





在上一篇《「召回层」深度召回中的i2i》中介绍了i2i召回方法。本文将介绍深度召回中的u2i方法。
❝预告:
下一篇将介绍在召回中的样本选择方法以及在实践中的效果。感兴趣的同学别忘了点个关注哦!
❞
一、u2i召回基本框架
常见的u2i召回框架可以简化为下图所示:
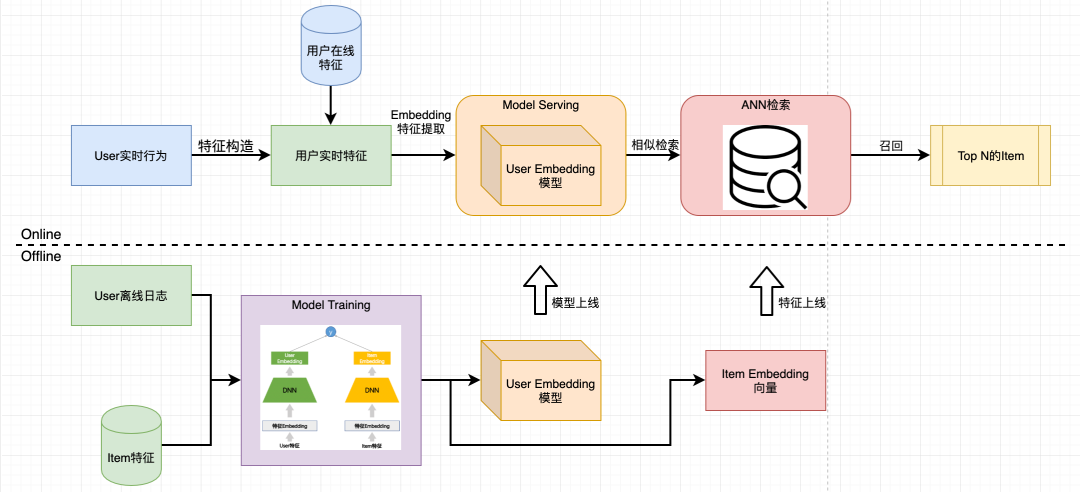
总体可以分为两大块:
离线部分:根据用户行为日志和Item相关特征,离线训练模型,最后将模型拆解成用于提取用户embedding特征的
User Embedding模型
和能够刻画Item特征的Item Embedding向量
。在线部分:根据用户实时行为以及线上特征,构造用户实时特征,再通过
User Embedding模型
提取用户当前Embedding特征。最后经过ANN检索模块
快速检索用户可能感兴趣的TopN Item。
将召回模型拆解成User Embedding模型
和Item Embedding向量
主要是召回效果和工程效率的权衡:
召回效果:用户线上行为是时刻变化的,如果离线提取用户特征,则无法有效刻画用户当前状态,导致召回效果就差。因此,对每个请求的用户采用模型来根据其当前的状态提取用户Embedding特征能有效解决用户实时刻画的问题(每个用户每次请求只过一遍模型)。
工程效率:直接将整个召回模型用于线上会导致线上运行效率低(每个User-Item对都要进行模型预测,效率低,基本不可用)。此外,Item特征通常变化相对较小,离线提取Item的embedding特征,然后再由线上ANN进行检索,能有效解决线上运行效率的问题。
从框架图中可以看出u2i的核心是两个:1)离线模型训练(得到User embedding模型和item embedding向量);2)在线ANN检索。
本文主要介绍离线模型训练部分。关于ANN检索相关的内容可以参考之前的文章《「向量召回」相似检索算法——HNSW》。
比较经典的u2i召回模型主要有两种:1)Youtube召回;2)由DSSM发展而来的双塔召回。
二、Youtube召回
Youtube召回是Google在2016年发表的《Deep Neural Networks for YouTube Recommendations》论文中提出的。一句话总结就是:通过多分类模型来预测用户下一个观看的视频:模型倒数第二层输出为User embedding特征,最后一层的权值为Item embedding特征
。
其拆解方式如下:
User Embedding模型:模型输入仅User特征,通过模型倒数第二层(即最后一层的输入)作为User embedding Item Embedding特征:模型是多分类模型,最后一层的权重()的每一列可以用于表示对应item的embedding特征
Youtube召回模型框架如下图所示:
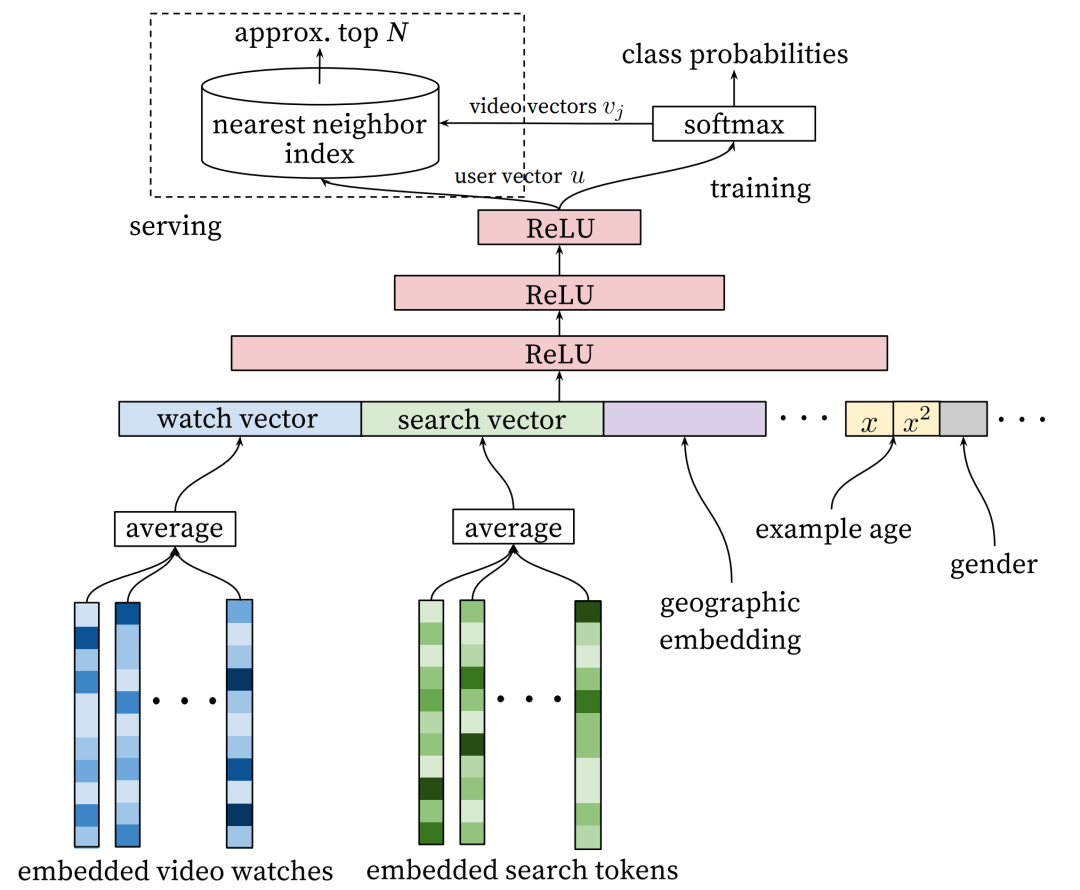
模型主要由三大块构成:
特征:特征上主要包括基础画像(性别、年龄、位置等)和用户近期行为特征(最近看过、搜索过等)。
在近期行为方面,将用户看过的物品构成一个id-list,生成embedding矩阵(每个id对应一个embedding向量)。对于变长id-list,通过聚合操作(如加权,求平均、Attention等)映射成一个定长的向量,然后与其他field特征拼接在一起,最终输入到模型中。
在实际应用时,应当根据相应场景选择合适的特征,上面只是列了论文中的做法。
模型:从网络结构来看,Youtube召回模型采用的是多层DNN网络。但与传统的CTR预测模型不同(单类问题),Youtube召回模型的目标是预测下一个要观看的视频(多类问题),每个视频对应一个类别。由于线上视频数量是百万级的,直接使用softmax来训练非常低效。Youtube采用了word2vec论文中提出的负采样方法来减少每次训练的类别数(每个类别样本随机采样k个其他类别样本),从而加快模型收敛速度。
Embedding提取:将模型倒数第二层的输出作为User Embedding,模型最后一层的权值作为Item Embedding。
为什么这样呢?先看下模型最终的预测公式如下:
其中是第层的权值,是第层的输出,表示模型输出中第个item的概率值。因此,模型最终的预测结果等价于。
于是:(模型倒数第二层的输出)可以视为User embedding向量,(模型最后一层的权值)可以视为Item embedding向量,就表示User embedding和Item embedding的內积(或相似性)。
最后线上应用时,将模型部署至线上的
Model Serving模块
来预测用户实时embedding。通过ANN模块
构建索引,实现快速向量检索。
与传统的推荐方法相比,YouTube召回取消了Item特征的构造,仅根据用户对Item的行为利用DNN自动学习Item的embedding特征。但这也带来了一个问题:对Item的刻画非常依赖于User的行为,对Item(特别是冷门的Item)很容易出现刻画不充分的问题。
三、双塔模型
双塔结构的模型最终是微软在2013年发表的《Learning Deep Structured Semantic Models for Web Search using Clickthrough Data》中提出的DSSM模型,后来被应用于推荐系统中就成了经典的双塔模型。
双塔模型核心思想是:分别独立对User(Query)和Item(Doc)进行多层Embedding,然后通过內积(或cosine相似)来刻画User和Item的相似性。
1、DSSM简介
DSSM(Deep Structured Semantic Model)微软提出,用于在信息检索中解决文本相似匹配问题的算法,其主要结构如下图所示:
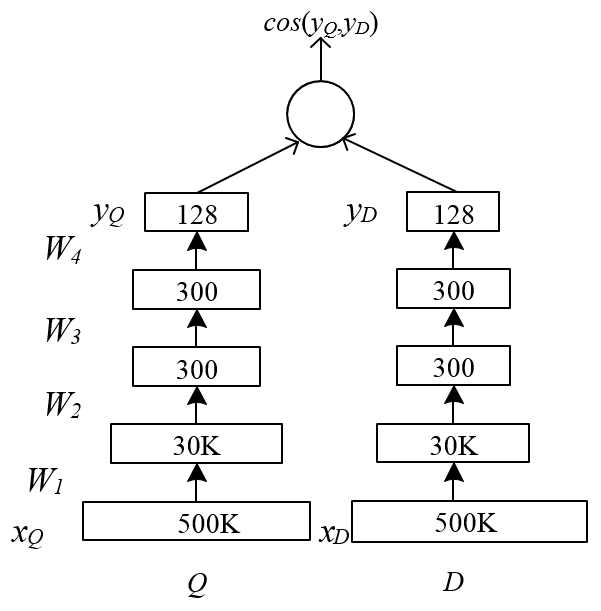
DSSM模型的原理相对简单:通过Q(Query)和D(Document)的曝光、点击日志,采用DNN把Q和D表示为低维向量(如上图中128维的和),并通过余弦相识度来计算向量距离,最终训练出语义相似度模型。
需要注意的是,在DSSM中,网络的激活函数是:
在实际应用中,离线对所有的Document提取,线上对每个请求的实时提取其embedding特征,并从中检索TopN的近似Doc。
2、双塔模型
将DSSM中的和分别替换成推荐系统中的User和Item,就构成了经典的双塔模型(Google在RecSys 2019上发表的《Sampling-bias-corrected neural modeling for large corpus item recommendations》论文中提出),如下图所示:
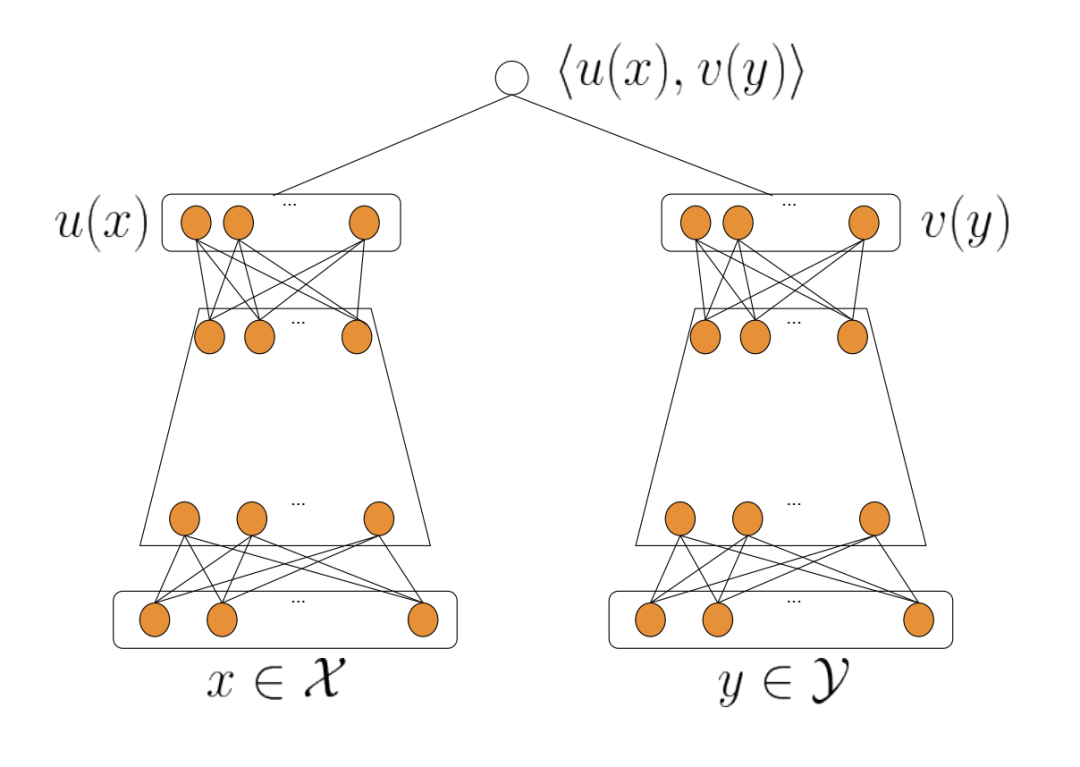
其中:
用于表示用户和上下文特征,用于表示Item特征 和分别表示User侧(用户+上下文)和Item的Embedding特征 $
模型训练完成后,Item的Embedding()是可以离线计算并保存为Item词表,线上部署到ANN模块中。线上应用时,只需实时计算 User Embedding(即用户+上下文特征),然后通过ANN模块来实现快速召回用户偏好的候选集。
双塔模型只是一种模型架构,具体模型结构可以根据实际应用进行设计(如百度的莫比乌斯,FaceBook的EBR等),实际中User和Item特征也有多种建模方式。在模型训练时的负采样,以及最终是输出是采用cosine、sigmoid还是softmax都需要根据具体业务进行调整。
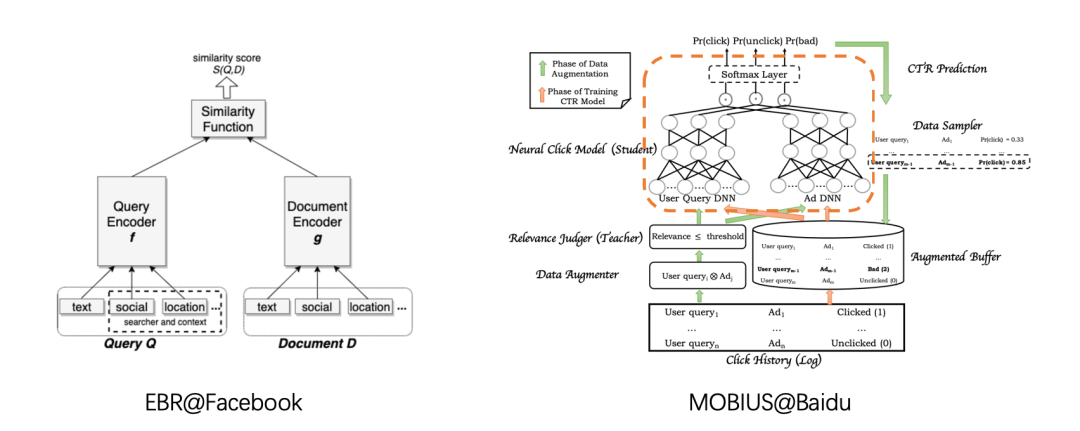
最后
在实际应用中双塔模型的召回性能和灵活度均要优于Youtebu召回模型,主要是双塔模型能独立引入Item特征,能更全面刻画Item特征。此外Youtube召回模型在面对海量Item时,容易偏向热门Item,对小众Item的召回效果相对较差。
线上更新时,User Embedding模型和Item Embedding特征都要保证同时生效,要做到原子更新。
本文只简单介绍了u2i召回常用模型的基本框架,对于样本选择
、模型评估
、模型训练
等细节问题将在下面几篇系列文章中结合笔者在实际业务中的实践来具体讨论。
参考文献
[1] Covington, Paul, Jay Adams, and Emre Sargin. "Deep neural networks for youtube recommendations." Proceedings of the 10th ACM conference on recommender systems. 2016.
[2] Huang, Po-Sen, et al. "Learning deep structured semantic models for web search using clickthrough data." Proceedings of the 22nd ACM international conference on Information & Knowledge Management. 2013.
[3] Yi, Xinyang, et al. "Sampling-bias-corrected neural modeling for large corpus item recommendations." Proceedings of the 13th ACM Conference on Recommender Systems. 2019.
[4] Huang, Jui-Ting, et al. "Embedding-based retrieval in facebook search." Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020.
[5] Fan, Miao, et al. "MOBIUS: towards the next generation of query-ad matching in baidu's sponsored search." Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2019.
