





Oracle数据库由上世纪70年代至今,经历了40余年的发展历程,版本也已由初代Oracle迭代至目前最新的21C。同样作为关系型数据库的MySQL数据库也由1996年的1.0版本不断演进至8.0版本。2009年随甲骨文并购Sun公司,MySQL也归属到了Oracle旗下,但其扔保持着开源产品的特性。相比较而言,两款产品优缺点也非常鲜明,Oracle长期以来一直以性能卓越服务稳定著称,采用了标准的SQL协议,兼容性及可移植性方面也表现良好,但其购买成本及对硬件环境的要求均相对较高。MySQL则由于其开源的特性,小巧灵活的部署方式以及低廉的成本,逐渐从互联网行业中崛起,并衍生出很多各具特点的分支版本。在近10年的DB-Engines排行中,两款产品长期以较为接近的分差持续占据前两名。我行在18年引入MySQL后,增长率及使用率均呈现出逐年攀升的趋势,在目前发展规划中,MySQL数据库在也成为了X86平台上的首选方案。因此,本文将对两款数据库产品在行内主推版本Oracle19c以及MySQL5.7进行一次部分技术点的对比解析,以便于开发以及运维人员能够更好地了解掌握其各自的特点。

表存储方式
在Oracle中,存储数据最常见的为堆表(HOT),堆表的特点为无序存储,插入数据的过程中,高水位线以下寻找到空闲的数据块即可,插入效率较高,同时会生成可以被显示引用的ROWID。为了提高访问效率,通常会根据访问需求建立恰当的索引,Oracle中索引结构为B-Tree类型,根节点及分支节点仅起到指针作用,最后通过叶子节点中存储的键值及ROWID信息回表访问数据,所以在增删改的过程中,维护的是索引的结构与信息而不是表内的数据顺序。
在MySQL中为了支持事务,选取的存储引擎为Innodb,而在Innodb引擎中,数据存储采用的是索引组织表形式(IOT),即以B+树的形式将聚集索引信息与数据共同存储维护,数据位于叶子节点的位置。当未显示指定主键时,Innodb会选择第一个不包含Null值的唯一索引作为主键索引。若表使用了自增主键,则每次插入记录时,会顺序添加到索引节点的后续位置,插入效率较高。而使用非自增主键时,每次插入都有可能为了维护顺序去移动数据,除增加开销外还会产生较多的碎片。下图简要示意了MySQL中主键索引与二级索引的数据访问过程。
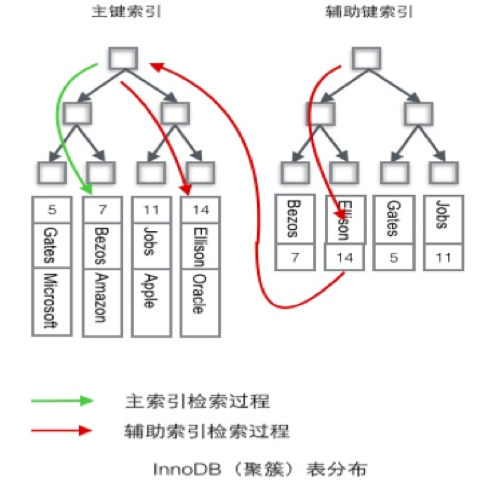
通过上述对比,我们可看出Oracle及MySQL数据存储的差异,同时可以了解到MySQL Innodb引擎中表上无业务属性的自增ID用途,即维护记录顺序,且不会存在键值被更新从而出现重组记录顺序的情况。

Online DDL
DDL操作通常伴随着日常的投产变更产生,无论对于Oracle或MySQL,常见的操作有,修改表结构,如加不带默认值的列,增加字段长度或者删除创建索引,truncate表等。而删除列,修改字段数据类型等DDL属于大概率会对系统造成较大影响的操作,且较为少见,属于一事一议的范畴。
在Oracle数据库中,大部分DDL操作仅是修改数据字典中的对象元数据信息,这时为了维护数据的一致性以及完整性,DDL与DML操作申请的排他锁会产生互斥,因此在高并发对象执行相应投产操作时,我们经常会看到ora-00054:resource busy and acquire with nowait specified的错误。但由于加列或增加字段长度的DDL操作在修改元数据信息过程中持有锁的时间非常短暂,所以这类操作对DML产生的锁阻塞影响极为轻微,可以视为Online操作。对于索引的Create Online或Rebuild Online,整个过程中表级别的锁持有模式为row-S (SS),与DML操作的row-X (SX)类型的锁互相兼容,因此不会在表级发生阻塞,而发生在行一级别的share (S)类型的锁与执行DML的会话持有的exclusive (X)锁之间是存在不兼容的情况的,但由于锁粒度的细化,使副作用大幅降低。同时在Online过程会生成临时的IOT表用于记录索引维护期间其他DML操作产生的变化,待索引维护完成后将IOT中的记录合并至索引中。
MySQL从5.6版本后开始逐渐支持online ddl操作,但其online支持实际也包含了5.6版本以前的copy及inplace方式。对于不支持online的ddl操作通常采用copy方式,比如修改列类型,删除主键等;对于inplace方式,MySQL内部以“是否修改记录格式”为基准也分为两类,一类需要重建表(修改记录格式),比如添加、删除列、修改列默认值等;另外一类是只需要修改表的元数据,比如添加、删除索引、修改列名等。MySQL将这两类方式分别称为rebuild方式和no-rebuild方式。online ddl主要包括3个阶段,prepare阶段,ddl执行阶段,commit阶段,rebuild方式比no-rebuild方式实质多了一个ddl执行阶段,prepare阶段和commit阶段类似。几个阶段的操作过程如下:
Prepare阶段,创建新的临时frm文件持有EXCLUSIVE-MDL锁,禁止读写操作;根据alter类型,确定执行方式(copy,online-rebuild,online-norebuild);更新数据字典的内存对象;分配row_log对象记录增量生成新的临时ibd文件。
ddl执行阶段,降级EXCLUSIVE-MDL锁,允许读写操作;扫描旧表的聚集索引每一条记录;遍历新表的聚集索引和二级索引;逐一处理根据rec构造对应的索引项;将构造索引项插入sort_buffer块;将sort_buffer块插入新的索引处理ddl执行过程中产生的增量(仅rebuild类型需要)。
commit阶段,升级到EXCLUSIVE-MDL锁,禁止读写操作;重做最后row_log中最后一部分增量;更新innodb的数据字典表;提交事务(刷事务的redo日志)修改统计信息;rename临时idb文件,frm文件。
以下是MySQL常见DDL操作的算法:
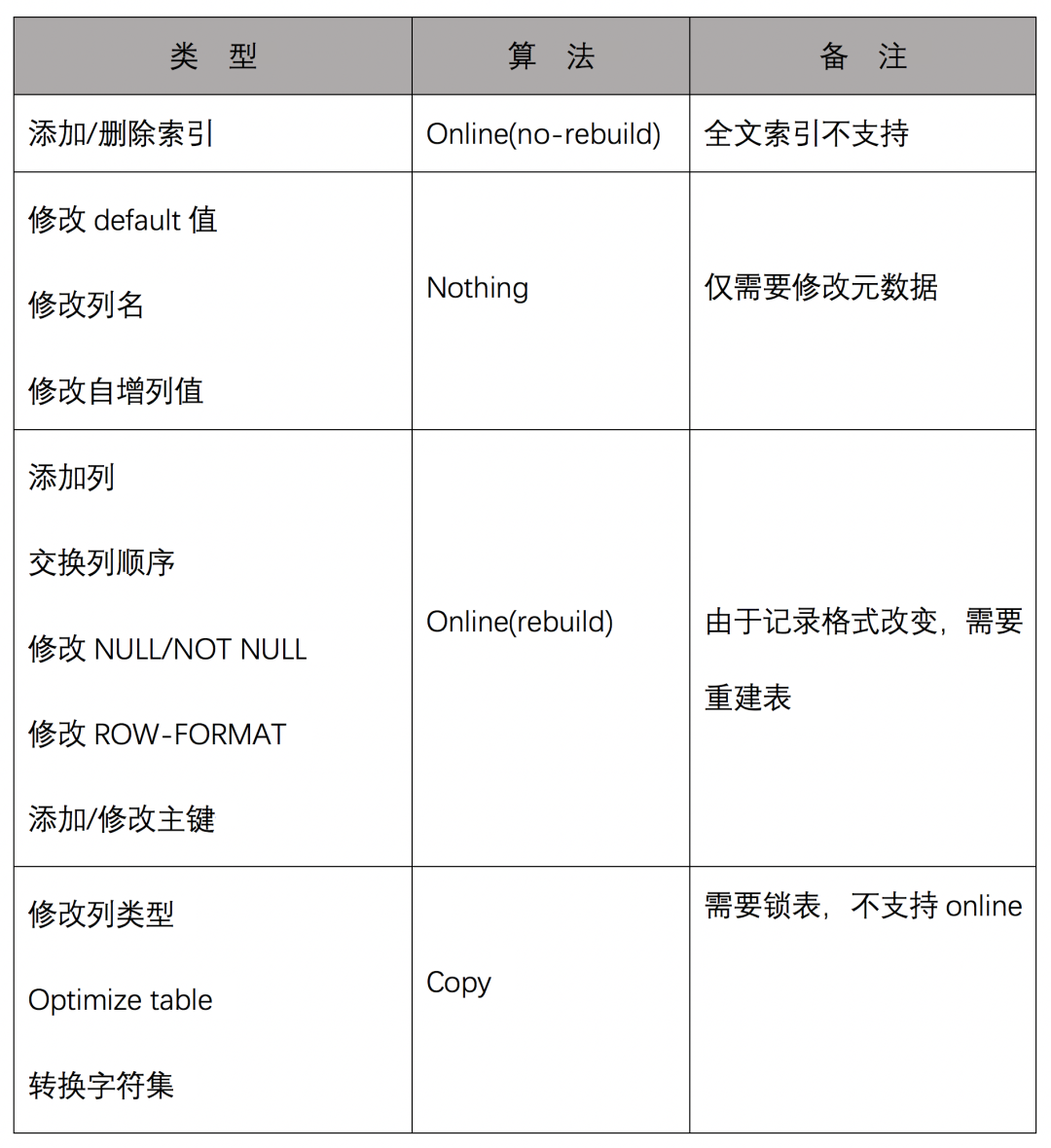
对于Copy算法的DDL操作,为了尽可能缩短锁表时间,通常都会选择使用第三方的pt-online-schema-change工具来辅助进行相关操作,pt-osc工具的原理是基于触发器实现了类似Online rebuild的过程,但其使用也具有一定的限制,表上缺少主键、存在外键,存在触发器都可能会对工具的使用造成影响。并且与Copy算法一样,操作过程需要与对象大小相同的剩余空间。
Oracle的大部分DDL均可在线执行,但以下几种需格外小心,包括增加待带默认值的列,修改字段类型由varchar到char,或char字段增加长度等,均可能由于隐式DML操作导致长时间阻塞正常业务并产生大量日志。而MySQL中则需更为仔细的评估操作类型是否支持Online,即使使用pt-osc等工具,也要对操作时的空间好好把握,pt-osc过程类似Oracle的在线重定义技术,同时大表上的DDL操作更应该重视测试环节。另外,MySQL数据库Online DDL的不足也是通常对大表会建议物理分表而不是表分区的主要原因,其物理分表的目的主要是为了减少DDL操作的锁表成本。

数据备份
实现Oracle数据库最完整且高效的备份方式为RMAN备份,在热备的过程中,数据虽然一直在改变,但数据块中单向递增的SCN与REDO日志中记录的事务信息结合,从而保证了数据的一致性。RMAN基于数据块的备份方式,也是其压缩功能实现的基础,同时在备份的过程中除了消耗部分IO资源,并不会出现锁表锁库的现象。
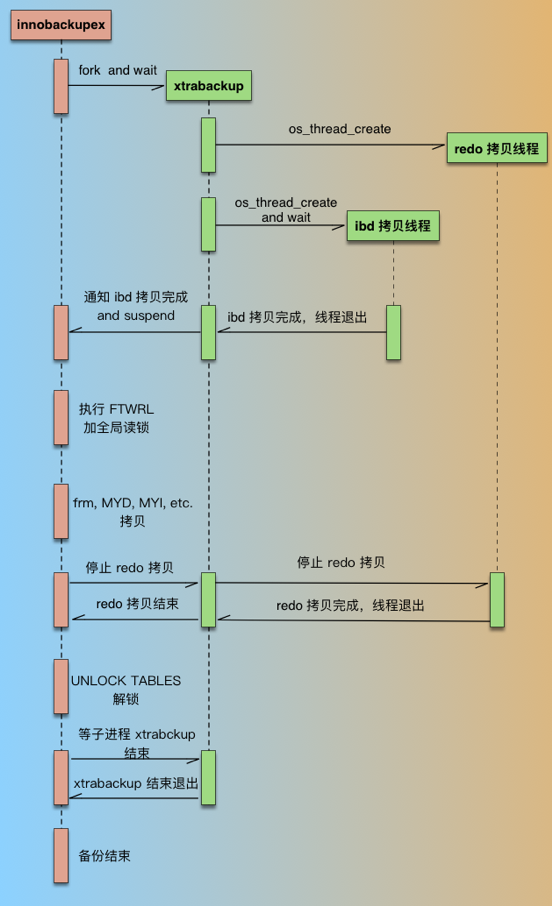
MySQL数据库是通过Percona 公司开发的XtraBackup(简称PXB)来实现,完整的备份流程如下:
开始备份后fork进程启动xtrabackup进程,xtrabackup进程开始备份idb文件。在备份Innodb数据时,通过两个线程分别对redo文件以及ibd文件拷贝。
xtrabackup进程拷贝完成idb后,通知innobackupex,同时xtrabackup进程进入等待状态,此时redo仍会继续拷贝。
innobackupex开始执行flush tables with read lock(FTWRL),获取一致性点。开始进行非Innodb文件(主要是Myisam表)的备份,这个过程中数据库将进入只读状态。
innobackupex拷贝完所有非Innodb文件后,通知xtrabackup,同时innobackupex进程进入等待状态。
xtrabackup收到innobackupex通知后,停止redo拷贝线程,并通知innobackupex redo拷贝完成。
innobackupex解锁,执行unlock tables。
进行收尾工作,释放资源,写备份元数据,innobackupex等待xtrabackup进程退出后退出。
下图为完整的备份流程:
对于备份的比较,Oracle的热备可以说是全城对数据库服务可用性无影响的,而MySQL的热备对于非Innodb数据的备份非常不友好,加锁时间长短视数据大小而定,因此这也是我们一直强调使用Innodb引擎的原因之一。当然,即使全部均为Innodb表,在最后备份表结构信息frm文件的过程中也会短暂加锁,所以还要根据业务敏感程度来控制备份过程在交易低峰时段完成。

数据复制
为了实现故障场景下数据的RPO,采取的方式通常分为两类,一类是通过硬件技术,依靠存储对数据进行复制,存储级复制与数据库产品类型无关。而另一类则是通过数据库自身的复制技术达到数据实时复制的目的,不同的数据库产品有着其各自的机制与特点。
Oracle数据库复制依靠Data guard机制实现,该机制中应用最广泛的配置原理是通过LGWR进程在把日志写到本地联机日志的同时,还发送一份给本地的LSN进程,该进程再将日志内容通过网络发送至备库,当LGWR进程配置为SYNC同步模式时,LGWR必须等待写入本地联机日志和LSN进程传送成功,主库的事物才能提交,而备库的RFS进程在收到日志内容后会立即写入standby redo log并由MRP进程完成介质恢复。整个过程如下图所示:
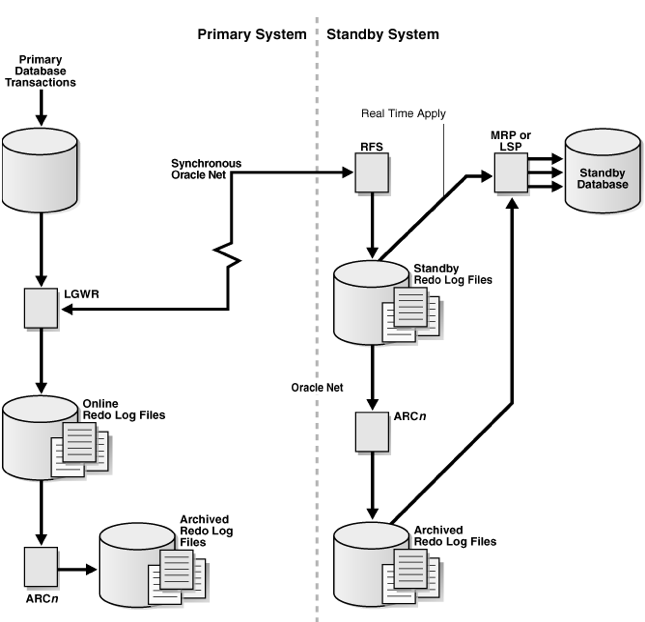
在这样的工作原理下,Oracle的备库在实时重演着主库的活动事务,若主库回滚则备库开始回滚,若主库提交则备库立即提交,因此主备库之间即使在LGWR的ASYNC异步模式下,也很少会出现较高的数据延时。
MySQL数据库在数据复制的过程中主要靠3个线程来完成,分别是binlog dump thread,I/O thread以及SQL thread。当主库发生写操作并commit时,其事件会写入binlog文件,并创建log dump线程告知从库。主库I/O线程会将binlog名称和当前更新的位置同时传给从库的I/O线程,从库I/O线程会将复制过来的binlog副本存入relay log,最后SQL线程检测到relay log有更新后开始将事件进行重演,完成数据同步。整个过程如下图所示:
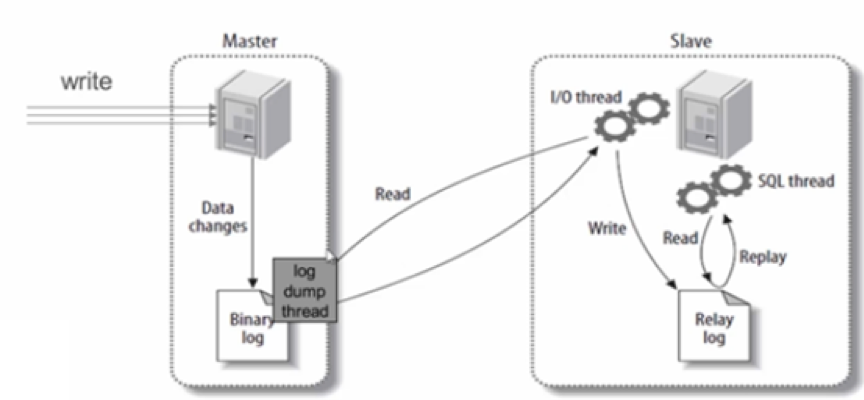
对比Oracle与MySQL的数据复制,我们可以看出两者最大的技术区别在于:Oracle在写redo的过程中就完成了复制,而MySQL在发起commit操作时才会写binlog并开始复制,这也是MySQL复制过程中非常容易造成复制延时的原因。因此,我们经常强调MySQL数据库中的大事务一定要分割处理,大事务带来的风险除了较高的数据延时外,还存在着大量binlog快速生成并传输时对网络冲击的流量风险。
MySQL作为一款轻量级的开源数据库产品,很多功能或机制还在不断的演进完善中,在使用MySQL进行开发设计的过程中,应参照开发设计指引,合理的创建表及索引等对象,选择并使用恰当的列类型。同时减少大事务的出现或者说对大事务进行提前的规划分隔处理。复杂业务逻辑的实现也不应依赖存储过程,自定义函数,触发器,而是需要靠近程序测进行处理。很多同类型的基础软件有着不少功能或特性上的相似之处,但之间又存在或大或小的差别,所以在基础软件替换时,应从差异的角度去评估生命周期管理的变化,从而更好的完成开发、测试已经上线运维等不同阶段的工作。
作者 | 于树文
视觉 | 谭 畅
统筹 | 邸雅楠



