





DBA守则第二条:有效的备份重于一切。这点是来自老的DBA守则,强调了“有效”两个字,备份一定要有效,可以用于恢复!关键时刻,如果没有有效的备份恢复数据库,就可以对职业生涯判死刑!这条就不多说了,重要性大家都懂。
DBA守则第三条:任何变更可以回退。能做到这点,你就可以立于不败之地!比如操作系统的rm –rf 命令,和这个类似危险的命令还有好几个,比如:
chmod –R 777 *
chown –R xxx:yyy *
mv * *
rmdev
执行不当,都有可能导致系统宕机和灾难,极难恢复。那我们采取怎样的策略防止出现问题呢?看下面的案例:
案例三:项目经理说,项目上线已经成功了,请把xxx路径的冷备删除。
也许很多人就直接把它删除了,反正项目经理让删除的!可是,难免有时候删错了,然后各有理由相互指责!我们希望培养和招聘这样的人:做事自己对自己负责,能坚持“可回退”原则,项目经理让删除的文件,自己先不真的删除这些文件:1)检查当前运行数据库所有文件不要在删除文件路径下;2)确认完第一步,把要删除的文件路径打包压缩,放在一个合适的空间里,保存几天,没人找你,再删除。
我们坚决拒绝纯净主义者,推崇小心谨慎,最怕那种有洁癖的DBA,登陆系统发现很多历史的备份或者貌似没用的文件,总觉得碍眼,哪天忍无可忍的清理掉,如果失误会是致命的!生产的东西能不动就不动!
下面来说说数据库的变更:各种数据库的变更中,有一种因为触发BUG而要打PATCH的问题,这也是一种变更,一种很有争议的变更。通常是DB出故障了,请第三方或者原厂的专家来分析,经常反馈你的库触发了BUG,所以请升级DB版本或者打PATCH!
1)往往这些BUG还不好在测试环境再现;所以你的系统是不是真的触发那个BUG不能100%保证的,第三方或原厂专家总是说的似是而非,有很大猜测的成分,总想打上试试,生产不是用来试错的呀!
2)PATCH打到生产上能不能真的解决你的故障,第三方或原厂专家也不会给你保证;
3)全局性的PATCH打到DB上,会不会引起更大的其他问题,比如执行计划混乱,数据一致性出现问题,引发更大的BUG,第三方或原厂专家不保证不负责;
如果你全权负责管理一个7*24小时的在线系统,库的资产交易规模超过4000亿,上述三点都是必须要考虑的,多数技术专家只是告诉你要打PATCH解决某个似是而非的BUG,以期待能解决你的故障,而他却不做保证!我们尊敬技术专家的知识,但我们对生产也心存敬畏!
我们希望看到的是,一个故障发生了,即使触发了BUG,但是给的解决方案是一个有保证的方案,也是一个可以安全回退的方案。而不是专家的习惯建议升级到某某版本或者打某某PATCH,升级版本就不触发新的BUG了吗?显然不可能,新的版本永远有新的BUG,新的PATCH也带来新的BUG!
我管理的不重要的库,我也打过PATCH解决BUG,也用过隐含参数!但是在这六年对核心的管理中,任何的故障和BUG处理方案都没有打过PATCH,都坚持寻找最安全的方案,专家建议打的PATCH,我们都坚持拒绝!下面就是这样的一个案例,我们坚决不采用专家的意见,不打PATCH,开动脑筋想办法寻找方案。
案例四:银行核心RAC日结账宕机案例
刚接管核心的几年,我们竭尽所能对银行的核心做优化,每个人都像嗷嗷叫的小狼,都在寻找战机、寻找舞台进行表演,比如清理无用的历史数据,索引设计,优化SQL的执行计划,启用并行计算。事情已经做的很好了,还会不断思考怎样做的更好。比如银行日结账,其中一个过程需要对主帐户表中所有的客户的余额做一个重新计算,上千万客户,每个客户的余额都需要关联好几个表计算,曾把并行计算增加到30个进程,有明显的优化效果,开发负责人尝到了甜头,又上版本增加到40个并行,以便有更好的表现。
故障描述:核心在日结跑批时,RAC单节点宕机重启,日志可以看到,一个节点被RAC内部进程踢出!重启之后进程接续跑,日结跑批可以顺利完成。
首先oracle support在线求助,上传所有RAC日志,印度的RAC专家建议安装osw并再现这个故障,才能真正定位根本原因!我们拒绝生产环境安装osw,原本日结账压力就很大,这种监控只会增加服务器负担,容易引发其他的故障!
我们有一个内部分析问题的方法,出现故障后,追溯上一个版本是否和故障时段程序有关!正好在20多天前,新版本日结算并行度由30增加到40个!这个版本成了怀疑重点,我们决定不做改变继续观察。
之后每过20多天,RAC又出现单节点宕机重启!
两次请oracle原厂专家来看,不同的两个专家都认为是BUG造成了这个故障!建议打PATCH修复。因为专家们都说话留有余地,不保证一定解决故障,不保证不触发新的BUG。在会议室,我们和oracle原厂专家带了脾气的激烈争吵,我们无法采纳,无法接受专家的建议!
我认为几乎所有BUG都是业务SQL触发的,没有业务SQL就不会有宕机。可以打PATCH解决BUG问题,也可以改进业务SQL,让业务不触发BUG。就如大禹治水,可以疏导洪水,也可以堵住漏洞。这个问题明显是程序过度优化,并行度过高导致CPU消耗达到极限的极限,从而触发oracle程序漏洞,触发单节点重启。我一度提议回退这个优化版本,降低并行度。这个方案虽然很没有技术含量,但是修改最小,是有保障的的解决方案。但是开发主管不同意回退版本,这是他们今年的一个重要工作业绩,无论如何让我们再想想办法解决这个问题。回退并行版本是最后方案。
我们坚持寻找完美的方案,坚持寻找变更可以回退的方案,多方僵持不下,问题持续了半年,每20天都会重启一次,每次单节点重启后,都要争论。我们搭建了测试RAC环境反复测试无法再现这个BUG,也就不能验证PATCH是否能解决这个问题,那这个问题的完美方案是什么呢?
我们达成的共识:资源耗尽引发单节点重启。那能不能加点儿资源呢?向这个方向走走试试,最终加了1个cpu和16G内存,从此RAC单节点宕机重启问题完美解决,我想这个方案会是个完美的可以回退的方案^_^&^_^&^_^&!
最佳方案是如此的简单,这来自于对完美的不断追求,讨论中理念的不断碰撞。我觉得,就是坚持遵守“任何变更可以回退”这个守则,才有这样的解决方案。
这里,问题解决的技术原理,不再累述!
仅仅精通oracle技术,绝对不会是个好的DBA,也不会管理好数据库!我们要了解数据库每个时间预计在跑哪些业务,什么时候压力大,比如:
银行业务,压力大的时间段
每天零点日结;
每月最后一天月结账;
每月十号扣账户管理费;
每季度的最后一个月二十日结息日;
半年结;
年结;
这些时段都会是各家银行DB服务器压力最大的时候,不要再给服务器额外的压力,比如:DB层的操作、OS层的操作、新版本、主备切换和灾备演练,都要避开这些时间去做。可以名曰,做事需要选良辰择吉日,貌似有点儿迷信的,但会是很好的趋利避害的DB管理方式。
下面讲一个很经典的故障案例,爱八卦的同学,不要扒是哪家银行,咱们就当故事听听,重点体悟DBA守则。这么多年过去了,也应该是解封的时候了,各行都已经升级成两地三中心架构,应该不会再出现雷同故障,而唯一不变的是故障给我们的启示,一个隐瞒真正历史的团队是个没有总结的团队,没有进步的团队。先上图:
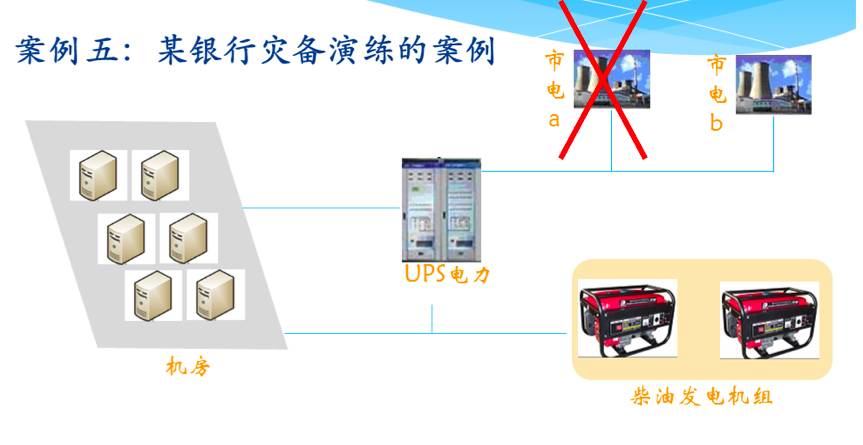
案例五:核心生产机房市电切换引发故障。
由于发现市内电压不稳定,银行计划做市电的切换,核心生产机房从A路市电切换到B路市电,操作前经历了领导的层层审批,执行时间竟然是季度的最后一个月的20日凌晨,正好是结息日,结息日,结息日!好吧,重要的事情说三遍,首先,时间选择上他们的领导层应该对此担责。
晚上零点所有银行都在繁忙的跑结息计算,对照我们行,凌晨跑批计算经历过千锤百炼的优化,平时跑1小时,那么结息日的跑批执行用时2.5小时,可见运算量之大!
他们的机房电管依据计划,凌晨2:00切换A路市电到B路市电,切换后没多久,他就惊讶的发现机房的柴油发电机组启动供电了,这哥儿们觉得应该是柴油发电机组坏了吧,乱启动发电,就关闭了柴油发电机组(无上报,擅自决定)。结果没多久柴油发电机组又运转起来供电了,好吧,大晚上的闹鬼辣吗?跟我过不去?接着关掉你。没多久,轰,偌大的机房无数服务器、存储、照明突然一下全黑了,我想如此壮观的景象会是这个电管兄弟一辈子最深刻最难忘的“独家”记忆吧!其实,那个B路市电是坏的,根本没电,UPS自动监测发现没有外部电力,通知启动柴油发电机供电。
金融行业的IT架构,可以叫超级IT架构,有非常强大的自纠错能力,一点儿都不怕任何单一的故障!所以在这种架构下的IT运维人员易生倦怠之心,所谓生于忧患之间,死于安乐之中!灾难并不可怕,怕的是做出错误的判断,引发另一场灾难,再一场灾难也不可怕,最可怕的是推倒多米诺骨牌引发一系列灾难。
这家银行,当年核心项目上线,在安装高端存储的时候,发现缓存层的电池安装后,无法充电使用。高端存储的数据直接写入cache缓存池不直接写入磁盘,这样才有高效的IO能力,之后缓慢的异步同步到磁盘里。如果突然断电,那么缓存池两个互备电池会保障cache层的数据足够的电力写入到磁盘,保障数据不丢失!而这两个电池无法充电进行保护,乙方建议升级电池微码也许能解决这个问题,但不保证一定能解决!甲方和乙方为此发生了争吵,乙方甚至群发邮件给甲方所有相关人,说明电池问题,但是迟迟未能达成一致解决这个问题。所以甲方从上到下所有的人都知道,这个高端存储的电池就如“花瓶”般搁在存储上的,不可使用,只能观赏!
机房大停电,高端存储cache缓存数据全部丢失!
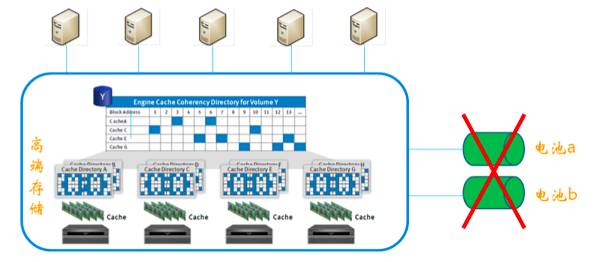
领导同意在结息日作切换,切换前未检查B路市电是否有电,柴油发电机组被人为关闭,核心存储cache层互备电池是“花瓶”,在结息日最大的批量运算都写入cache的时候,断电了!多个数据库的数据全部丢失(核心,支付,网银,ATM等重要系统),数据恢复后需要重新结息日批量计算!据说oracle原厂很多专家都参加了救援,所有人一起奋战三天三夜解决这个重大事件。这是我这六年来知道的银行业最严重的灾难事故,没有之一。
造成的影响
XX银行由于系统故障,中断营业9个小时。
柜台无法办理业务,导致营业厅排队骚乱。
支付、网银、ATM等重要业务无法使用,造成极大的不良影响与客户抱怨、投诉。对公信贷彻底无法恢复,账目丢失,面临大量索赔!
媒体大量刻薄的符合事实和不合事实的报道,声誉形象严重受损。
我依据和运维交流、媒体报道、同等数据规模来估算以下数据:
2:30大停电,IT相关人全部抵达现场并查明情况,精锐力量优先恢复核心DB(其他库先不要恢复),预计4:00开始执行恢复,6:00完成核心数据库恢复并开始结息日跑批,8:30刚好完成结息日跑批,可以开门对外营业,同时出结息日报表(预计3小时)。日间交易和结息日报表同时执行,压力很大,银行上午开门营业了,只有极少的核心业务可以办理,其他库都未恢复!而且业务办理非常缓慢,营业厅排队骚乱!直到领导下大决心,通知停业。下午下班时间,支付、网银、ATM等重要系统才陆续恢复使用!
下面是核心库的恢复时间图:

市电仅仅是电压不稳定,推迟一天切换又不会死!如果遵守DBA守则“选择合适的时间窗”原则,推迟一天切换市电!那么日结批量已经在1:00完成,2:30故障发生时,日结报表还有30分钟出完,一般报表存放于报表服务器,日结批量计算结果早已经同步到磁盘!那么恢复时间模型会是:4:00开始执行恢复,6:00完成核心数据库恢复并接续出日结报表,7:30前出完所有报表。无需进行2.5小时的结息日跑批计算,也无需完整的计算出3个小时报表,不影响日间交易!还能腾出时间和资源用于恢复其他库!也许就不用停业了,不会发生骚乱!
DBA守则第五条:生产无小事儿。我们团队对此次事故的总结,特别强调这点,乙方曾发邮件给甲方所有运维人员,如果运维的存储工程师或运维DBA能够充分重视数据存放的高端存储电池问题,在日常排查中就处理掉这个问题,就不会有这个数据丢失大灾难!
据oracle原厂专家说这家银行的DBA团队技术能力是很强的,至少有三个高级DBA一点儿不输oracle原厂技术专家,有的就是从oracle挖来的专家!所以只有技术能力还是不够的,DBA是数据库管理者,要有管理的思维,要有对风吹草动的敏感性,不要一味的迷信技术,而丧失了警觉!技术相当于手里的战争武器,技术专家会是美德装备,有精良装备而没有过硬的战争意志,没有好的战术素养,也是不能打胜仗的!而DBA守则五“生产无小事儿”就是一个优秀DBA的战术素养!
我们银行的高端存储也有这个电池问题,一个可用、一个不可用,存储厂商也建议我们升级微码,我们也几经交涉拍桌子踢板凳的不同意升级微码,“貌似是需要额外花钱升级,并不保证升级一定可以解决这个问题”。这个灾难后,我们克服所有困难坚决解决这个问题,哈哈^_^&,这也给我们上了一课!
生产无小事儿,哪怕是一个运维的电工,都需要培训到位,沟通到位!有兴趣的朋友可以求一下这位电工的心理阴影面积!
故障发展的一般规律:风吹草动期—小故障隐现期—大故障爆发期。风吹草动就是我们的战机,抓住每一个生产的小异常现象,仔细分析清楚现象背后隐藏的深层次问题,坚决推动解决,这就是生产无小事儿。比如错误的市电切换时间、错误的电工、错误的存储电池,任何一个问题抓住都会是英雄。
下面我再讲述一个身边发生的坚持“生产无小事儿”原则,发现小问题,积极推进问题的解决,避免了一次灾难!
案例六: 监控出现超时交易,AWR一个小的发现。
凌晨3点,接到公司电话说监控报警,发现几个超时交易,请DBA介入分析,我迅速抵达现场,检查数据库很正常的运行!打开AWR报告对比分析,发现每个SQL都比昨天同期慢一点点,好像也没啥影响,找不到根本原因!我就习惯性的打算把AWR报告每个数字都看一遍,思考每个数字指标的合理性,发现如下一个异常:
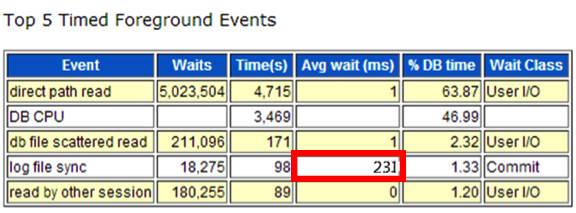
虽然log file sync并不是第一第二第三位的等待事件,但是同期时间比较,正常时平均等待是0.002秒,现在是0.231秒,是人体无感觉的慢了100倍。
团队几个人都在现场,我就很肯定的说出我的发现,我认为是高端存储IO速度比平时突然慢了100倍导致的,存储故障!当时也叫了EMC厂商,存储工程师说检查所有硬盘灯正常,存储也没有报错,不可能存储故障,EMC是有保障的很成熟的产品,全球这么多人用EMC,没听说突然慢100倍的现象。
既然你们都找不到故障原因,那么这个指标就是生产最大的发现,我就咬死了对每个陆续赶来支援的兄弟和领导说,存储肯定故障了,这给了他们很大压力!
直到一个领导到达现场,听了我的报告,马上决策,先打断存储的异地同步看看,反正也不影响生产的运行,让存储IO简单化!核心生产是同城异地存储级复制,一个事物需要同时写主机房和备机房的存储,两边存储都反馈写完成,事物才算写成功!
架构图:
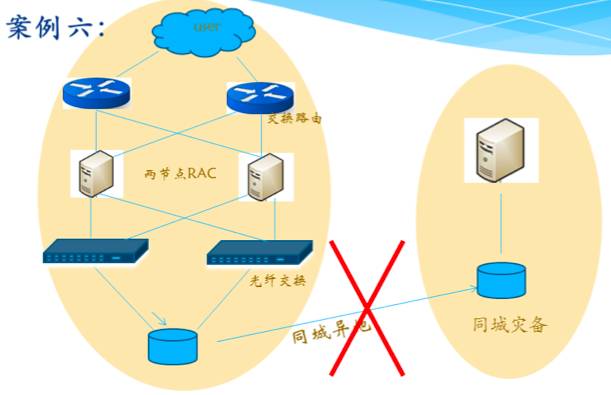
好吧,打断同步后,问题就这样解决了!
马上可以分析出,问题原因是同城机房间光纤链路抖动造成的。事后大家讨论,光纤交换机上是有异常日志的,只是以前没发生过,没有重视!EMC存储的日志记录里也有异常标记,可惜故障时,他们不理解这个异常标记的含义,当作正常日志给忽略了!因为不是报错日志,是异常记录,需要真正理解它的含义才能判断。
我们有个兄弟银行,架构和我们一样,也悲催的在凌晨三点监控报警,有超时交易,运维人员全部抵达现场,还叫了网络的、oracle、ibm、emc厂商的第三方专家,好不热闹,直到8:30银行开门交易时间,都没有定位到问题原因,在无奈下决定开门交易!日间交易冲进来,CPU达到100%,大家又一通分析原因,没有结果,大量交易出现积压。最终在中午把服务器压垮,无奈全行通知下午歇业,排查故障,终于在晚上发现了同城光纤链路抖动问题。
他们的团队和我们交流过运维管理!如果在故障时和我们团队电话交流一下,也许下一秒问题就解决了!在他们的案例中,我从来不认为oracle原厂专家无法发现log file sync的异常,我也不认为网络和存储的专家们无法发现异常信息,他们缺乏的是“生产无小事儿”的态度,缺乏的是紧紧抓住这个“小事儿”深入研究原因,大胆推测并大声的说出来。
我后来见到了这家银行的事故现场的高管,通过我的描述,他说我这个成功是来自DBA的灵感,成功不能建立在某个人的灵感上;我说这就是战术素养,别人缺乏的是对故障的不断反复思考和总结。有没有反思,为什么故障的时候,CPU达到100%了,业务大量积压,那么多人在现场没有任何作为,如果杀掉积压进程,提供有损服务,扛过日间交易,为找到故障原因争取时间,坚持DBA守则一“保证生产的可持续运行”也能挽救这次故障。多种解决思路的打开,相谈甚欢。
兄弟银行的这次故障,才让我们团队意识到,我们坚持DBA的守则,避免了自己银行发生宕机灾难。真正做到了趋利避害。
这点前面也有案例提及,很多高手都是死在艺高人胆大,处理问题不经测试,直接上生产。当然也有人说,我们没条件。你要和领导强调,反复强调,没有测试环境的生产就是不重要的生产,不要想达到99.99%甚至更高的在线要求。想尽办法,创造条件,但有条件!
这点就不讲了,大家都耳熟能详了!
我的分享讲完了,希望这些案例对你有启发,有帮助,希望能助力你的职业发展。如果你想和我讨论这些案例,或者您经历的案例想和我分享,欢迎ora-lazy交流或邮箱82186960@qq.com私信给我。
⊙保证生产的可持续运行。
⊙有效的备份重于一切。
⊙任何变更可回退。
⊙选择正确的时间窗。
⊙生产无小事儿。
⊙不拿生产做实验。
⊙制定规范。

中国OCM之家
专注数据 共现梦想
QQ群:554334183
