




Pgpool-II 提供了“查询缓存”功能,可以加速对数据库的 SELECT。它将查询结果存储到指定的存储(共享内存或 memcached)。如果相同的查询(更准确地说,具有相同文本的 SELECT 查询)到达,Pgpool-II 返回缓存的结果而不访问数据库。这非常快,因为:
- 查询结果是从内存中获取的,而不是数据库的(通常在桌面上)存储
- 不使用数据库服务器上的 CPU 或内存
有什么陷阱吗?
SELECT 结果是从数据库还是缓存中获取对客户端是透明的。也就是说,除了响应速度之外,您没有意识到区别。好的,听起来很棒。但是使用查询缓存有什么陷阱吗?一是缓存命中率。由于对底层表的任何修改都会清除缓存,因此在涉及频繁更新的系统上不适合该功能。根据手册,缓存命中率低于70%的系统推荐使用查询缓存。
行可见性规则
您可能需要关注的另一个陷阱是行可见性规则。该规则定义了表行对其他会话的可见性(因此,如果您是数据库中的唯一用户,则无需担心这一点)。PostgreSQL 提供了多种事务隔离级别。行可见性规则将根据事务中使用的事务隔离级别而有所不同。例如,使用已提交读隔离级别(这是默认设置),其他用户在提交之前不会看到由您的事务更新的行的新数据。

但是,使用可重复读隔离级别,即使在事务提交后,其他用户也不会看到您的事务更新的行的新数据。它们仅在用户开始新事务后可见。

查询缓存可能会破坏可见性规则
Pgpool-II 的查询缓存不遵循可见性规则。缓存是在事务提交时创建的。不同之处在于,一旦创建了缓存,任何事务都可以看到缓存条目。这适用于读提交隔离级别。但是使用可重复读隔离级别,它打破了可见性规则。
假设查询缓存特性用于可重复读事务隔离级别。这一次,在 UPDATE 之后,发出 SELECT 以创建一个缓存条目。
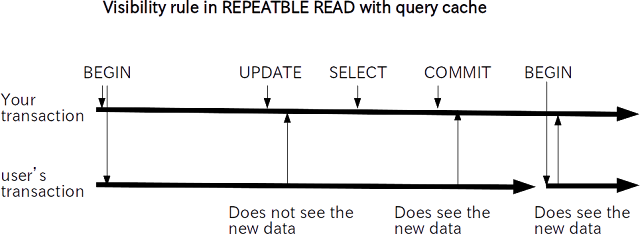
与上图不同,一旦您的事务提交,用户的事务将看到新数据,因为新数据将在事务提交时注册,并且任何人都可以看到数据。这不仅可能发生在可重复读事务隔离级别,也可能发生在可序列化事务隔离级别。
这有点类似于您在使用 COPY FREEZE 时可能会看到的现象。假设事务隔离级别是可重复读取,并且您在事务中使用 COPY FREEZE 将数据复制到表。一旦您的事务被提交,在您的事务开始之前已经开始的其他事务将看到复制的数据。这是因为任何人都可以看到“冻结”的行。
结论
Pgpool-II 的查询缓存对于读取密集型繁忙系统是一个有用的功能。然而,这可能会导致可重复读取和可序列化事务隔离级别中的某些读取异常。因此,请谨慎使用具有那些事务隔离级别的功能。
