




对比学习在最近几年一直是各大顶级会议的热门议题。大规模标注数据有利于模型学到泛化的表征。尤其在计算机视觉中,过去几年,学界和业界都形成了两阶段的炼丹范式:首先基于大规模监督数据预训练,然后再到小领域数据集作微调。然而,高质量标注数据来之不易,尤其是在视频理解领域,视频的标注更为困难。因而,无监督/自监督的表示学习则显得尤为重要。
对比学习是一类无监督算法(这里的无监督是指没有人工提供的监督信号),旨在利用数据自身的结构来学习通用表征,从而助力下游任务。从19年到21年,对比学习在学术界有持续的演进,带来了许多新的认知。我们将会在这个系列里为大家一一分享。今天给大家带来MoCo[1]的分享。

这篇文章发表于2019年11月。主要有两个核心点,其一:引入队列使得batchsize可以突破GPU显存的限制;其二:独创性地提出动量encoder,使得队列内的特征一致性得到保证。
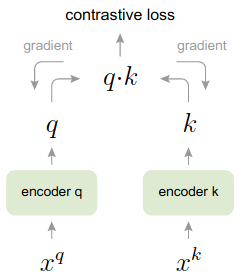
图1 朴素的对比学习示意图
我们首先回顾对比学习的背景。对比学习通过构造代理任务,利用数据自身的结构来学习数据的表征。代理任务往往首先人工启发式地设计增广样本,然后设计loss使得同个样本增广后的两个副本要彼此很相似。一种常见的loss是batch内的softmax,即增广后的某一个副本要和另一个副本相似,同时远离batch内的其他样本。
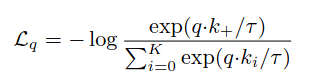
在2019年,学者们的认知是,对比学习需要大的batchsize,从而使得batch内的负样本更充分。但是batchsize会受限于GPU显存,难以进一步扩大。针对这点,之前已经有工作(memory bank)设计了一个负采样队列[2]。维护一个较大的队列,负样本从队列中采样,这样负采样就与batchsize解耦了。
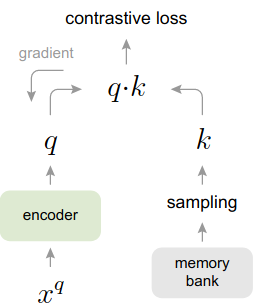
图2 memory bank示意图
队列内样本特征存在一致性问题:队列内的样本特征需要在一个空间内,这样才具有可比性(如果队列里的样本,有一半是模型在step1时产生的,有另一半是在step100时产生的,那么特征一致性很差)。解决此问题的一种朴素思路是每间隔一段时间把队列内的样本特在重刷一遍。但该方法效率堪忧。为此,MoCo提出了动量encoder的方法,实现了较为高效的保持队列特征一致性的方法。具体来说,产生队列特征的encoder通过动量的方式来缓慢地想着左侧参与训练的encoder参数靠近。公式如下:
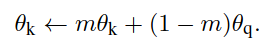
作者在实验中发现,m=0.999的时候效果最好。也就是说,动量encoder以极其缓慢的速度更新,实现了队列内样本特征的相对一致性。
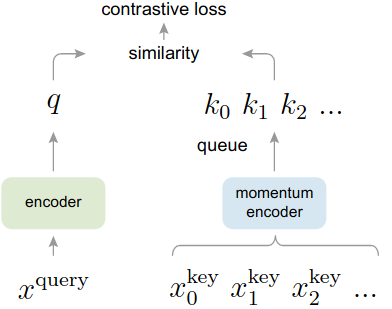
图3 MoCo
不得不说,MoCo符合恺明大佬一贯的风格:simple & elegant。通过动量更新encoder的方式,使得队列内特征的一致性得到了保证。即突破了batchsize的限制,又提升了效率。
参考文献
