




前言
前三节我们掌握了模型和数据,这节我们将通过优化数据参数来训练,验证和测试模型。训练模型是一个迭代过程;每次迭代(称为epoch),模型对输出进行预测,计算其预测误差(loss),收集误差相对于其参数的导数,使用梯度下降优化参数
Prerequisite Code
首先从前两节中Datasets & DataLoaders和Build Model部分加载代码
import torchfrom torch import nnfrom torch.utils.data import DataLoaderfrom torchvision import datasetsfrom torchvision.transforms import ToTensor, Lambdatraining_data = datasets.FashionMNIST(root="data",train=True,download=True,transform=ToTensor())test_data = datasets.FashionMNIST(root="data",train=False,download=True,transform=ToTensor())train_dataloader = DataLoader(training_data, batch_size=64)test_dataloader = DataLoader(test_data, batch_size=64)class NeuralNetwork(nn.Module):def __init__(self):super(NeuralNetwork, self).__init__()self.flatten = nn.Flatten()self.linear_relu_stack = nn.Sequential(nn.Linear(28*28, 512),nn.ReLU(),nn.Linear(512, 512),nn.ReLU(),nn.Linear(512, 10),nn.ReLU())def forward(self, x):x = self.flatten(x)logits = self.linear_relu_stack(x)return logitsmodel = NeuralNetwork()
上述代码不做过多叙述,详情请参考前两节学习笔记。部分输出结果如下;
超参数
超参数是可调节的参数,可以控制模型优化过程。不同的超参数值会影响模型训练和收敛速度 我们为训练定义了以下超参数;
1.Number of Epochs 迭代数据集次数 2.Batch Size 参数更新之前通过网络传播的数据样本数量 3.学习率 在更新模型参数时,较小的值会影响学习速度,较大的值会导致训练过程中出现不可预测的情况。
learning_rate = 1e-3batch_size = 64epochs = 5
优化循环
设置超参数后,我们可以使用优化循环来训练和优化模型。优化循环每次迭代称为epoch 每个epoch由两部分组成:训练:迭代训练数据集并尝试收敛到最佳参数 验证/测试:迭代测试数据集以检查模型性能是否正在提高
损失函数
当使用训练数据时,未经训练的模型可能无法给出正确答案。通过损失函数衡量结果与目标值,目的是在训练过程得出最小化的损失函数。为了计算损失值,我们使用给定数据样本的输入进行预测,并将其与真实数据值进行比较。常见的损失函数包括用于回归任务的nn.MSELoss(均方误差)和用于分类的nn.NLLLoss(负对数似然)。nn.CrossEntropyLoss结合nn.LogSoftmax和nn.NLLLoss 我们将模型的输出logits传递给nn.CrossEntropyLoss,标准化logits并计算预测误差
# Initialize the loss functionloss_fn = nn.CrossEntropyLoss()
优化器
通过优化器在每个训练步骤中调整模型参数以减少模型误差。PyTorch将所有优化逻辑封装在optimizer中。在该模型中,我们使用SGD优化器。(ADAM和RMSProp适用于不同类型的模型和数据) 现在初始优化器;
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
Application
接下来我们定义train_loop来优化循环,并使用test_loop测试数据来评估模型的性能。
def train_loop(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset)for batch, (X, y) in enumerate(dataloader):# Compute prediction and losspred = model(X)loss = loss_fn(pred, y)# Backpropagationoptimizer.zero_grad()loss.backward()optimizer.step()if batch % 100 == 0:loss, current = loss.item(), batch * len(X)print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")def test_loop(dataloader, model, loss_fn):size = len(dataloader.dataset)num_batches = len(dataloader)test_loss, correct = 0, 0with torch.no_grad():for X, y in dataloader:pred = model(X)test_loss += loss_fn(pred, y).item()correct += (pred.argmax(1) == y).type(torch.float).sum().item()test_loss /= num_batchescorrect /= sizeprint(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
将损失函数和优化器初始化后,将其传递给train_loop,和test_loop。按照自己的需求去增加epochs的数量以跟踪模型改进效果。
loss_fn = nn.CrossEntropyLoss()optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)epochs = 10for t in range(epochs):print(f"Epoch {t+1}\n-------------------------------")train_loop(train_dataloader, model, loss_fn, optimizer)test_loop(test_dataloader, model, loss_fn)print("Done!")
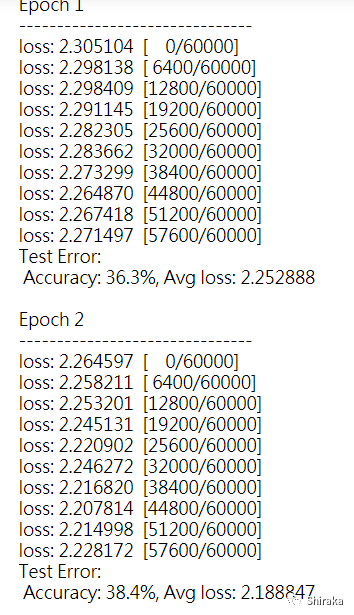
部分效果展示如下;
保存和加载模型
接下来将进行最后一步,保存,加载和运行模型
import torchimport torch.onnx as onnximport torchvision.models as models
保存和加载模型权重 PyTorch模型将学习到的参数存储在state_dict。可以通过torch.save方法保存模型
model = models.vgg16(pretrained=True)torch.save(model.state_dict(), 'model_weights.pth')
加载模型权重之前,需先创建相同模型的实例,使用load_state_dict() 方法加载参数
model = models.vgg16() # we do not specify pretrained=True, i.e. do not load default weightsmodel.load_state_dict(torch.load('model_weights.pth'))model.eval()
注意:在调用model.eval()要将dropout 批量归一化层设置为评估模式。
在加载模型权重时,需要实例化模型,可以将model传递给函数:
torch.save(model, 'model.pth')model = torch.load('model.pth')
将模型导出到ONNX
input_image = torch.zeros((1,3,224,224))onnx.export(model, input_image, 'model.onnx')
通过ONNX可以在不同平台和不同编程语言上运行该模型,详情使用方式请参考官方网站https://github.com/onnx/tutorials
结语
前四节学习如何通过PyTorch构建神经网络模型,优化,保存和加载模型。让我们对于深度学习和PyTorch有了初步了解。下一部分,我想在图像和视频角度进行学习。
推荐阅读
•微分算子法•使用PyTorch构建神经网络模型进行手写识别•使用PyTorch构建神经网络模型以及反向传播计算

