




图像分类网络作为计算机视觉的最基础任务,在过去的10年中被广泛的研究,像3X3的小核、残差结构,Inception模块,BN、Depthwise卷积等屡试不爽的经典算法都是在这个时间段被提出的。所以了解图像分类模型的演化史可以帮助大家更好的进行后续任务的迭代。
另外图像分类的模型结构,作为Backbone也被后面很多的任务吸取进去作为基础的视觉特征提取器。因此对于后续的目标检测、分割算法也有很大的指导意义。
6.1 MobileNet V1
MobileNet V1 理解起来就是对 Depthwise Separable Convolution 的加强使用。
结构上同 Xception 的区别在于,这里每个卷积之后都有 BN + ReLU 单元,如 Figure 30 所示。
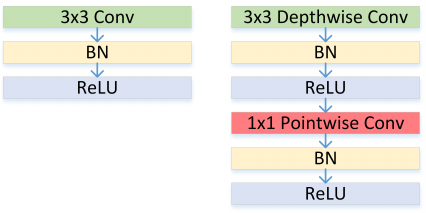
图30: Left: Standard convolutional layer with batchnorm and ReLU. Right: Depthwise Separable convolutions with Depthwise and Pointwise layers followed by batchnorm and ReLU.
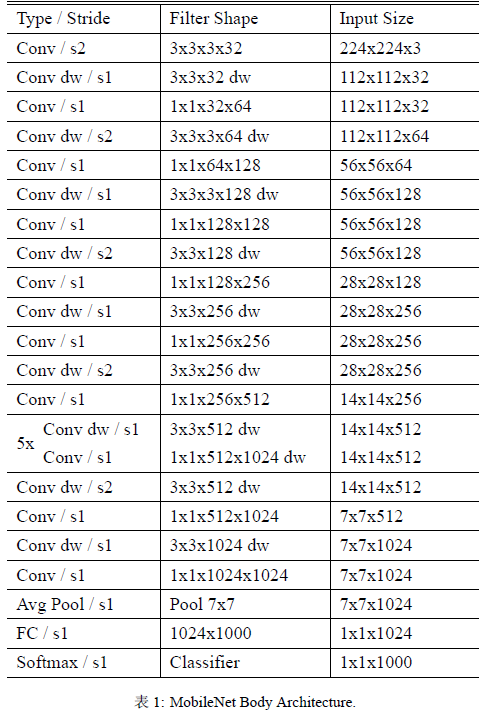
不考虑最后用来分类的全连接层,网络一共有 {\color{red}28} 层(DW 和 PW 单独作为一层来统计),具体见 Table 1。
由于 DW 的计算量较低,因此几乎所有(95% of the computation time and 75% of the parameters)的计算量都集中于密集的 1×1 PW 里。特别的,与训练大型模型相反,这里使用较少的正则化和数据增强技术,因为小型模型的过拟合问题较少。训练策略基本上同 Inception V3,但作者建议较少甚至不使用 weight decay (l2 regularization) 在 DW 中,因为这个层的参数本来就很少了。
文中引入了两个超参数 𝛼 和 𝜌。
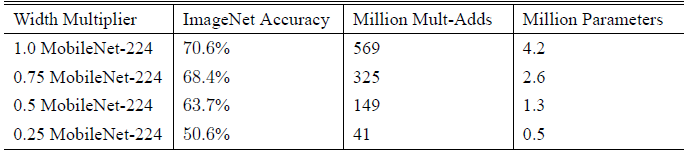
1. 𝛼是个 width multiplier, 目的是降低 feature map 的宽度(channel)以减少计算复杂度和参数数量的作用,其取值范围为 (0,1], 其中 𝛼=1 代表 baseline MobileNet。Table 2 对比了 width multiplier 𝛼大小对网络性能的影响:
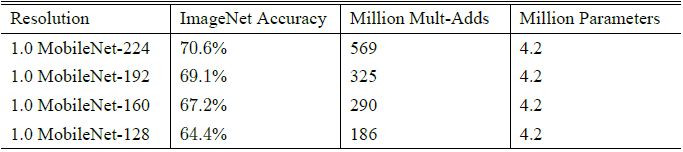
2. 𝜌 是个 resolution multiplier, 目的是降低 imput image 的尺度以减少计算复杂度和参数数量的作用,其取值范围为 (0,1] 其中 𝜌=1 代表 baseline MobileNet。Table 3 对比了 resolution multipliers 𝜌 大小对网络性能的影响:
6.2 MobileNet V2
MobileNet V2 则可以理解为 Depthwise Separable Convolution + ResNet。
在最早的 Network in Network 工作中, 1x1 PW 卷积被作为一个降维的操作而引入,后来逐渐发展为 Depthwise Separable Convolution 并被广泛应用,堪称跟 skip-connection 同样具有影响力的网络部件。在 Inception 单元最初提出之时,认为具有较多 channel 的 feature map 是可以压缩的,作者引入 PW 卷积将它们映射到低维(较少 channel 数)空间上并添加多路径处理的范式。之后的 Xception、MobileNet 等工作则将可分离卷积应用到极致:前者指出可分离卷积背后的假设是跨channel相关性和跨spatial相关性的解耦,后者则利用可控的两个超参来获得在效率和精度上取得较好平衡的网络。
6.2.1 Linear Bottlenecks
文中,经过激活层后的张量被称为兴趣流形,具有维HxWxD,其中D即为通常意义的channel数,部分文章也将其称为网络的宽度(width)。
根据之前的研究,兴趣流形可能仅分布在激活空间的一个低维子空间里,利用这一点很容易使用 1x1 PW 卷积将张量降维(即 V1的工作),但由于ReLU的存在,这种降维实际上会损失较多的信息。作者做了一个信息重构的实验,实验结论就是:激活函数在高维空间能够有效的增加非线性,而在低维空间时则会造成较大的信息损失。如下图 Figure 31 所示:当原始输入维度数增加到 15 以后再加 ReLU,基本不会丢失太多的信息;但如果只把原始输入维度增加至

图31: Examples of ReLU transformations of low-dimensional manifolds embedded in higher-dimensional spaces. In these examples the initial spiral is embedded into an
6.2.2 Depthwise Separable Convolutions
作者通过图 Figure 32 描述了深度可分离卷积的演化史:Figure 32(a) 中普通卷积将 channel 和 spatial 信息同时进行映射,参数量较大;Figure 32(b) 为可分离卷积,解耦了 channel 和 spatial,有一定比例的参数节省;Figure 32(c) 中进行可分离卷积后又添加了 bottleneck,映射到低维空间中;Figure 32(d) 则是从低维空间开始,进行可分离卷积时扩张到较高的维度(前后维度之比被称为expansion factor,扩张系数),之后再通过1x1卷积降到原始维度。
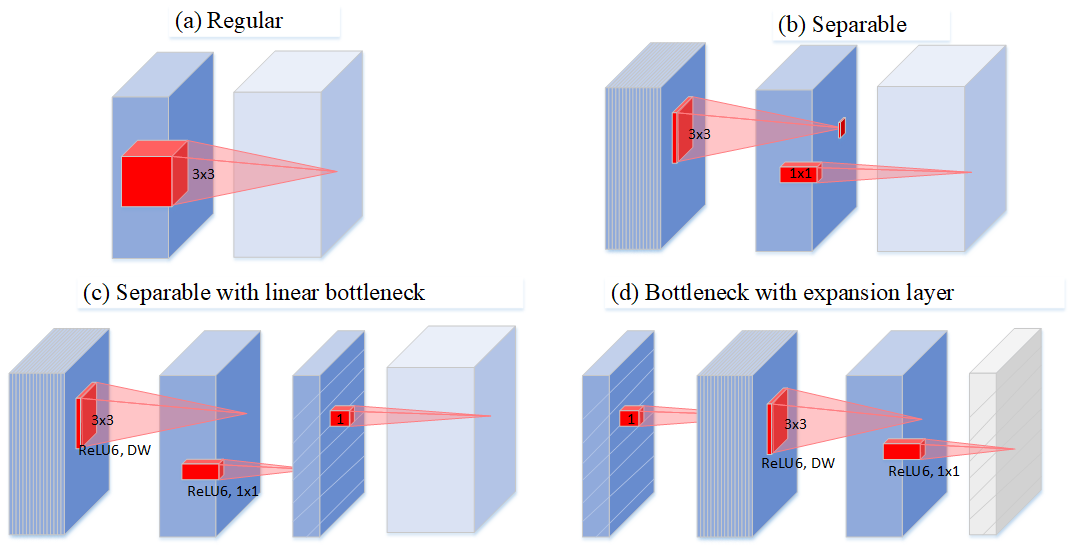
图32: Evolution of separable convolution blocks. The diagonally hatched texture indicates layers that do not contain non-linearities. The last (lightly colored) layer indicates the beginning of the next block. Note: 2d and 2c are equivalent blocks when stacked. Best viewed in color.
继续上面信息损耗的话题,深度可分离卷积大大降低参数量的同时也带来了信息损失的风险。V2 采用了 Figure 22(d) 的类似结构(区别在于最后一层无激活函数),考虑到 DW 卷积的计算特性决定它自己没有改变通道数的能力,因此,给每个 DW 之前都配备了一个 PW,专门用来升维,定义升维系数
6.2.3 Inverted Residuals
为了提升网络结构的性能,综合上面的两个改进,作者还引入了ResNet结构,构成了作者所说的 Inverted Residual,如 Figure 33(b) 所示。
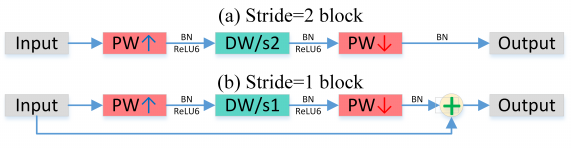
图33: Mobilenet V2.
以前大多数的模型结构加速的工作都停留在压缩网络参数量上。其实这是有误导性的:参数量少不代表计算量小;计算量小不代表理论上速度快(带宽限制)。ResNet 的结构其实对带宽不大友好:旁路的计算量很小,eltwise+ 的特征很大,所以带宽上就比较吃紧。而 Inverted residual 由于 eltwise+ 的特征较小的原因,缓解了这一问题。
6.2.3 Network
整个 V2 的网络结构,如 Table 4 所示:
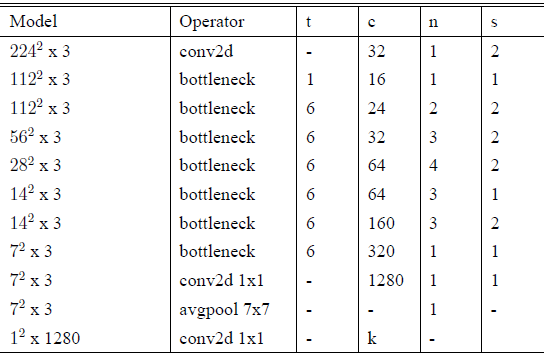
表4: MobileNetV2 : Each line describes a sequence of 1 or more identical (modulo stride) layers, repeated n times. All layers in the same sequence have the same number c of output channels. The first layer of each sequence has a stride s and all others use stride 1. All spatial convolutions use 3x3 kernels. The expansion factor t is always applied to the input size by first PW.
关注「OnekeyAI」公众号,后台回复「视觉模型」,获取相关代码和测试数据。保持联系,及时了解更多后续内容。
 好消息:相关代码、数据已集成在Onekey平台,如需购买Onekey移动AI平台「长按QR码识别」,案例需要单独购买,可以通过关注公众号后,在底导购买。
好消息:相关代码、数据已集成在Onekey平台,如需购买Onekey移动AI平台「长按QR码识别」,案例需要单独购买,可以通过关注公众号后,在底导购买。
