




现场反馈达梦数据库cpu使用率较高,sql查询效率较低,有时消耗3S及以上,具体表现是服务器cpu高,达到89%,io高,util%达到100%,cpu_wait也达到了5%。还有一个问题特别奇怪,特别是两张相同的表,查询起来效率都不一样,下面看看这个问题的具体分析:
select CODE, NAME, PARENET_CODE, nvl(bbb.cnt, 0) as subRemakrCount
from (select CODE, NAME, PARENET_CODE
from DIC_EVIDENCE_CHAIN
where PARENET_CODE in
(SELECT CODE
FROM DIC_EVIDENCE_CHAIN
WHERE PARENET_CODE in
(SELECT evidence_flaw_code
FROM SH_CASE_EVFLAW
WHERE CASE_TYPE_CODE in
(select case_cause
from sh_cases
where case_id = 'xn0928156814252726452370')))
ORDER BY SEQ ASC) aaa
left join (select count(1) as cnt, L.LABEL_CODE
from SH_EVIDENCE_REMARK_LABEL L
where L.IS_DELETE = 0
and L.LABEL_FLAG = 1
and L.EVIDENCE_REMARK_ID IN
(SELECT ER.ID
FROM SH_EVIDENCE_REMARK_2 ER, SH_EVIDENCES E
WHERE ER.EVIDENCE_ID = E.ID
AND ER.IS_DELETE = 0
AND E.STATUS = 1
AND E.CASE_ID = 'xn0928156814252726452370')
group by L.LABEL_CODE) bbb
on aaa.CODE = bbb.LABEL_CODE
表SH_EVIDENCE_REMARK查询结果
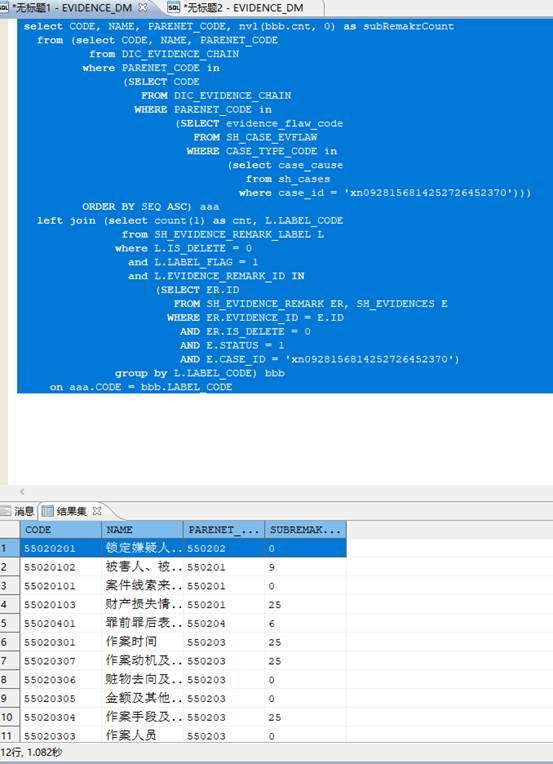
表SH_EVIDENCE_REMARK_2查询结果:

表SH_EVIDENCE_REMARK_2执行计划
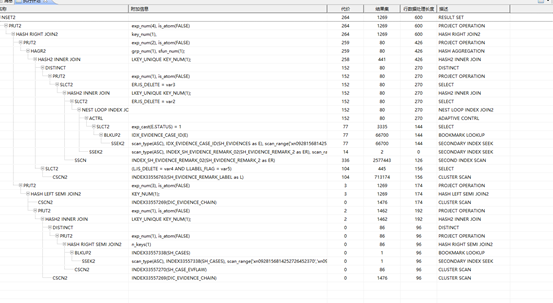
表SH_EVIDENCE_REMARK执行计划

优化前:
两表执行计划不一样,执行时间分别为1.2s及0.2s
优化方法:
具体为什么执行计划不一样,可能需要达梦工程师帮忙解答一下,自己猜的可能原因:达梦的优化器还不能选择适合的执行计划。
添加EVIDENCE_REMARK_ID、LABEL_FLAG、IS_DELETE 组合索引,帮助优化器选择最优的执行计划
优化后执行时间:0.05s
问题SQL2:
select
se.case_id case_id,
ser.id id,
ser.is_delete,
ser.attach_id
from sh_evidence_remark ser
inner join sh_evidences se on ser.evidence_id=se.id
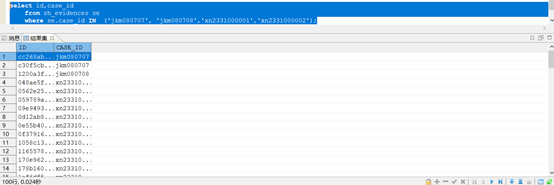
where se.case_id IN
(
'jkm080707', 'jkm080708','xn2331000001','xn2331000002');
从执行计划来看:

se.case_id IN
(
'jkm080707', 'jkm080708','xn2331000001','xn2331000002');
这部分是走了索引的,索引为IDX_EVIDENCE_CASE_ID,扫描类型为范围扫描,实际情况下,这部分执行的速度并不慢,参考:
执行时间不到30ms,这条sql的这部分结果集也不大,只有200多行,但是因为case_id这个列重复值很多,导致执行计划评估数据量为26w行:
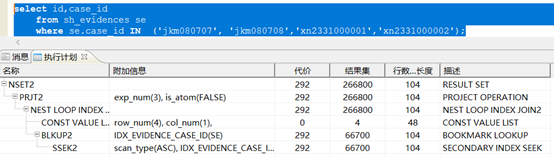
语句最慢的执行部分为join部分,消耗了500ms左右,
语句转换为:
select
sa.case_id
,
ser.id id
,
ser.is_delete,
ser.attach_id
from
sh_evidence_remark ser
inner join
(
select
id,
case_id
from
sh_evidences se
where
se.case_id IN ('jkm080707', 'jkm080708', 'xn2331000001', 'xn2331000002')
)
sa
on
sa.id=ser.evidence_id
where
ser.evidence_id in
(
select
id
from
sh_evidences se
where
se.case_id IN ('jkm080707', 'jkm080708', 'xn2331000001', 'xn2331000002')
) ;
则执行时间不到50ms,而结果集一样。
由于涉及到保密信息,不能过多的举例。通过这次优化实践,学习和整理了很多东西,也和大家分享一下:
目前开发SQL编写中存在的问题:
1、 SQL语句过于复杂,很多SQL大于100行;
2、 SQL语句中产生太多的JOIN,比如案件列表SQL由7张表进行JOIN,很难获得很好的性能;
3、 编写SQL时常量写在where条件的左边,很多优化器对此很难做出选择;
4、 业务逻辑都在一条SQL内整合,随着不同的开发人员修改SQL语句,导致后期SQL难以被读懂,后续优化困难;
5、 SQL语句采用大量的EXISTS而不使用IN,使得SQL语句可读性较差,同时性能也许更差。
达梦和oracle优化器区别:
1、 oracle的优化器很成熟,达梦则不然,执行计划可能无法反映真实的执行情况;
2、 达梦的全表扫描显示为cluster
scan,而oracle为full table scan,查看执行计划时要注意;
3、 达梦的半连接有时候效率会很差,但oracle半连接一般不会,所以对于执行计划中存在半连接的情况要注意;
4、 Oracle会自动选择最优的执行路径,但是达梦则不然,很多SQL需要编写SQL时手动为达梦优化器指定路径才能获得良好性能;
SQL编写规范(通用):
1、 所有SQL的JOIN不得超过3张表,若确实需要多张表则由应用层进行实现;
2、 禁止将常量或者函数写在where条件的左边,若必须要这么做请调整不合理的数据库设计;
3、 为防止后期DML操作产生大量的IO,每张表的索引最大不超过5个,如果为OLAP环境可以适当放宽,但也不能超过10个;
4、 开发编写SQL时应对表数据量进行初步预估,对于较大的表SQL一定建议走索引;
5、 避免编写过长的SQL,大于50行的SQL应该直接重写。
达梦SQL优化及设计技巧:
1、 为达梦选择最优的执行路径,不能过高期望优化器;
2、 SQL查询应该尽可能返回较小的结果集,如果返回结果集很大则可以考虑使用缓存,如redis等;
3、 达梦的where条件最好在查询内进行约束,不要写在join的最后,优化器有可能在最后才使用过滤条件,造成执行效率低下。
4、 对于大表设计时应充分考虑后期的运维管理需求,建议初期使用分区设计,方便以后管理;
5、 优化SQL时,可以考虑将SQL拆分成小块,对每个小块进行效率分析及优化,这样可以迅速定位到性能的问题点;
6、 建立合适的复合索引已便于索引扫描时不会进行回表操作;
7、 除非特殊情况,大多数情况下使用IN而不要使用EXISTS,使得SQL可读性更好,性能也更好。
本次通过对sql的优化,数据库的cpu和io整体都下降50%以上,但是SQL优化也不是万能的,有些sql优化空间较小,需要由开发人员进行拆解,使用应用实现SQL的逻辑,因此本次未作进一步优化。
