




昨天我们体验了一下Oceanbase,主要是对其与oracle的兼容性和行锁方面做了一些简单的测试。今天我们要跑Benchmark的OceanBase数据库是一个单机的测试环境,实际上一般部署OB至少也是3个节点或者更多。对于这种支持多租户的数据库,节点数多多益善。我们这个只能在功能上做一些验证了。我这台服务器CPU挺强劲,是INTEL E8 18核的6150,两路服务器有36个2.7G主频的核,72线程。不过物理内存只配了64G。这种配置对于OceanBase这样的LSM-TREE存储引擎的数据库来说,有点不够。因此我们今天的压测也不是一种极限形式的Benchmark测试,而是分析下OceanBase在这种高负载简单交易场景下的性能特点。从而发现Oceanbase使用中的一些优化要点。
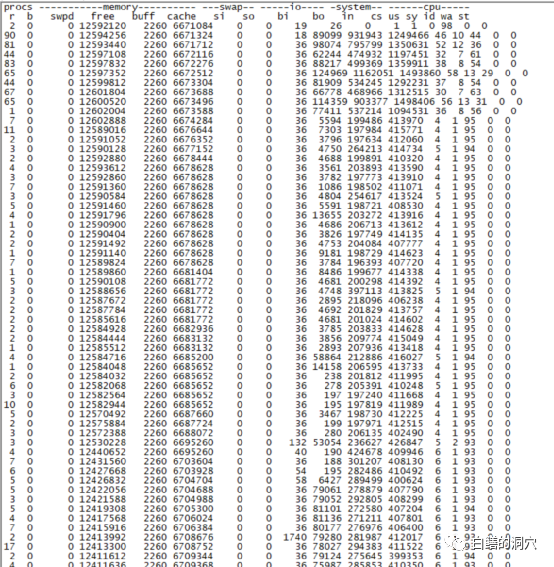
和其他数据库相比,在做Benchmark 的DatabaseBuild的时候,OceanBase的资源开销明显要高于其他的数据库,这和LSM-TREE本身的特点是有关的。可以看到,在Load Item表的时候,CPU最高飙升到了70%以上,在后续的装载过程中,仍然会出现一些高峰。
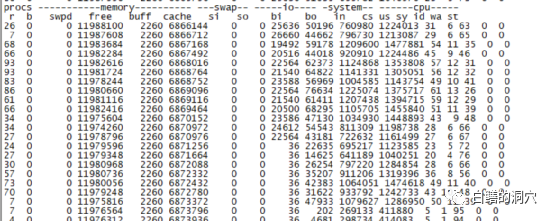
通过分析我们发现,和CPU高峰同时存在的是大量的IO,也就是说memstore写盘的时候会消耗较大的CPU资源,这个是不是与写盘时出现了Merge操作有关,我们今后再去慢慢探索。LSM-TREE的CM操作是十分消耗CPU与IO资源的。

Benchmark的配置文件我们就选了了Oracle,只是驱动程序使用了OB提供的jdbc驱动,终端数设置为300,其他参数都使用标准参数。在DatabaseBuild的时候,使用了Benchmark标准的方式,未作任何修改。
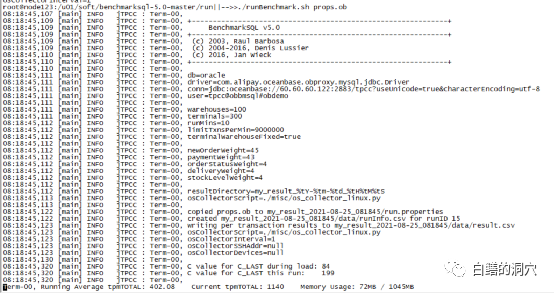
没想到刚开始压测就感觉不对劲,在这台服务器上跑Benchmark哪怕没怎么优化好,也应该是几万起步的,怎么才是几百呢?肯定哪里出了问题。
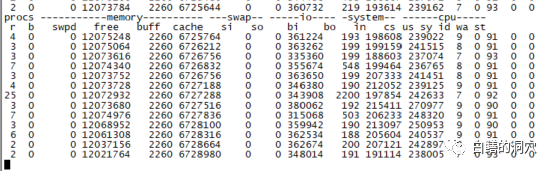
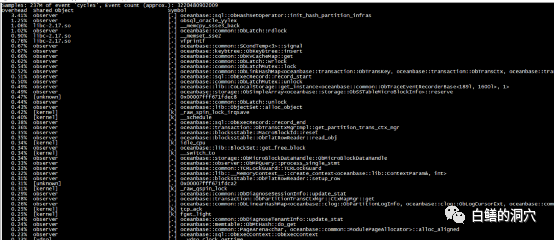
再看数据库服务器上的负载很低,可以说鸡不说没啥负载,读IO量倒是蛮大的。写IO很小。我们再来看看perf top的情况。
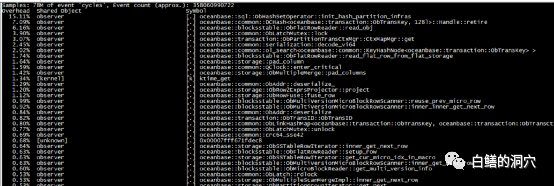
系统调用上看,好像和Ob内部Hash操作相关的争用比较严重。我突然想起以前看过的一个关于OB做Benchmark测试优化的文章。根据这个文章的指示,需要对BMSQL的表结构做一些调整。
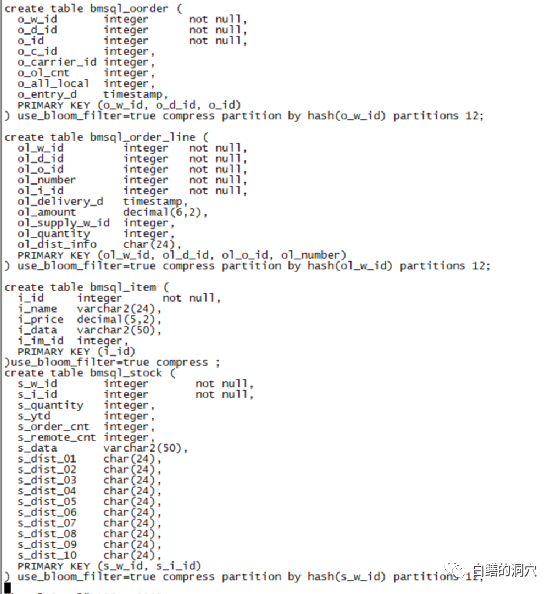
我们看到对于一些大表,主要的处理手段为HASH分区,还有就是使用bloom过滤器和压缩分区。在表上使用bloom过滤器是个什么鬼?看到这里大家可能会觉得有些不解了。前阵子老白写过一篇关于PG的bloom索引的文章,难道OB在表上也创建了bloom索引吗?以前在研究HBASE的时候也看到过通过布鲁姆过滤器来优化随机读的性能。其原理是在列上面生成一个独立的Bloom索引文件。因为Becnmark测试主要是等于操作基本上没有范围扫描,因此布鲁姆过滤器对这种场景的优化还是挺明显的。不过增加了use_bloom_filter属性后,会大大增加数据写入的开销。因此DatabaseBuild过程变长了好几倍。在OB中还有Bloom Cache来进一步优化Bloom过滤器的性能,我想今后在开发Ob应用的时候,应该认真研究一下Bloom过滤器。
因为我们的测试环境配置过低的问题,我们并没有对OB做真正的基线测试,不过通过这个测试我们也意识到一个问题,对于OB的使用,不是简单的把Oracle数据库迁移过来就行了,虽然OB和ORACLE的兼容度比较高。如果不能掌握OB的高级优化技巧,在建表、系统参数调整,CM相关的配置上做好响应的优化,数据库性能是很难得到保障的。这也是为什么对OB的评价在互联网上有两个极端,一个是OB很强,一个是OB很渣。实际上,除了Oracle能相对比较轻松的使用大多数应用场景外,目前的国产数据库无论接口做的如何接近,但是实际上本质上对优化的要求都是比较高的。如果我们不能在数据逻辑建模、数据物理建模、应用开发以及数据分布策略等方面做扎实的工作,想用好OB这样的分布式数据库还是有一定的难度的。这实际上也是DBA表现自己的机会来了。
