




图像分类网络作为计算机视觉的最基础任务,在过去的10年中被广泛的研究,像3X3的小核、残差结构,Inception模块,BN、Depthwise卷积等屡试不爽的经典算法都是在这个时间段被提出的。所以了解图像分类模型的演化史可以帮助大家更好的进行后续任务的迭代。
另外图像分类的模型结构,作为Backbone也被后面很多的任务吸取进去作为基础的视觉特征提取器。因此对于后续的目标检测、分割算法也有很大的指导意义。
2.1 Inception
在最初的版本 Inception/GoogleNet,其核心思想是利用多尺寸卷积核去观察输入数据。举个栗子,我们看某个景象由于远近不同,同一个物体的大小也会有所不同,那么不同尺度的卷积核观察的特征就会有这样的效果。于是就有了如下的网络结构图:
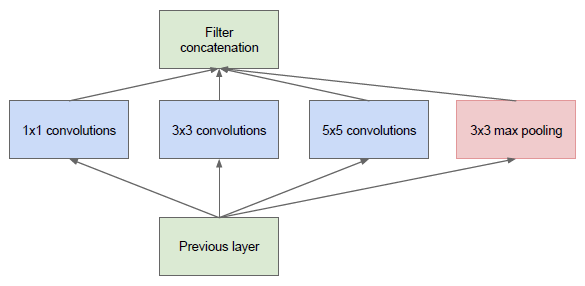
图1: Inception module, naive version
于是我们的网络就变胖了,通过增加网络的宽度,提高了对于不同尺度的适应程度。但这样的话,计算量有点大了。
2.2 Pointwise Conv
为了减少在上面结构的参数量并降低计算量,于是在 Inception V1 的基础版本上加上了 1x1 卷积核,这就形成了 Inception V1 的最终网络结构,如 Figure 2。

图2: Inception module with dimension reductions
这个 1x1 卷积就是 Pointwise Convolution,简称 PW。利用它的目的主要是为了减少维度,还用于引入更多的非线性。
我们来简单计算下:假定上一层输出的 feature map 维度为 100x100x128,经过256个大小为 5x5 的卷积后,输出的 feature map 大小为 100x100x256。这里卷积参数为 256∗5∗5∗128=819,200。而假如上一层的输出先经过 32 个大小为 1x1 的卷积后,再经过256个大小为 5x5 的卷积,那么输出维度保持不变的情况下,卷积参数减少为 128∗1∗1∗32 + 32∗5∗5∗256=204,800,降低为原来的 204800/819200=1/4。
PW 主要用于数据降维,减少参数量。也有使用 PW 做升维的,在 MobileNet v2 中就使用 PW 将 feature map 的宽度扩张了6倍,丰富输入数据的特征。
2.3 Kernel Replace
Inception V2 和 V3 版本为了进一步降低卷积参数采用小卷积来替换大卷积,同 VGG 套路。
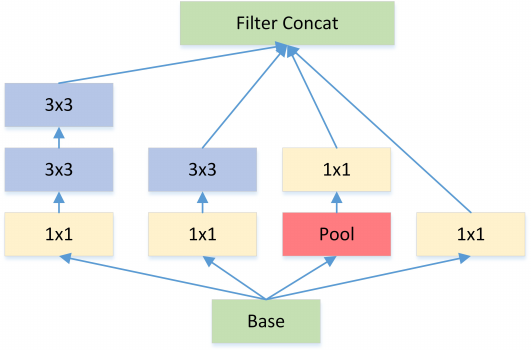
图3: Each 5×5 convolution is replaced by two 3×3 convolution
大尺寸的卷积核可以带来更大的感受野,但也意味着会产生更多的参数,比如 5x5 卷积核的参数有 25 个,3x3 卷积核的参数有 9 个,前者是后者的 25/9=2.78 倍。因此,GoogLeNet 团队提出可以用 2 个连续的 3x3 卷积层组成的小网络来代替单个的 5x5 卷积层,即在保持感受野范围的同时又减少了参数量。除了规整的的正方形,还有分解版本的 3x3 = 3x1 + 1x3,这个效果在深度较深的情况下比规整的卷积核更好(feature map 大小建议在 12 到 20 之间)。
2.4 Feature Map Downsample
一般情况下,如果想让图像缩小,可以有如下两种方式:
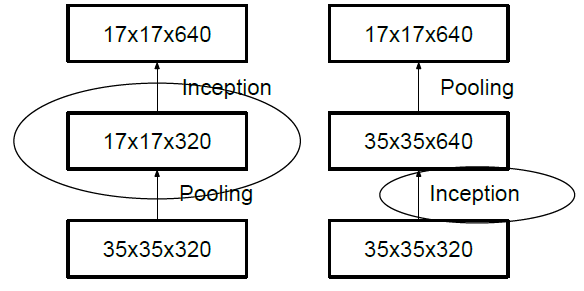
先 pooling 再作 Inception 卷积,或者先作 Inception 卷积再作 Pooling。前者先作 Pooling 会导致特征缺失遇到 bottleneck,后者则相对来说计算量更大。为了同时保持特征表示且降低计算量,将网络结构改为 Figure 5,使用两个并行化的模块来降低计算量(卷积、池化并行执行,再进行合并)。
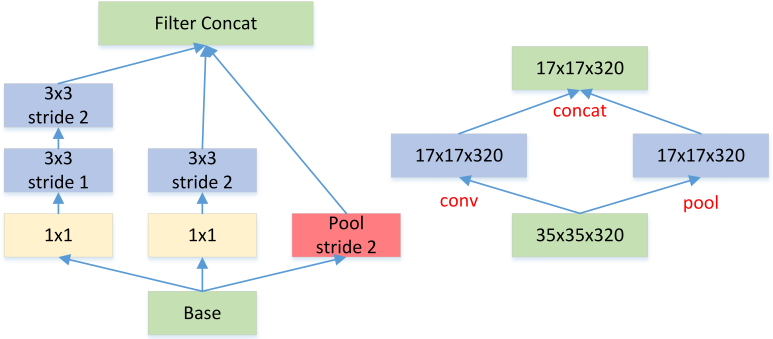
图5: Feature map Downsample
2.5 Bottleneck
Bottleneck 三步走:先 PW 对数据进行降维,再进行常规卷积,最后 PW 对数据进行升维,形如沙漏。
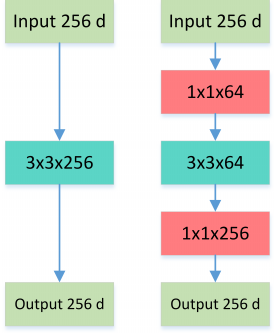
图6: Normal VS Bottleneck
这就是所谓的 Bottleneck 结构,上图中后者的计算量 256∗1∗1∗64+ 64∗3∗3∗64+64∗1∗1∗256=69,632远小于前者 256∗3∗3∗256=589,824。
2.6 Inception + ResNet
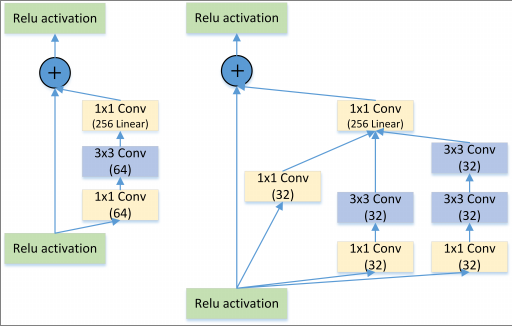
图7: Residual VS Residual+Inception
2.7 Group Conv Depthwise Separable Conv
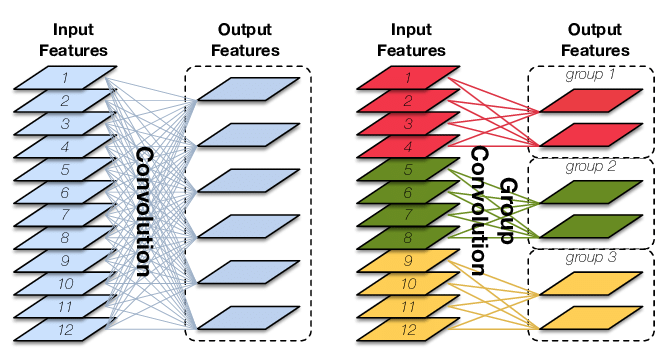
图8: Standard convolution (left) and group convolution(right). The latter enforces a sparsity pattern by partitioning theinputs (and outputs) into three disjoint groups
Group Conv 顾名思义,则是对输入 feature map 进行分组,然后每组分别卷积。假设输入 feature map 的尺寸仍为 𝐼x𝐻x𝑊,输出 Output Features 的通道数也是 𝑂,如果设定要分成 𝐺 个 groups,则每组的输入 feature map 数量为 𝐼/𝐺,每组的输出 feature map 的数量为 𝑂/𝐺,每个卷积核的尺寸为 𝐾x𝐾x𝐼/𝐺,每组的卷积核数量为 𝑁𝐺,卷积核的总数仍为 𝑂 个,卷积核只与其同组的输入 map 进行卷积,卷积核的总参数量为 𝑂∗𝐾∗𝐾∗𝐼/𝐺,可见,总参数量减少为原来的 1/𝐺,其连接方式如上图右所示,group1 输出 map 数为 2,有 2 个卷积核,每个卷积核的 channel 数为 4,与 group1 的输入 map 的 channel 数相同,卷积核只与同组的输入 map 卷积,而不与其他组的输入 map 卷积。
Group Conv 的用途包括:
减少参数数量,分成 𝐺 组,则该层的参数量减少为原来的 1/𝐺。
Group Conv 可以看成是一种structured sparse,每个卷积核的尺寸由 𝐾x𝐾x𝐼 变成了 𝐾x𝐾x𝐼/𝐺,这里可以将其余的 (𝐼-𝐼/𝐺x𝐾x𝐾) 维的参数视为 0。实际中,Group Conv 在减少参数量的同时有可能获得更好的效果(相当于正则})。
Depthwise Convolution 其实是 Group Conv 的一种特例,简称 DW。当分组数量等于输入 map 数量,输出 map 数量也等于输入 map 数量,即 𝐺=𝑂=𝐼,𝑂个卷积核每个尺寸为 𝐾x𝐾x1 时,Group Convolution 就成了Depthwise Convolution。Depthwise Separable Convolution 则是DW+PW 的组合体,如Figure 9,参见 Xception 等,参数量进一步缩减。

图9: Depthwise Separable Convolution
更进一步,如果分组数 𝐺=𝑂=𝐼,同时卷积核的尺寸与输入 map 的尺寸相同,即 𝐾=𝐻=𝑊,则输出 map 为 𝐼x1x1 即长度为 𝑂 的向量,此时称之为 Global Depthwise Convolution (GDC),见 MobileFaceNet,可以看成是全局加权池化,与 Global Average Pooling (GAP) 的不同之处在于,GDC 给每个位置赋予了可学习的权重(对于已对齐的图像这很有效,比如人脸,中心位置和边界位置的权重自然应该不同),而 GAP 每个位置的权重相同,全局取个平均,如下图所示:
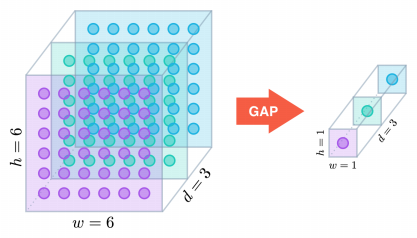
图10: Global Depthwise Convolution
2.8 Summary
多个不同尺寸的卷积核,提高对不同尺度特征的提取。
PW 卷积,降维或升维的同时,提高网络的表达能力。
多个小尺寸卷积核替代大卷积核,加深网络的同时减少参数量。
Bottleneck 结构,大大减少网络参数量。
DW 设计,再度减少参数量。
关注「OnekeyAI」公众号,后台回复「视觉模型」,获取相关代码和测试数据。保持联系,及时了解更多后续内容。
 好消息:相关代码、数据已集成在Onekey平台,如需购买Onekey移动AI平台「长按QR码识别」,案例需要单独购买,可以通过关注公众号后,在底导购买。
好消息:相关代码、数据已集成在Onekey平台,如需购买Onekey移动AI平台「长按QR码识别」,案例需要单独购买,可以通过关注公众号后,在底导购买。
