




本教程详细介绍了 VOC 格式数据集的制作方法。
1、目录结构

其中 makeTXT.py 用于生成 VOCdevkit/VOC/ImageSets/Main/*.txt,voc_label.py 根据 VOCdevkit/VOC/Annotations/* 、VOCdevkit/VOC/images/* 和 VOCdevkit/VOC/ImageSets/Main/*.txt 生成 VOCdevkit/labels/*.txt、VOCdevkit/VOC/test.txt(train.txt、val.txt)
2、Annotations
可以用 LabelImg 对训练图片进行标注,会得到 *.xml,看起来像这样:
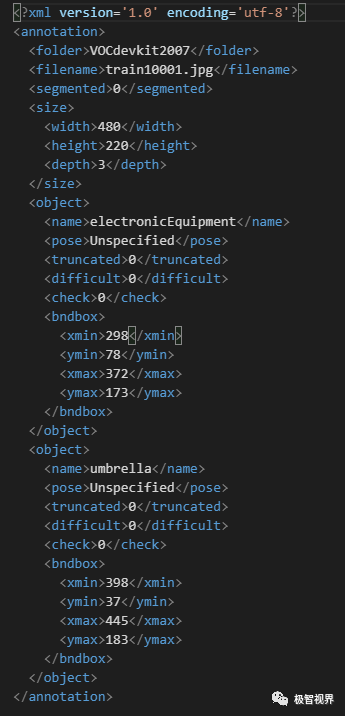
3、images
这个没啥好说的,就是训练的图片。
4、ImageSets/Main
由 makeTXT.py 生成 VOCdevkit/VOC/ImageSets/Main/* .txt 文件,包括 test.txt、train.txt、trainval.txt、val.txt。各文件里面的内容看起来差不多,像这样:
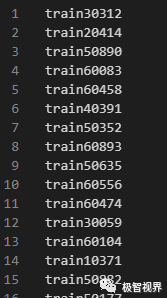
5、labels
由 voc_label.py 生成,来看一下 labels/*.txt 里的文件内容,像这样:

6、makeTXT.py
这个脚本用于生成 VOCdevkit/voc/ImageSets/Main 下的 *.txt。
来看一下 makeTXT.py 脚本的内容:
import os
import random
trainval_percent = 0.1
train_percent = 0.9
xmlfilepath = 'VOCdevkit/VOC/Annotations'
txtsavepath = 'VOCdevkit/VOC/ImageSets'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('VOCdevkit/VOC/ImageSets/Main/trainval.txt', 'w')
ftest = open('VOCdevkit/VOC/ImageSets/Main/test.txt', 'w')
ftrain = open('VOCdevkit/VOC/ImageSets/Main/train.txt', 'w')
fval = open('VOCdevkit/VOC/ImageSets/Main/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
7、voc_label.py
这个脚本主要用于生成 VOCdevkit/VOC/labels/*.txt 以及 最终训练要用的 VOCdevkit/VOC/train.txt、VOCdevkit/VOC/test.txt 和 VOCdevkit/VOC/val.txt。
来看一下 voc_label.py 脚本的内容:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets = ['train', 'test','val']
classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus",
"car", "cat", "chair", "cow", "diningtable", "dog", "horse",
"motorbike", "person", "pottedplant", "sheep", "sofa", "train",
"tvmonitor"]
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(image_id):
in_file = open('VOCdevkit/VOC/Annotations/%s.xml' % (image_id))
out_file = open('VOCdevkit/VOC/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
if obj.find('difficult'):
difficult = obj.find('difficult').text
else:
difficult = 0
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
print(wd)
for image_set in sets:
if not os.path.exists('VOCdevkit/VOC/labels/'):
os.makedirs('VOCdevkit/VOC/labels/')
image_ids = open('VOCdevkit/VOC/ImageSets/Main/%s.txt' % (image_set)).read().strip().split()
list_file = open('VOCdevkit/VOC/%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write('VOCdevkit/VOC/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()
收工~
声明:转载请说明出处
扫描下方二维码关注【极智视界】公众号,获取更多实践项目资源和读书分享,让我们用极致+极客的心态来迎接AI !

