




先对xDeepFM模型做个简要总结。针对[广告机制]-模型篇:CTR预估之Deep&Cross算法中cross部分的两个缺点:1)输出被限定在一个固定的格式,且每个隐层都是的标量倍;2)交互是以bit-wise方式进行的。xDeepFM中的CIN部分的特征交互是以vector-wise方式进行的,一方面避免了同一embedding向量元素之间的影响,发挥了FM思想的优势,另一方面增强了CIN部分的模型表达能力
下面是对论文原文的详细介绍
0.摘要
组合特征时许多商业模型能够成功的关键。在网络级规模的系统中,由于原始数据多种多样、量比较大且更新速度较快,手动去完成这些特征工程工作的代价是非常大的。基于因子分解的模型以向量积来度量特征之间的交互,可以自动学习特征之间的交互,并将其推广到训练数据中未出现的组合特征。随着深度神经网络(DNN)在各个领域的成功,近年来研究人员提出了几种基于DNN的因子分解机来学习低阶和高阶特征交互。尽管DNN拥有从数据中学习任意函数的强大能力,但它一般都是以bit-wise的方式隐式地生成特征交互。本文提出了一种新的压缩交互网络(Compressed Interaction Network, CIN),其目的是以vector-wise的方式显示地生成特征交互。我们证明了CIN与卷积神经网络(CNNs)和递归神经网络(RNNs)有一些共同的功能。我们进一步将一个CIN和一个经典的DNN组合成一个统一的模型,并将这个新模型命名为eXtreme Deep Factor- ization Machine (xDeepFM)。一方面,xDeepFM能够显示地学习特定阶的特征交互,另一方面,它可以隐式地学习任意低阶和高阶的特征交互。我们开源了该工作的工程实现:github链接
1.知识前导
1.1 Embedding层
在计算机视觉或自然语言理解任务中,输入数据通常是图像或文本信号,已知它们在空间或时间上是相关的,因此DNN可直接应用于具有密集结构的原始特征。而在网络级规模的推荐系统中,输入数据是高维稀疏的,且没有明显的时空相关性。因此,多域特征分类被广泛地应用,例如,对于输入样本[user_id=s02,gender=male, organization=msra,interests=comedy&rock],将会通过特征域感知的one-hot编码成为一个高维稀疏的特征向量:
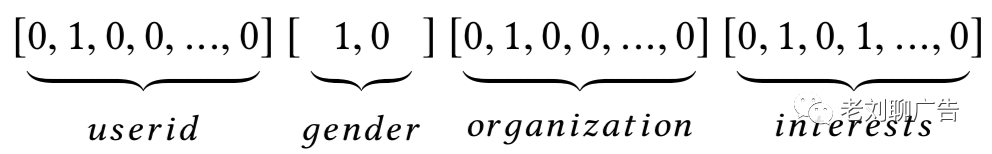
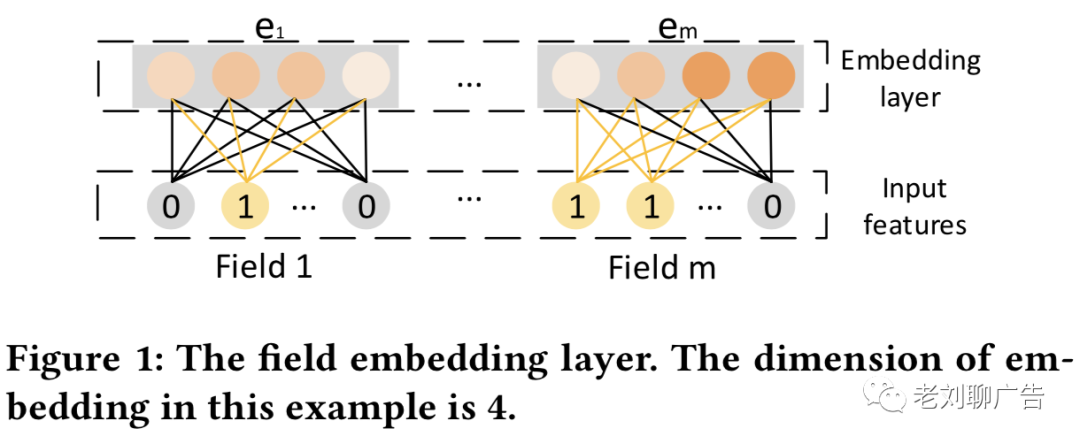
在原始特征输入上应用embedding层,将其压缩为低维、密集的实值向量。embedding层的结构如图(1)所示,它的输出是一个拼接向量:
其中表示特征域的个数,是其中一个特征域的embedding。虽然样本的特征长度可以不同,但它们的embedding长度都是相同的,即,其中是特征域embedding的维数
1.2 隐式高阶交互
FNN,Deep Crossing和Wide&Deep中的deep部分利用前馈神经网络在特征域的embedding向量上学习高阶特征交互。前向过程是:
其中是层深,是激活函数,是第层的输出。其结构与图(2)非常地相似,只是不包括FM和product层。这种结构以bit-wise的方式对交互进行建模,这意味着,同一个特征域的embedding向量中的元素也会相互影响
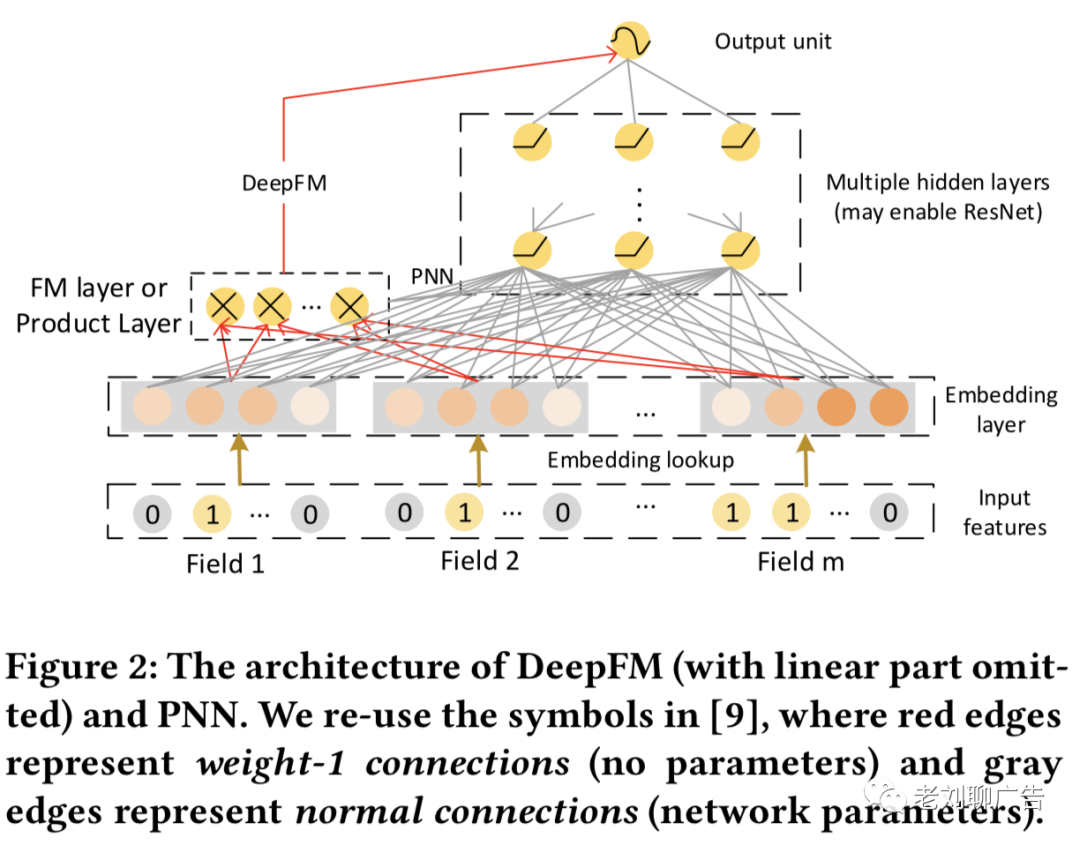
PNN和DeepFM对上述架构进行了一些微改,除了在embedding向量上应用DNN外,还在模型架构中增加了二阶交互层。因此,这类模型中既包含bit-wise方式的特征交互,又包含vector-wise方式的特征交互
1.3 显式高阶交互
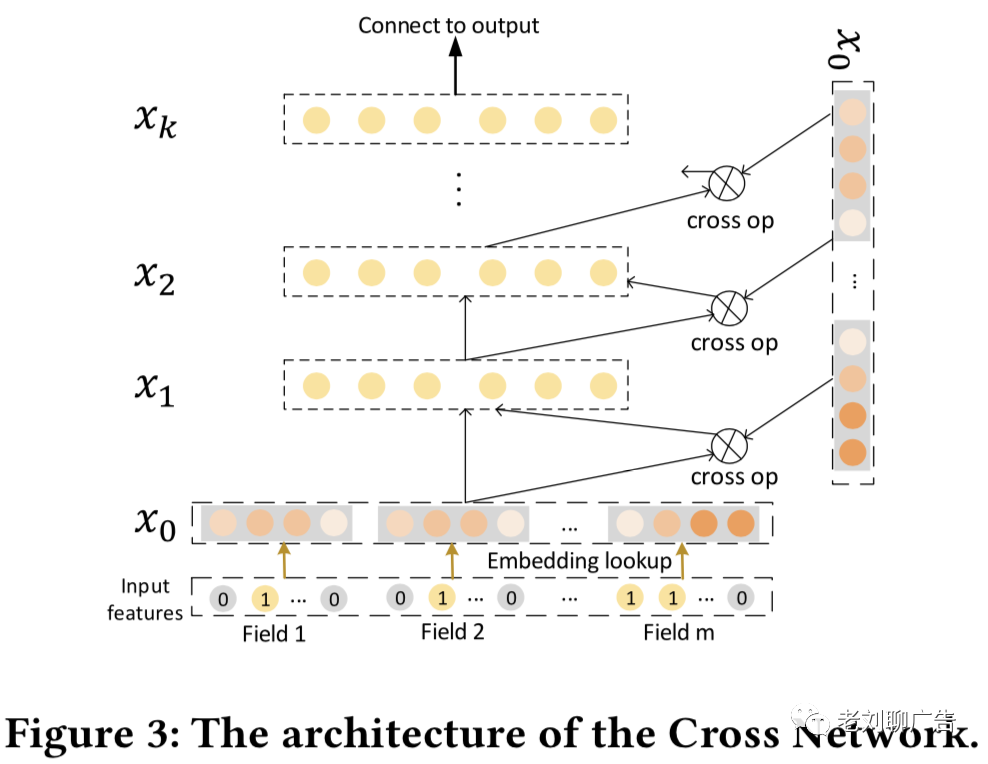
Cross Network (CrossNet)的架构如图(3)所示。它的目标是显示地对高阶特征交互进行建模。与经典的全连接前馈神经网络不同,它的隐层的计算方式如下:
其中分别是第层的权重、偏置系数和输出。我们认为交叉网络学习是一种特殊的高阶特征交互,其中每个隐层的输出都是输入的标量倍
定理2.1:考虑一个层的交叉网络,第层定义如下:
交叉网络的输出是的标量倍
证明:当时,根据矩阵乘法的分配率和结合律,我们有:
其中,标量是关于的一个线性回归,是的标量倍。当时,我们有:
其中,是一个标量,因此,仍旧是的标量倍。通过归纳假设,交叉网络的输出是输入的标量倍
需要注意的是,标量倍并不意味着与是线性关系,因为系数是与相关的。交叉网络能够非常有效地学习特征交互(与DNN模型相比,时间复杂度可忽略不计),它的缺点是:1)它的输出被限定在一个固定的格式,且每个隐层都是的标量倍;2)交互是以bit-wise方式进行的
关于交叉网络的更多介绍,可参考:
2.我们的模型
2.1 压缩交互网络(Compressed Interaction Network)
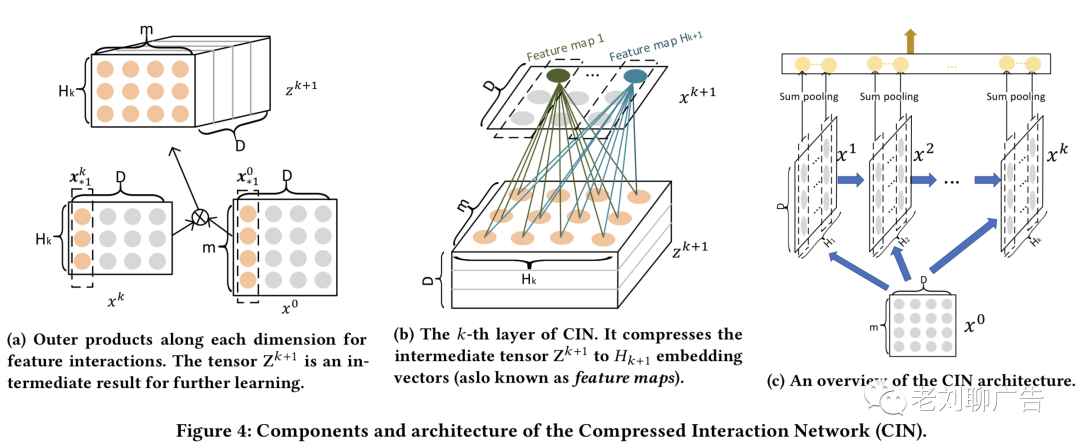
我们设计了一种新的交叉网络,叫做压缩交互网络,它主要考虑了以下几点:1)交互发生在向量级别(vector-wise),而不是元素级别(bit-wise);2)以显式的方式进行高阶特征交互;3)网络的复杂度不会随着交互的复杂程度的增加而呈指数增长
由于embedding向量被认为是vector-wise交互的一个单位,在此基础上,我们以矩阵的形式给出了特征域embedding的输出:,的第行表示第个特征域的embedding向量,是特征域embedding的维度。CIN的第层输出也是一个矩阵,其中表示第层的特征向量个数,且。对于每一层,的计算方式如下:
其中,,是第个特征向量的参数矩阵,表示哈达玛积,举个例子,。需要注意的是,是通过和交互得到的,因此,特征交互可以以显式的方式进行度量,相互作用的程度随着层深而增加。CIN的结构和递归神经网络(RNN)非常相似,下一个隐层的输出依赖上一个隐层和一个额外的输入。我们保持了所有层的embedding向量结构,因此交互是发生在向量维度的
有趣的是,公式(6)与计算机视觉中著名的卷积神经网络有很强的联系。如图4(a)所示,我们引入了一个中间张量,它是隐层和原始特征矩阵的外积。因此,可以看作是一种特殊类型的图像,而是过滤器。如图4(b)所示,我们滑动过滤器通过,然后得到了一个隐层向量,这在计算机视觉中通常被称为特征图。因此,是个不同特征图的集合
图4(c)展示了CIN的整体架构。用表示网络深度,每个隐层都与输出单元有一个连接。我们首先对隐层的每个特征图应用sum池化:
由此,我们可以得到一个池化向量,它的长度是。随后,所有的池化向量将会被拼接起来,,然后将该向量输入到输出单元。如果是二分类任务,输出单元可以使sigmoid函数:
2.2 CIN分析
本节将会分析CIN的复杂度及其有效性
2.2.1 空间复杂度
第层的第个特征图有个参数,用来表示。因此,第层一共有个参数。考虑输出单元的回归层,有个参数,因此,CIN的参数总个数是。需要注意的是,CIN与embedding的维度是相互独立的。与此相反,一个层的DNN的参数个数是,其会随着embedding的维度增加而增加
一般情况下,和不会非常大,因的规模是可以接受的。必要时,我们可以用L阶分解,用两个矩阵来代替:
其中,,,且。假设每个隐层都具有相同数量的特征图,通过L阶分解,空间复杂度由减少至
2.2.2 时间复杂度
计算张量的时间复杂度是。因为每层有个特征图,因此计算一个层的CIN的时间复杂度是。一个层的DNN的时间复杂度是。因此,CIN的主要缺点在于时间复杂度上
2.2.3 多项式近似
接下来我们将会分析CIN的高阶相互作用性质。为简单起见,我们假设CIN隐藏层的特征图数量都等于特征域的数量,用表示小于等于的正整数集合。第一层的第个特征图用表示,计算如下:
因此,第一层的每个特征图对每对特征之间的交互进行了建模。类似地,第二层的第个特征图计算方式如下:
需要注意的是,关于和的所有运算在先前的隐层中已经完成了计算。为了更加清晰地说明问题,我们对等式(11)中的因子进行展开,可以看到第二层使用个新参数对3阶交互进行了建模
一个传统的k阶多项式应该有个系数,CIN只使用个参数就可以近似传统的k阶多项式
2.3 隐式网络的组合
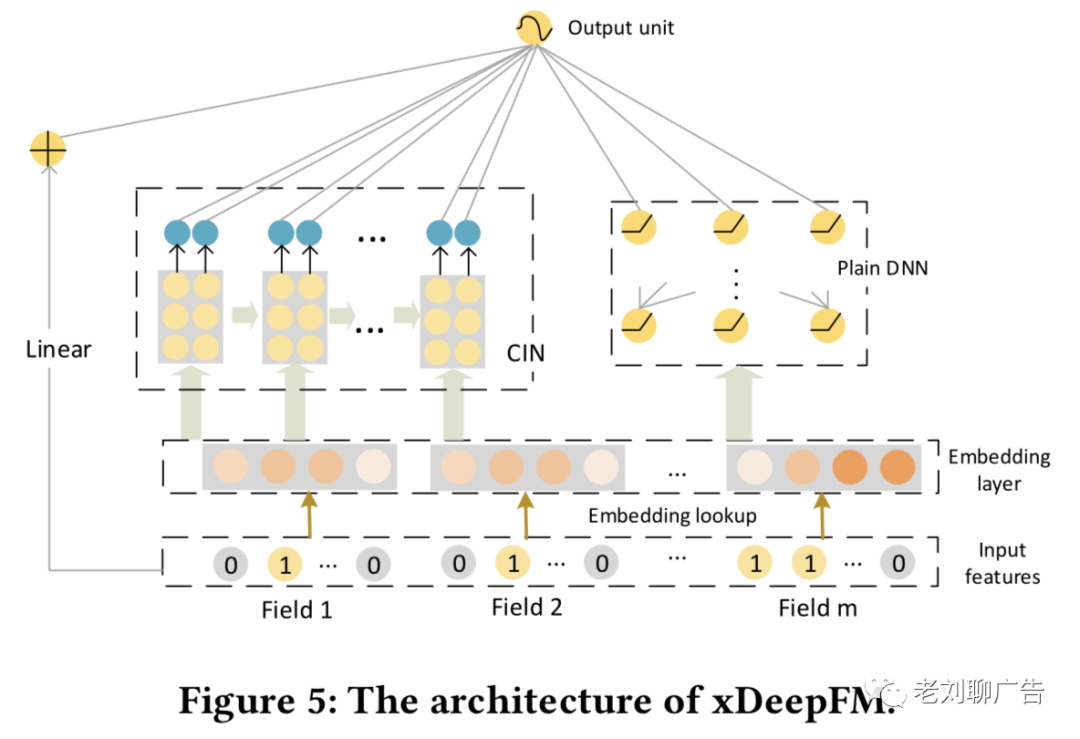
正如前面所述,DNN可以隐式地学习高阶特征交互。由于CIN和DNN可以互补,将这两种结构组合起来可以起到增强模型的效果,组合后的模型与Wide&Deep或者DeepFM非常相似,整体结构如图5所示。我们将该模型命名为xDeepFM(the eXtreme Deep Factorization Machine),一方面,它既包括低阶特征交互,又包括高阶特征交互;另一方面,它同时包括了显式特征交互和隐式特征交互。它最终的输出单元是:
其中是sigmoid函数,是原始特征,分别是DNN和CIN的输出,和是可以学习的参数。对于二分类任务,损失函数可以使用log损失:
其中是训练样本个数。训练过程以最小化下面的目标函数为目标:
为正则化参数
