





在上一篇《「召回层」深度召回中的u2i》)中介绍了深度召回中的u2i方法。本文将介绍召回层模型的样本挖掘
方法。
预告:
下一篇将介绍召回层的评估方法。感兴趣的同学别忘了点个关注哦!
在推荐系统的召回层中,工业界大多采用多路召回从海量候选池中快速找到用户可能感兴趣的Item,然后将这些Item传给后续的粗排和精排层。向量化召回由于其高效的检索性能(需配合ANN检索)以及较强的表示能力(召回效果优于标签倒排、ItemCF等传统算法)而成为工业界主流。
关于如何生成向量,主流的是采用NN对Item或User进行Embedding(感兴趣的可以进一步阅读前两期的文章《「召回层」深度召回中的i2i》和《「召回层」深度召回中的u2i》)。
前面文章重点放在了生成embedding所用的模型架构,本文将关注于在实际应用中如何决定给模型输入什么样的训练样本,来使模型达到预期效果。下面以主流的双塔模型为例,介绍召回中的模型训练样本挖掘方法。
一、为什么要挖掘样本
对于为什么要挖掘样本,主要有两个方面:1)双塔模型的输入中需要针对每个正Item匹配相应的负Item,来构造<user, item+, item->
1、双塔模型
经典双塔模型如下图所示:
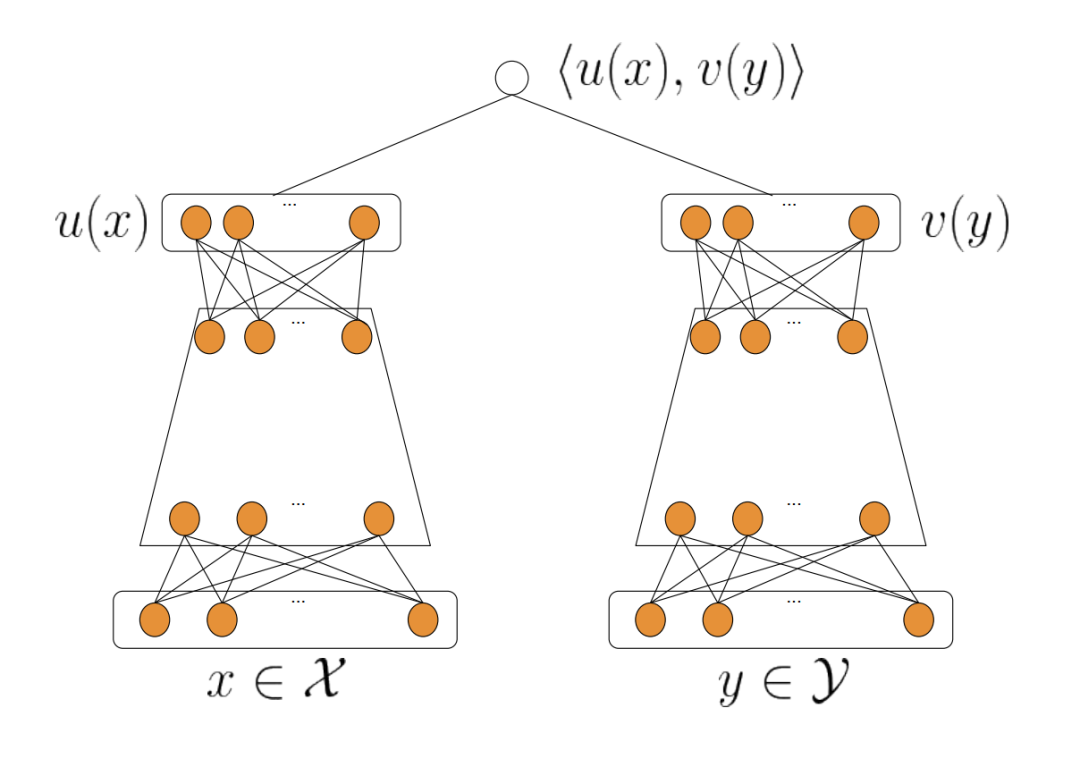
其中:
用于表示用户和上下文特征,用于表示Item特征 和分别表示User侧(用户+上下文)和Item的Embedding特征
在召回层中,由于正负样本(后面会讲如何筛选正、负样本)比例差异巨大,直接使用传统的pointwise方式来训练模型,会导致模型最终将全部样本都往负类中倾斜。为了解决这个问题,通常在召回层中采用pairwise方式来相对度量user与item的loss。
精排层中主要是由于正负样本比例差异相对没那么大,通常能控制在1:10。在精排层中采用pointwise训练模型不会出现预测结果全部倾向负类的情况。
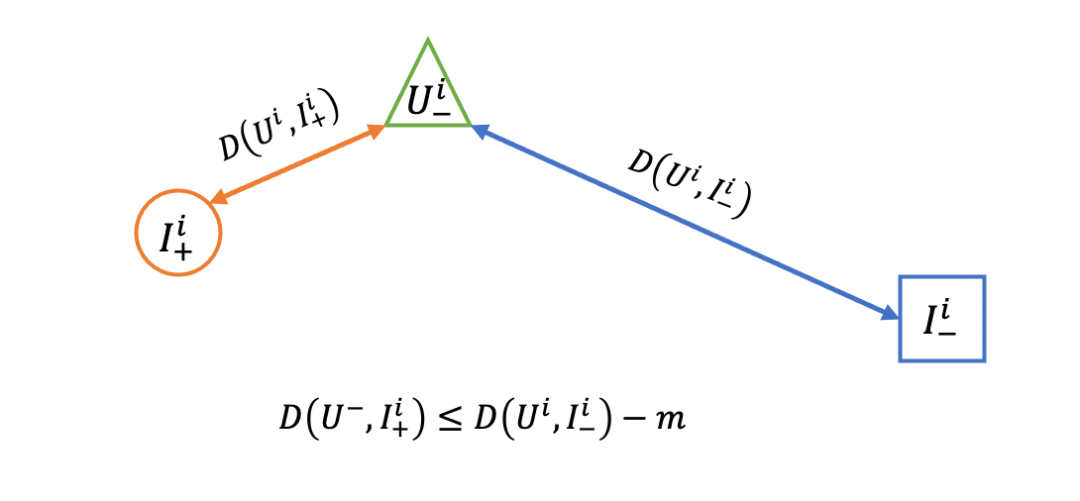
对于三元组输入样本,其中、和分别表示第组样本中的User、正Item和负Item。Pairwise Hinge Loss目标使User与负Item的距离比User与正Item距离大于:
其中:
表示距离度量方法,用于计算和的距离 为超参数,用来控制User和负Item的距离至少比User和正Item的距离差
当然,还可以使用Bayesian Personalized Ranking Loss(BPR loss),目标是使User和正Item的距离与User和负Item的距离差尽可能大,其目标函数:
在实际中,由于BPR loss省去了对结果影响巨大的超参数,通常效果会比Pairwise Hinge Loss要好(并不是绝对的,还要针对具体业务去对比)。
从双塔模型的损失函数来看,我们需要为其构造<user, item+, item->
2、召回的样本Bias
在推荐系统模型训练时,一个核心原则是要保证离线训练数据要和线上分布尽可能一致
。召回层并不是直接影响线上曝光结果的,直接采用曝光和点击数据来构造召回层的训练样本,会造成样本Bias。具体如下图所示:
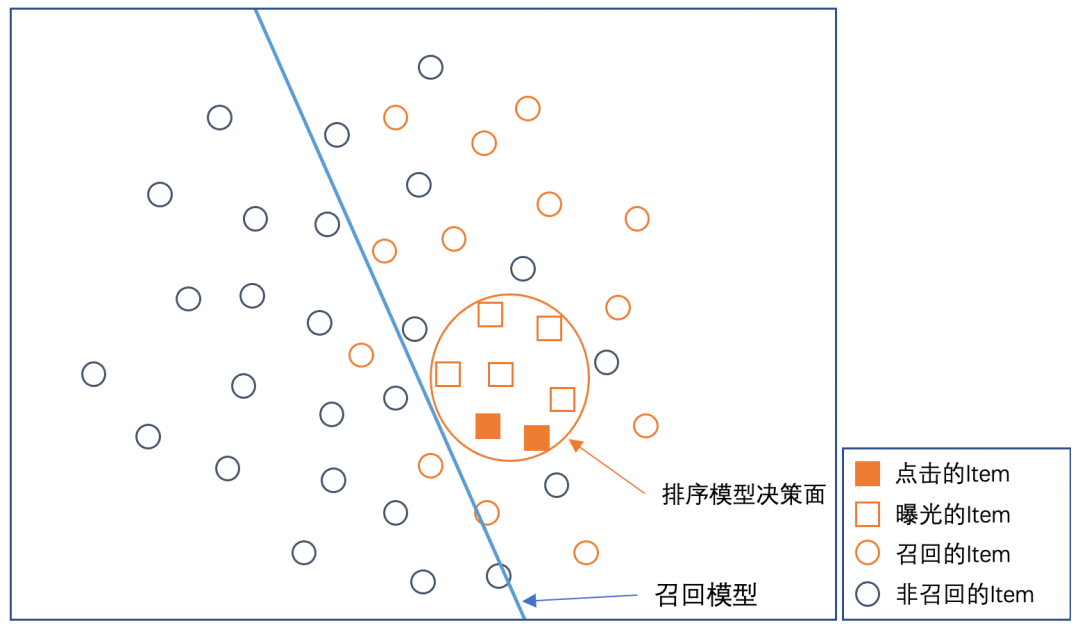
以二维空间样本为例,蓝色直线为召回模型决策面,黄色圆圈为排序模型决策面(p.s. 召回模型复杂度比排序模型低),最终用户看到的是被排序模型选中的样本(简单起见,忽略了后续的重排层的影响)。
如果在召回层中直接使用曝光未点击为负样本、曝光点击为正样本来训练模型,会导致最终模型判别面如下图所示:
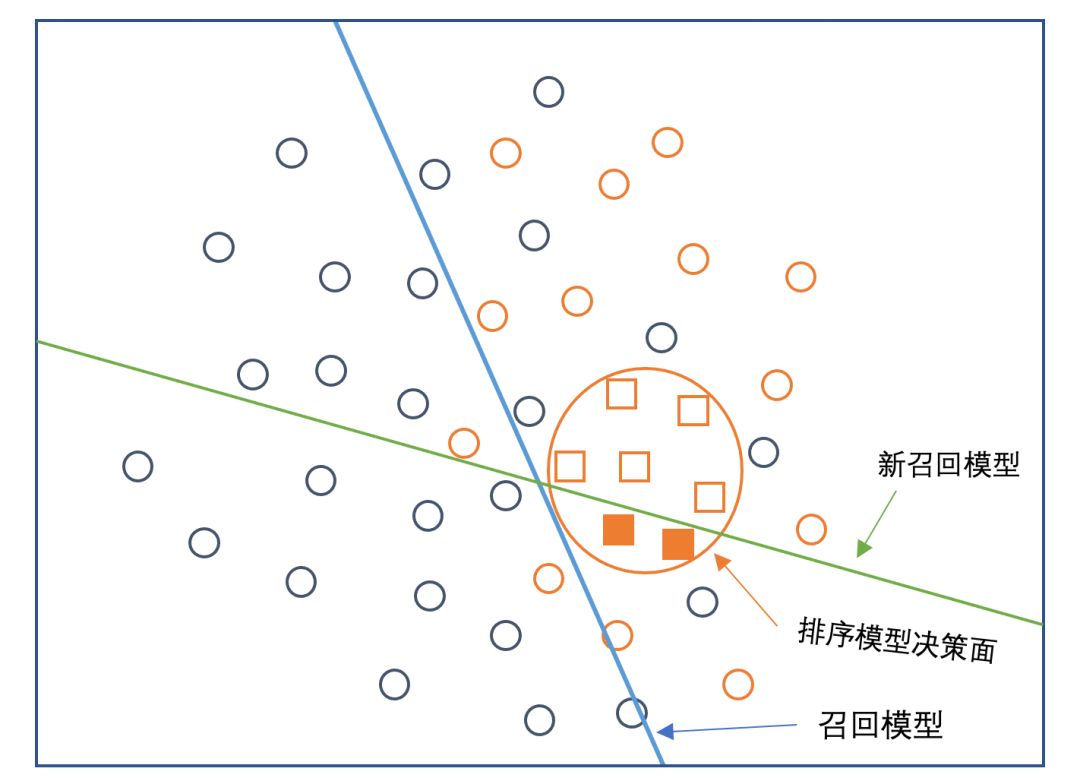
从上图可以看出,新召回模型与真实模型差异较大,这也是其上线后召回效果较差的原因。虽然曝光未点击确实是负样本,但是在曝光之外,由于推荐系统的偏差,很多Item可能永远都不会曝光给部分User,模型只能看到样本空间的一部分,也就造成了训练数据与线上分布不一致的问题
。为了解决这个问题,需要针对召回层来挖掘相应的正负样本。
二、如何挖掘样本
为了避免离线数据与线上分布不一致的问题,在训练召回层模型时,通常会针对性的挖掘训练样本。下面分别从正、负样本角度来介绍主要的样本挖掘方法。
1、正样本挖掘
目前大家对召回层的正样本构造的差异并不大,主要有如下两种:
点击的Item 曝光的Item
从上一节的样本空间示例图中能看到,拿全部曝光和仅拿点击Item作为正样本对于召回层模型来说差异不大,对模型来说正、负样本的空间没有太大变化(见蓝色直线)。EBR的论文从实验上验证了这两种正样本挖掘方法的线上差异并不大。
但实际应用中,了减少计算量(曝光的样本量往往比点击量要大得多)提升模型训练速度,通常采用点击的Item作为正样本。
2、负样本挖掘
在召回层中,问题最大的就是负样本的挖掘。由于推荐系统本身的多层结,加上召回层本身处于推荐的底层,最终曝光给User的Item并不是召回层直接输出的。因此,从用户曝光行为上很难挖掘到适合召回层训练的负样本。
对于负样本挖掘通常有两种做法:
随机采样:从全量的Item池中随机选择部分未曝光的Item作为负样本 hard negative:选择与正样本相似的Item作为负样本
随机采样的方式可以理解为为了扩大样本空间,使模型能够关注到未曝光的样本,从而保证离线数据分布与线上一致。如上一节实例图中召回模型左侧的空间在正常曝光数据中是没办法覆盖到的,通过随机采样的方式就可以实现对该空间的覆盖。
hard negative是将与正样本相似的负样本引入训练中,增加模型召回的准确度。通常hard negative有如下做法:
用户主动负反馈:如不喜欢、取消关注等 上一版召回中排序靠前,但未曝光 上一版召回中与正样本相似的但未曝光
综上,召回层的训练样本主要有点击Item
(正样本)、随机采样+hard negative
(负样本)构成。在负样本中还是以随机采样为主(以空间覆盖为主),hard negative只是补充(占比控制在以内)。
三、热和冷Item怎么办
在样本采样过程中,通常会遇到热门Item(头部)和冷门Item(尾部和新Item)的问题。由于样本采样直接影响到召回模型的效果,需要针对热和冷Item的进行一定处理。通常做法是:1)“打压”热门;2)强化冷门。
1、热门Item打压
推荐系统中往往会存在头部现象(如90%的流量被10%的Item占据,有可能更严重)。在训练召回模型时,会被热门Item占据,在训练embedding向量时,模型倾向于将user embedding尽可能多的与热门item embedding靠近。最终导致线上召回大多都是热门item,最终使模型失去个性化能力(退化成热门排序)。
因此,在样本选择时需要对热门Item进行处理,防止模型被热门item带偏。主要可以从如下两个方面:
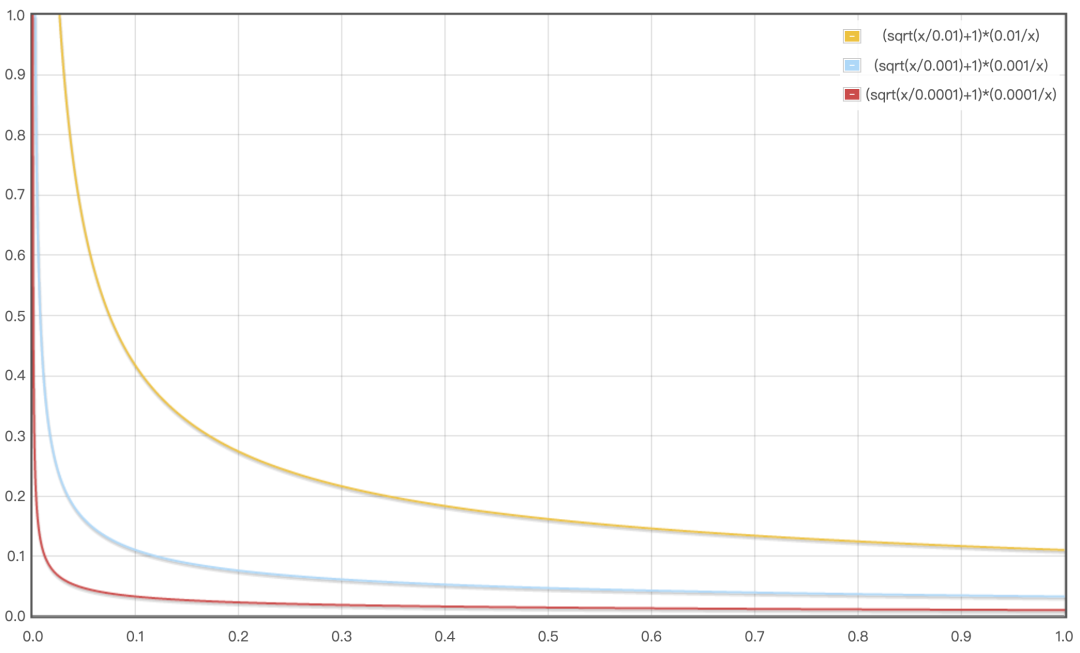
在中,打压高热item:降低热门item成为正样本的可能性,即当热门item做正样本时,通过降采样来防止所有人的召回结果集中在少数热门item上。可以通过如下公式来确定item成为正样本的概率:
其中,表示点击过的用户占比,为超参数,用于控制热门衰减(越小,衰减越快,通常取到之间,如下图所示)
在中,增强高热item:提升热门item成为负样本的可能性,即当热门item做负样本时,通过上采样来抵销其对正样本的绑架,从而实现对热门item的打压。可以通过如下公式来确定item成为负样本的概率:
其中,表示的点击uv,为调节因子,一般在之间。下图以两个item为例,展示不同对负样本概率的影响:
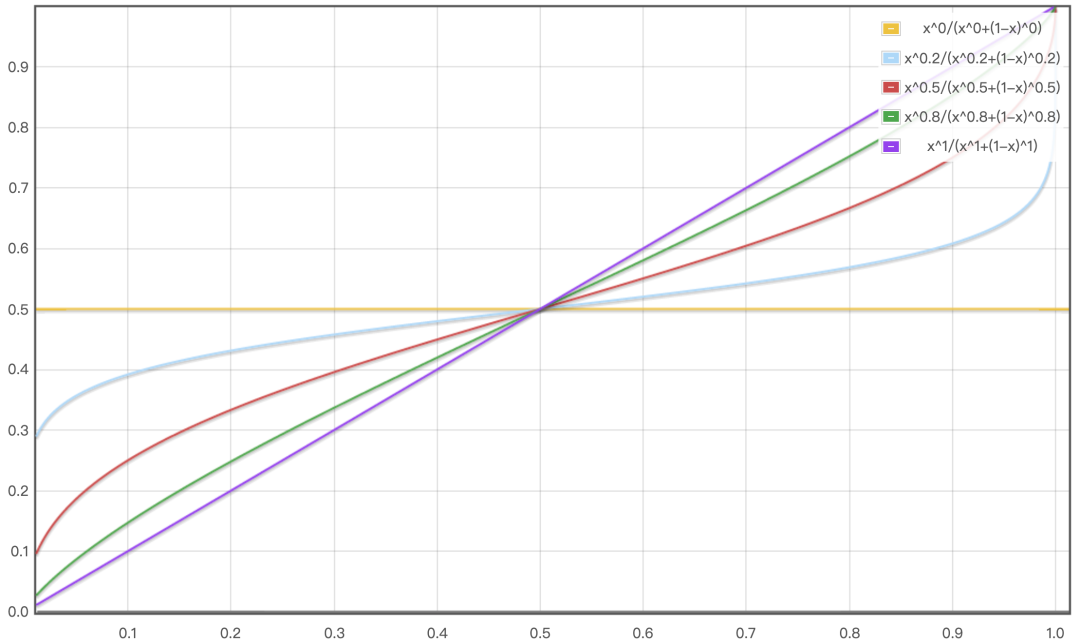
当时,负采样变成均匀,对所有候选item的覆盖度最高,减少了线上和线下覆盖的Item分布差,但是对热门item的打压完全没有打压,召回效果会偏热门,个性化较低
当时,负采样完全按照item的热门程度进行,对热门item的打压最厉害,但是对所有item的覆盖度下降,增大了线上和线下覆盖的item分布差,反而损害召回效果
通常需要根据实际item分布来确定
在正样本采样时,对热门item的打压是减少其出现在正样本中的概率在负样本采样时,对热门item的打压是增加其出现在负样本中的概率
p.s.: 关于热门打压:
2、冷门Item强化
对于冷门item(新item or 长尾item),由于用户量非常少,导致其在模型训练中的样本占比极低,很容易被模型忽视掉。因此,在召回层需要专门对冷Item做一定的强化,确保模型能关注到它们。主要是通过策略强化来实现对冷门item的强化的,如热度预估和多级流量。后续会有文章详细讲冷启动这块的方法,本文只简单提一下:
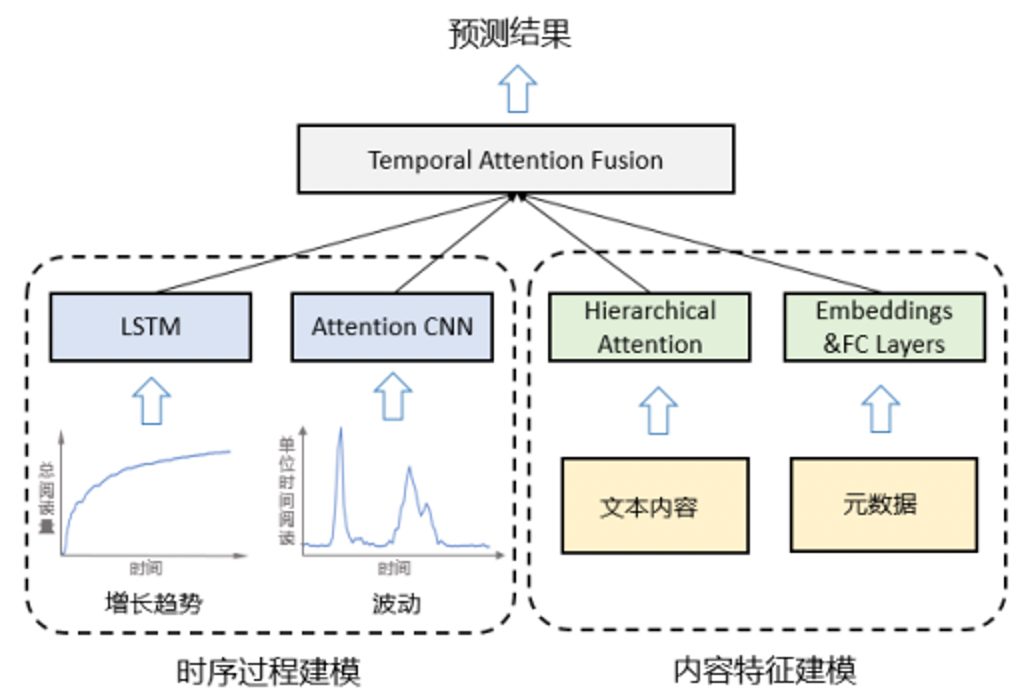
热度预估:通过item的基础数据和线上数据来预估其线上的热度,然后给其相应的试探流量,这里可以参考“微信看一看”的流行度预估论文:Popularity Prediction on Online Articles with Deep Fusion of Temporal Process and Content Features
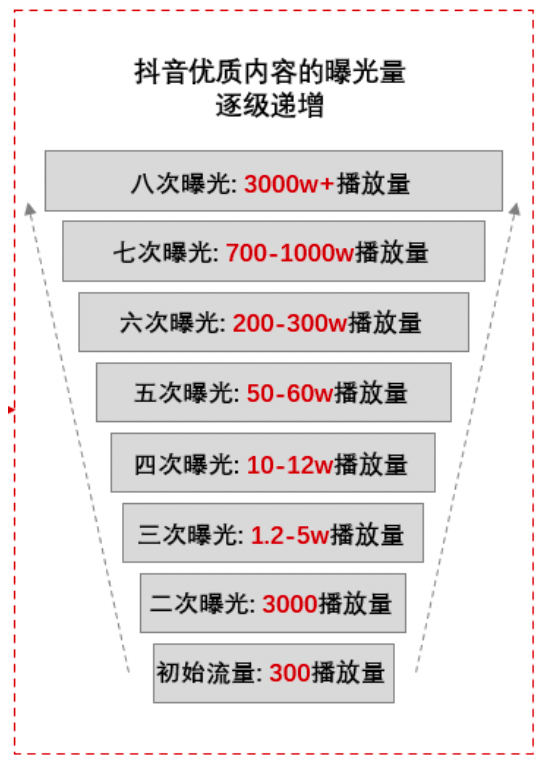
多级流量:由于冷门Item自然流量相对较低,不能准确找到受众用户,通常采用多级流量的方式来逐步扩散用户。如抖音的多级流量扩散
最后
在召回层中,更多的是考虑如何保证线上和线下样本空间一致。特别是对负样本,由于单个用户来说,绝大多数负样本在线上是没有曝光到的(样本bias),直接使用曝光数据构造样本必然会导致召回模型效果较差。本文解释了在召回层为什么需要挖掘样本,以及对召回层线上和线下分布不一致给出了直观解释。
在实际应用中,主要是 正样本+随机负样本+hard negative来训练模型。此外,在采样时通过对热门item的打压缓解热门item对模型的绑架。
对于冷门item,通常是采用策略强化的方式来确保给它们一定的流量来实现对冷门样本的强化,如热度预估和多级流量分配等方法,后续会有文章详细讨论这块。
参考文献
[1] Huang, Jui-Ting, et al. "Embedding-based retrieval in facebook search." Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020.
[2] Mikolov, Tomas, et al. "Efficient estimation of word representations in vector space." arXiv preprint arXiv:1301.3781 (2013).
[3] Liao, Dongliang, et al. "Popularity prediction on online articles with deep fusion of temporal process and content features." Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 33. No. 01. 2019.
[4] Yi, Xinyang, et al. "Sampling-bias-corrected neural modeling for large corpus item recommendations." Proceedings of the 13th ACM Conference on Recommender Systems. 2019
