




爬虫出现在哪?爬虫案例
可以从下图看出看出,整个爬虫的流量分布。即那些行业被“爬”的最多。
1、排名第一的即是出行
大家可能会想为什么出行会吸引这么多的爬虫程序,主要的原因也就一个——抢票软件(抢票软件的本质就是爬虫)。
说起抢票软件的目标,首当其冲的就是12306,出行的爬虫中,有89.02%的流量都是冲着 12306 去的。
据12306公开数据显示,过年最高峰时总的页面浏览量达813.4亿次、平均每秒164.8百万次。
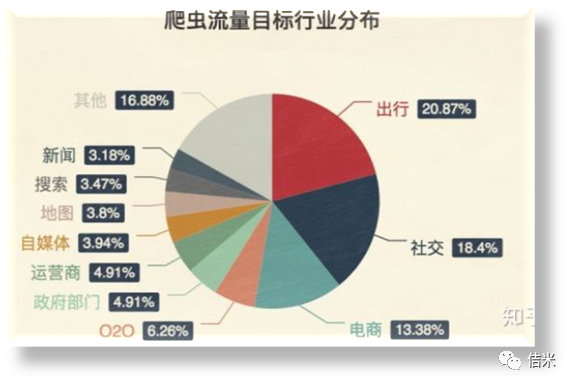
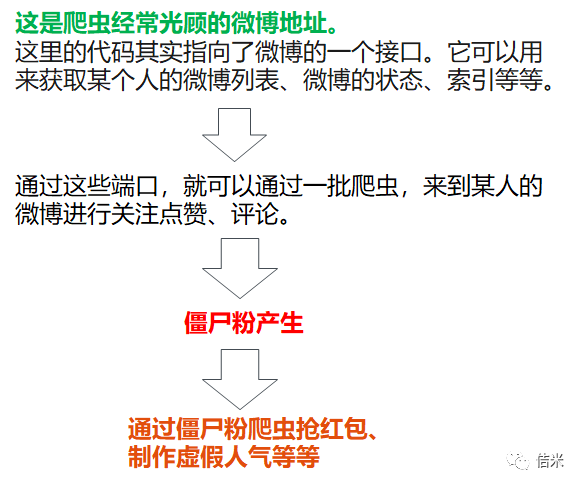
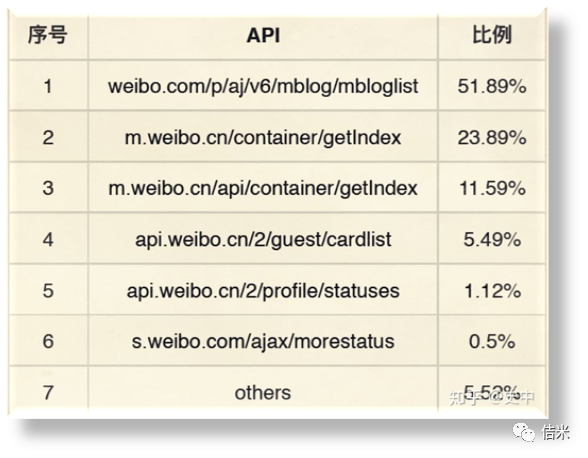
2、排名第二的社交网站也是各个爬虫的聚集地
为什么爬虫特别喜欢光顾社交软件呢
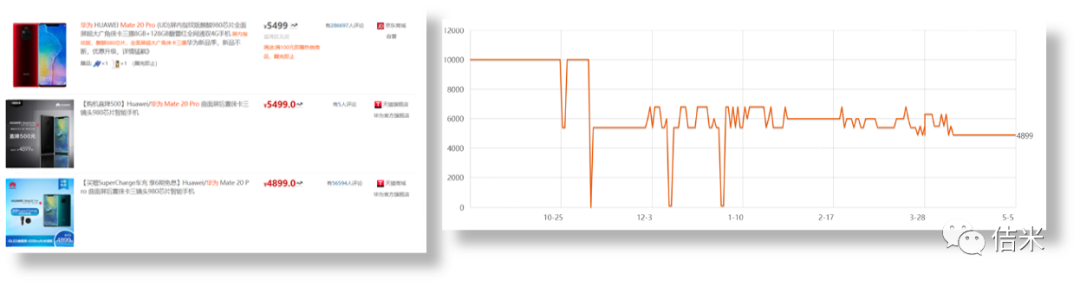
•3、排名第三的是各大电商平台
通过爬取各大电商平台(淘宝、京东,还有唯品会苏宁易购)的产品信息(品牌、价格、图片、评价等)。
然后汇集在一个平台上,方便用户对比价格,而且不光可以比较不同平台、不同店铺同一产品的价格、也可以比较同一家店铺这一产品不同时段的价格。

反爬虫与反反爬虫
•网站被爬虫爬取数据,大都是不乐意的。•因为一方面爬虫会导致网站被访问量短时间内迅速增加,那这样服务器发包给普通用户的速度必然就会被拖慢。就像12306那样,节假日访问速度由于爬虫程序的占流会放慢许多。
•另一方面,各大网站的数据都是核心竞争力,被爬虫爬取了之后,无成本的利用,总会有所不甘心。于是,反爬虫技术应运而生:
•初级反爬虫:通过Headers反爬虫•••••
从用户请求的Headers反爬虫是最常见的反爬虫策略,很多网站都会对Headers的User-Agent进行检测。
如何反反爬虫:如果遇到了这类反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中。对于检测Headers的反爬虫,在爬虫中修改或者添加Headers就能很好的绕过。
•中级反爬虫:基于用户行为反爬虫(具体策略验证码,封IP等)
一种情况是,服务器检查到你登陆异常(短时间多次登陆),就会让你识别验证码来判断你是真实用户还是爬虫程序。这样自然能够一定程度上拦下爬虫程序,因为程序可没有识别图片的编码。
另一种情况是,服务器判断你这个IP短时间内多次访问,是异常IP就会直接不给你返包。用通俗语句来说就是服务器判断你是个爬虫程序,你问服务器要网站资源,被服务器无情拒绝了。
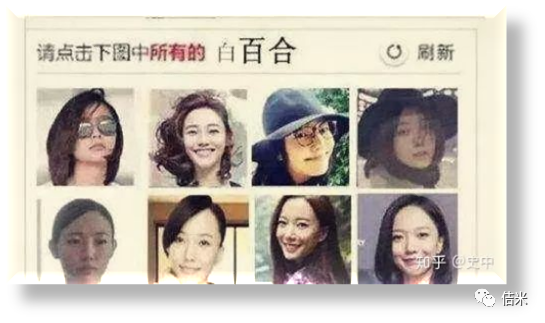
如何反反爬虫:面对图片验证码,一方面可以通过机器学习来让爬虫程序识别图片。另一方面可以通过实时变换IP地址来让服务器难以识别到你的异常状态。
•高级反爬虫:动态反爬(字体反爬、防调试、JS验证后跳转等)
•现在的高级反爬虫技术集中在前端领域,有对于HTML里面的文本进行加密;使用动态js呈现内容;阻止爬虫技术员打开控制台等等。
•新型反爬技术层出不穷,爬虫技术员与反爬技术员斗智斗勇,所以没有万全的反反爬虫技巧,只有在不断的与反爬虫技术员的斗智斗勇中提升自己的技巧才是万全之策。
•对爬虫欢迎的网站及ROBOT协议
•其实不是所有网站都对爬虫抗拒,也有对于爬虫欢迎的网站;或者说网站的某一部分内容欢迎爬虫。那么如何识别那些网站欢迎爬虫、那些不欢迎爬虫呢?
•这时候就要查看网站的ROBOT协议,比如我们在京东的官网末端输入“robots.txt”,然后就会在“https://www.jd.com/robots.txt”看到这样一些描述。这些就是网站告诉你,那些能爬、那些不能爬。
