




公众号后台回复“学习+JavaSE”,即可免费获得学习资料

前言:本公众号将推出系列性的知识分享,以专题或者模块的方式,向读者分享学习体会和心得。所以想要学习的朋友可以点击关注,一起学习。
上一篇介绍了hadoop环境的单机版的搭建过程,今天主要介绍大家在学习中常用的伪分布式的搭建流程。
配置文件的修改
etc/hadoop下面的五个文件hadoop-env.shcore-site.xmlhdfs-site.xmlmapred-site.xmlyarn-site.xml
core-site.xml的配置(根据自己的版本来配置)
在configuration中添加以下内容<!-- 指定HDFS中NameNode的地址 --><property><name>fs.defaultFS</name><value>hdfs://hadoop101:9000</value></property><!-- 指定Hadoop运行时产生文件的存储目录 --><property><name>hadoop.tmp.dir</name><value>/opt/module/hadoop-2.7.2/data/tmp</value></property>
hadoop-env.sh的配置
1.获取java的路径:echo $JAVA_HOME2.找到java_home3.配置 export JAVA_HOME=/opt/module/jdk1.8.0_192

hdfs-site.xml的配置
<!-- 指定HDFS副本的数量 ,默认是value 3 即有3个副本,即使有一个坏掉了,就会即可再次增加一个节点。--><property><name>dfs.replication</name><value>1</value></property>
启动集群
1.格式化NameNode(第一次启动时格式化,以后就尽量不要格式化)
bin/hdfs namenode -format
在格式化的过程中,如果有提示你要确认才可以格式化,那么就是该目录下的data文件夹里面有东西没有删除掉。
2.启动namenode
sbin/hadoop-daemon.sh start namenode #hadoop-daemon.sh是hadoop的守护进程,可以启动hadoop的namenode和datanode
3.查看是否启动成功
jps # java 的进程
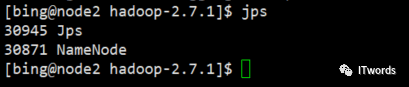
启动成功。
4.启动datanode
sbin/hadoop-daemon.sh start datanode
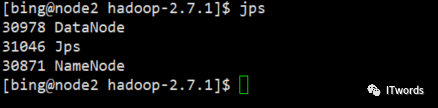
启动成功。
5.查看是否可以工作
访问HDFS的web界面,网址:http://192.168.100.102:50070
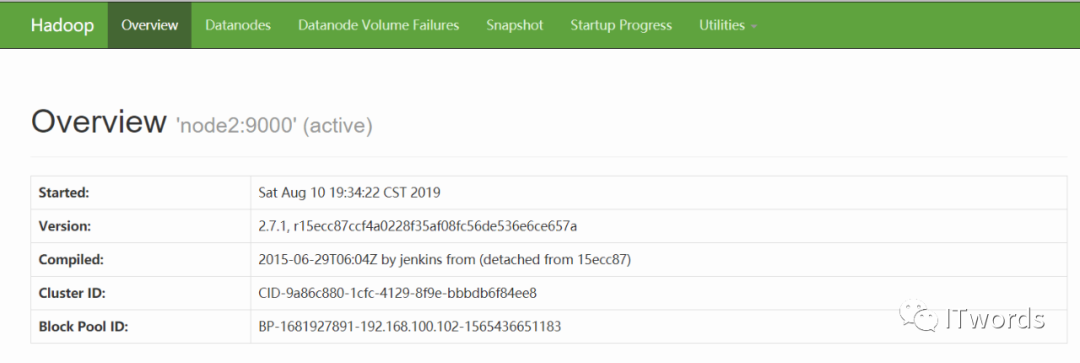
创建文件,在web中查看访问
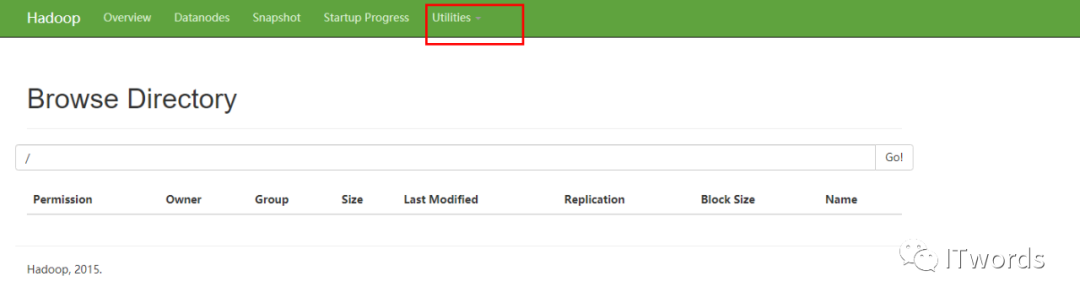
bin/hdfs dfs -mkdir -p /user/bingx/input # 创建的目录其中:bin/hdfs dfs 是固定的写法 后面可以写linux的命令,但是要加 -
6.将本地的文件上传到hdfs
bin/hdfs dfs -put wcinput/wc.input user/bingx/input
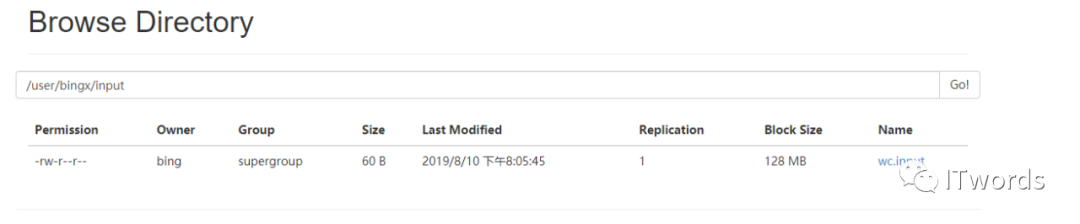
成功。
在hdfs上面运算wordcount
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar wordcount user/bingx/input user/bingx/output # user/bingx/output 依旧不可以存在
跑完以后会在hadoop的web端显示。

成功。
或者使用命令查看。
bin/hdfs dfs -cat user/bingx/output/p*
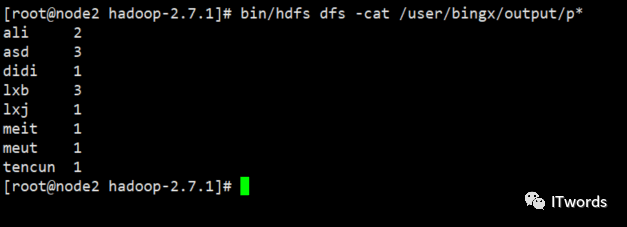
伪分布式再次格式化节点
(1)首先查看有关的所有的进程是否全部关掉。
jps
(2)将data和logs删除掉
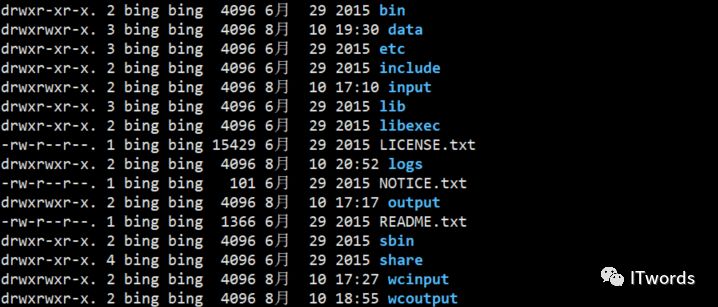
(3)格式化
bin/hdfs namenode -format
(4)为什么不可以频繁的格式化namenode
格式化namename节点,会产生新的集群id,导致namenode和datanode的集群id不一致,集群找不到以往数据。所以,格式化,namenode时,一定要先删除data数据和log日志,然后在格式化。
启动yarn并运行mapreduce程序
1.配置文件
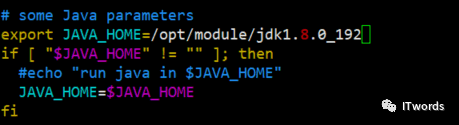
(1)配置yarn-env.sh
配置的就是java_home路径
vim yarn-env.sh
(2)配置yarn-site.xml
vim yarn-site.xml
配置项:
<!-- Reducer获取数据的方式 --><property><name>yarn.nodemanager.aux-services</name><!-- 获取数据的方式为 shuffle --><value>mapreduce_shuffle</value></property><!-- 指定YARN的ResourceManager的地址 放在哪个服务器--><property><name>yarn.resourcemanager.hostname</name><!--注意修改主机名--><value>hadoop101</value></property>
(3)配置mapred-env.sh
配置是java_home
export JAVA_HOME=/opt/module/jdk1.8.0_192
(4)修改名称,mapred-site.xml.template修改为mapred-site.xml
mv mapred-site.xml.template mapred-site.xml
添加内容:
<!-- 指定MR运行在YARN上 --><property><name>mapreduce.framework.name</name><value>yarn</value></property>
2.启动集群
(1)检查namenode和datanode是否已经启动了,如果没有启动先启动。
sbin/hadoop-daemon.sh start namenodesbin/hadoop-daemon.sh start datanode
(2)启动ResourceManager(102上启动)
sbin/yarn-daemon.sh start resourcemanager
(3)启动NodeManager
sbin/yarn-daemon.sh start nodemanager
192.168.100.102:8080/cluster
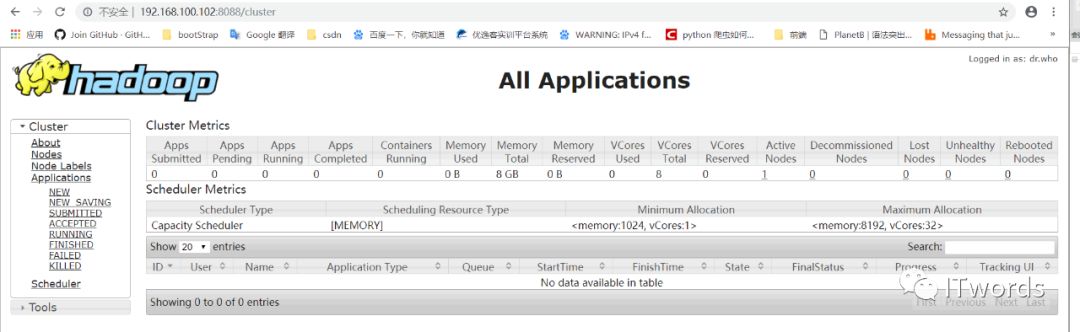
(4)检查在Hdfs中如果要在同一路径下面生成一样的文件,比如output等,需要将其删除。
hdfs dfs -rm -r user/bingx/output
(5)运行
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar wordcount /user/bingx/input /user/bingx/output
运行成功,表示你的伪分布式的环境搭建成功。
今天的内容到这里就结束了,喜欢大数据的同学,赶紧操作一波吧,有问题可以给我后台留言,如果环境还有问题的同学,可以查看往期的文章,先进行环境的搭建。
喜欢的同学可以点击“在看”,并且关注ITwords微信公众号,第一时间获取更新内容。您的转发和点赞将是我原创的动力,感谢您的支持。

尾言:下一篇介绍hadoop的完全分布式的搭建
往期回顾:

