hua, X., Thompson, P. M., Waldorp, L., Nichols, T. E., & Alzheimer's Disease Neuroimaging Initiative. (2014). Fast and accurate modeling of longitudinal and repeated measures neuroimaging data. NeuroImage, 94, 287-302.
从不同的角度命名,它还有一些不一样的称呼。比如,Robust estimator,稳健是指统计方法能够搞定异常值或者一些违法统计假设的情况。Huber/White estimator,以提出者命名,作为一种处理异方差的方法,更多的时候被称之为White矫正。Empirical variance estimator,这个名称表明该方法基于实际的残差,对协方差矩阵进行估计。与之相对的是model based的算法。
两个软件可以实现fMRI的相关分析
1. 基于matlab的SwE

2. 基于R的MarginalModelCifti

3. 基于R的sandwich: Robust Covariance Matrix Estimators
一个比较general的工具,附一份简易教程👇可以更好理解sandwich estimator。
原文地址:
https://thestatsgeek.com/2014/02/14/the-robust-sandwich-variance-estimator-for-linear-regression-using-r/
生成数据,每个观测值y都有不同的residual sd,不符合OSL假设:
set.seed(194812)
n <- 100
x <- rnorm(n)
residual_sd <- exp(x)y <- 2*x + residual_sd*rnorm(n)
plot(x,y)
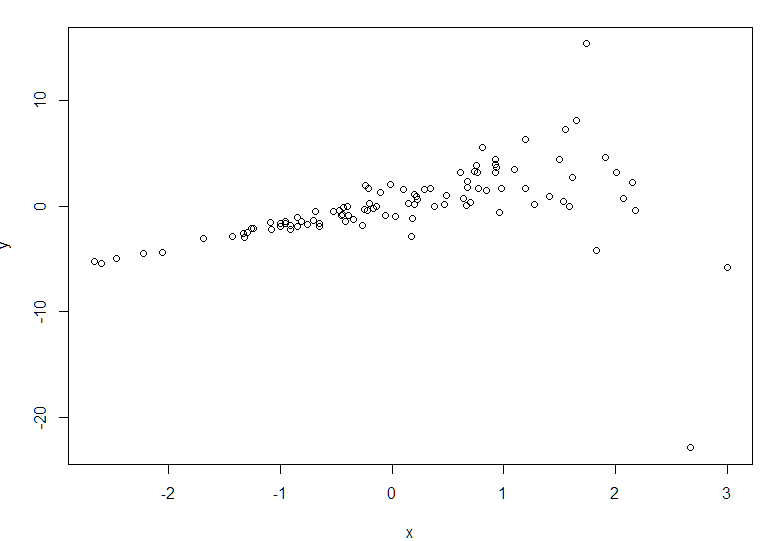
常规LM模型
> mod<- lm(y~x)
> summary(mod)
Call:
lm(formula = y ~ x)
Residuals:
Min 1Q Median 3Q Max
-25.9503 -0.8574 -0.1751 0.9809 13.4015
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.08757 0.36229 -0.242 0.809508
x 1.18069 0.31071 3.800 0.000251 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 3.605 on 98 degrees of freedom
Multiple R-squared: 0.1284, Adjusted R-squared: 0.1195
F-statistic: 14.44 on 1 and 98 DF, p-value: 0.0002512
注意正常LM模型,得到的x系数的se是0.311,p=0.00251
使用sandwich估计协方差矩阵
> library(sandwich)
> vcovHC(mod, type = "HC")
(Intercept) x
(Intercept) 0.08824454 0.1465642
x 0.14656421 0.3414185
对对角线上的元素开方,计算标准误
> sandwich_se <- diag(vcovHC(mod, type = "HC"))^0.5
> sandwich_se
(Intercept) x
0.2970598 0.5843103
因为异方差的存在,这里算出来的x系数的se为0.584
计算置信区间:
> coef(mod)-1.96*sandwich_se
(Intercept) x
-0.66980780 0.03544496
> coef(mod)+1.96*sandwich_se
(Intercept) x
0.4946667 2.3259412
计算p值
> z_stat <- coef(mod)/sandwich_se
> p_values <- pchisq(z_stat^2, 1, lower.tail=FALSE)
> p_values
(Intercept) x
0.76815365 0.04331485
可以看到x和y相关的证据强度从0.00025下降到了0.04。
至于异方差的内容,比如它的影响是什么,它的检测方法有哪几种,它的矫正方法有哪几种,基本都是教科书内容,网上资料很多。此外,完全可以基于该例子扩展一个多元回归+不同site有不同截距的数据,比较一下LME和sandwich estimator的结果。

一句话总结,如果不想使用LME+permutation,也许sandwich estimator是一个不错的选择。

以下是教科书上一部分相关的内容
不全面而且很无聊,可忽略
对于一个一元回归模型
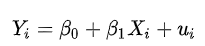
需要确定回归线位置,使得残差(模型预测值和真实值之间的误差)平方和最小
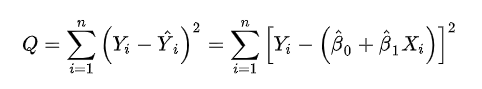
分别求偏导得到beta0和beta1的估计量
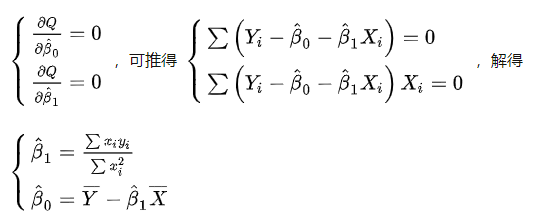
其中对于beta0求偏导的公式,正好是残差的公式,说明残差均值为0。
对于beta1求偏导的公式,残差和X的乘积为0,说明残差和X不相关。
对于一个多元回归模型
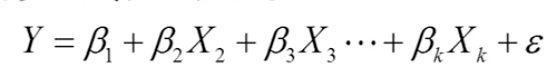
写成矩阵的形式:
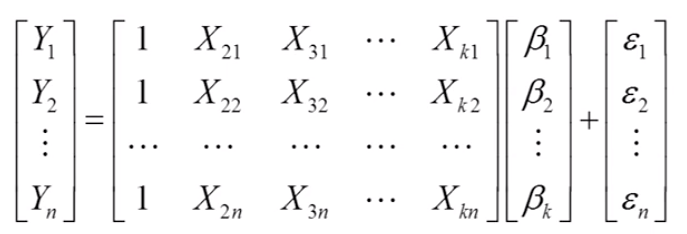
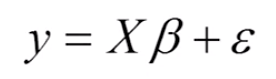
OLS原理:残差平方和最小
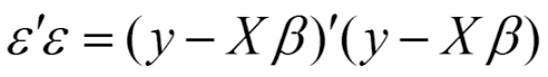
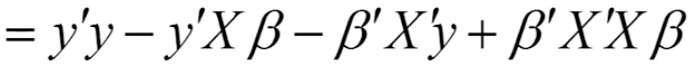
标量对列向量求导
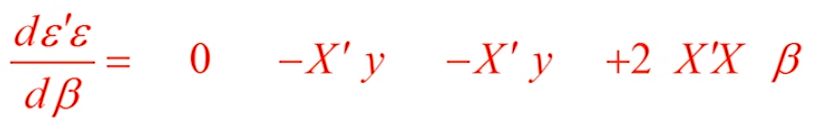
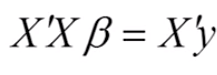
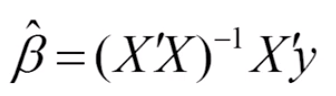
其中需要X列满秩(列线性独立)
=>OLS假设1:数据矩阵X列满秩
OLS估计量的性质
一致性:样本无穷大时趋近于总体的真实值。
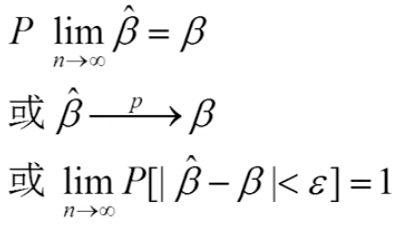
无偏性:样本参数估计是总体的参数无偏估计
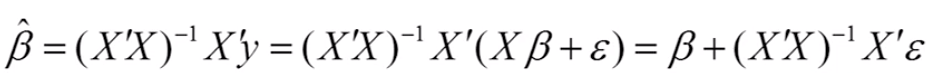
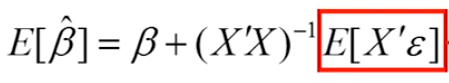
=>OLS假设2:随机误差项的总体均值为0
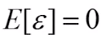
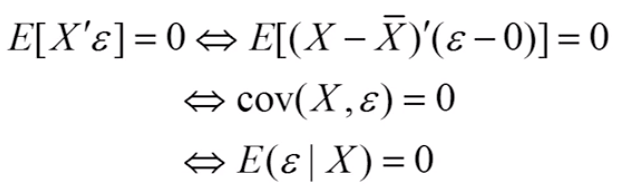
=>OLS假设3:随机误差项和解释变量不相关
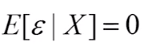
有效性(计算OLS估计量的方差)
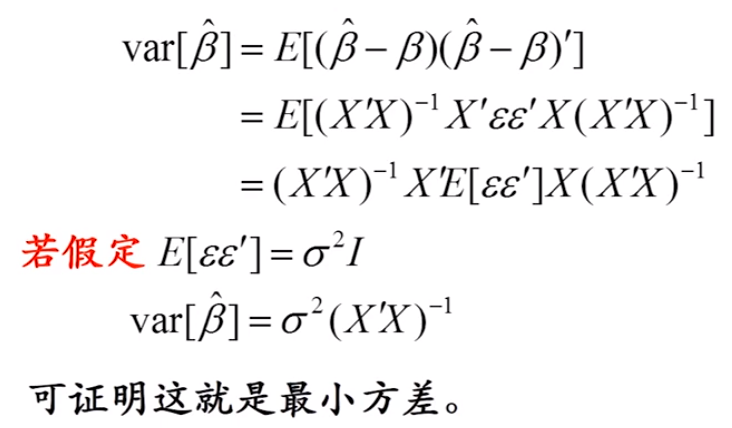
=>OLS假设4:随机误差项同方差且互不相关
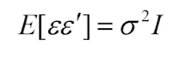
如何算beta的t值,p值,置信区间
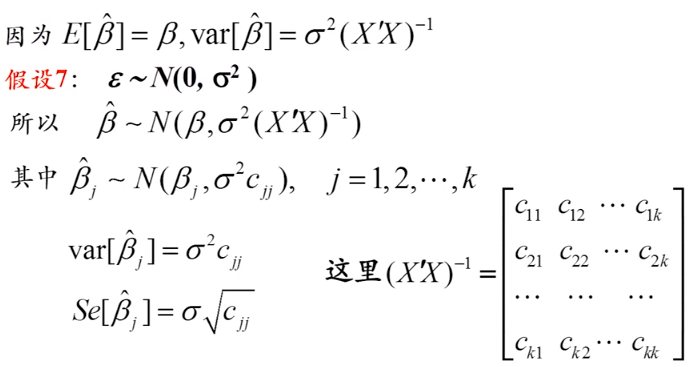
对于beta进行标准化(结果为t分布)

