





在上一篇《「召回层」回顾一下传统召回方法》中总结传统召回方法。本文将介绍深度召回方法中的i2i召回
。
❝预告:下一篇将介绍
❞深度召回方法中的u2i召回
。感兴趣的同学别忘了点关注哦!
什么是i2i和u2i
提到召回方法,大家听到比较多的是各种*2i
,如i2i、u2i、u2i2i、u2u2i等。那它们分别指的是什么呢?
首先要清楚的是这里的i和u分别指的是item和user。i2i和u2i可以将它们简单理解为:
i2i:通过计算item间的相似度,找到相似的item。如文本相似 u2i:通过计算user和item间的相似度,找到与user相似的item。如矩阵分解
i2i和u2i的目的都是找到相似的item,可以理解为一种距离度量方法。基于i2i和u2i就衍生出来了下面两种推荐策略:
u2i2i:通过user找相似item,再基于i2i召回相似的item。如ItemCF u2u2i:通过user找相似user,再基于u2i召回相似。如UserCF 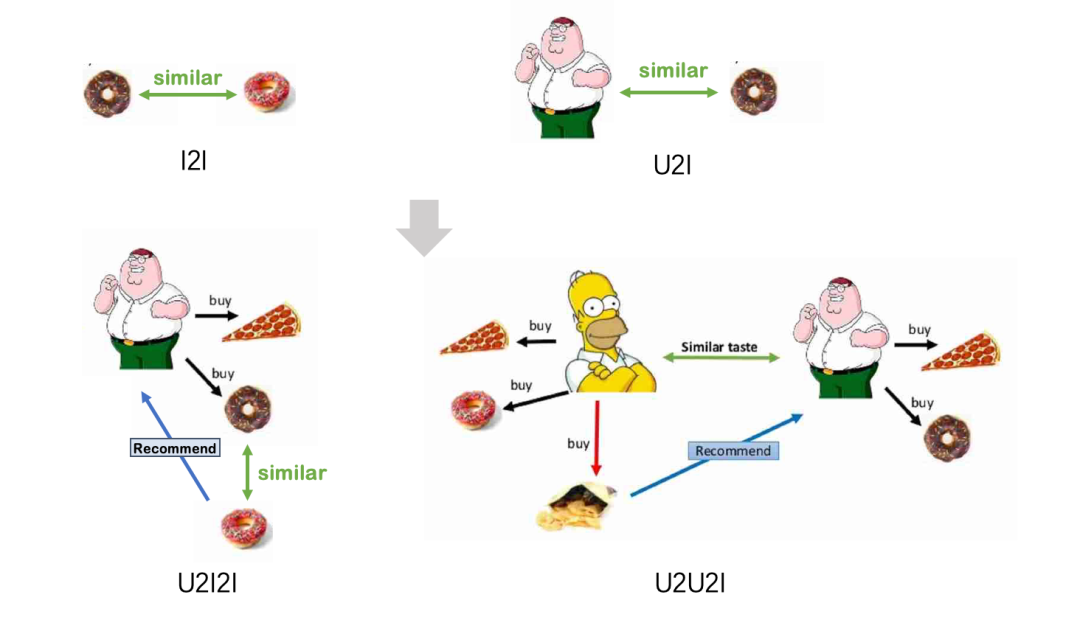
从上面的图可以看出:i2i和u2i是召回的基础,通过item/user找相似的item。而u2i2i和u2u2i是推荐逻辑,即将item通过item/user推荐给目标用户。更通俗:i2i和u2i是找item,u2i2i和u2u2i是将找到的item推给user
。
本文主要关注在i2i上,后续会有文章介绍u2i,感兴趣的读者可以持续关注下!
i2i召回基本框架
传统的i2i召回框架如下图所示: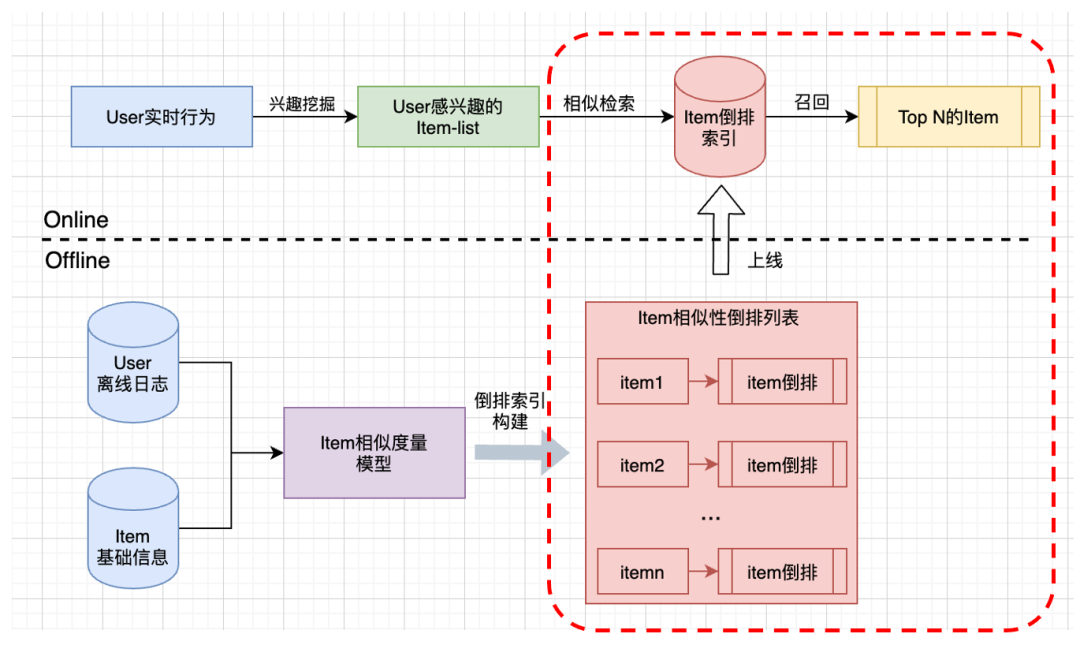
传统的i2i召回核心:
离线计算item间相似度,构建item的相似倒排索引; 线上根据用户实时行为,挖掘用户感兴趣的item-list(可以是用户看过、评论、关注的item,这里其实是u2i),然后再基于item-list从倒排索引中检索出Top N的item(这里才是i2i,上图中的红色框中)。
i2i遇上深度学习——Embedding召回
从i2i召回框架中可以看出,i2i召回的核心是如何度量item间的相似性。传统的方法可以通过User-Item的打分矩阵来计算(如ItemCF)。
但传统的方法并没有加入user、item和上下文相关等信息,也没有考虑user/item间的相关性,召回效果并不是很好。随着深度学习技术的发展,召回技术开始跟深度学习结合,出现了各种基于深度学习的召回方法。在i2i召回中,Embedding技术以其较好的表示能力和泛化能力被广泛应用。
一、什么是Embedding
提到Embedding,大家首先想到的向量化
,主要作用是将高维稀疏向量转化为稠密向量,从而方便下游模型处理。那什么是embedding呢?参照Tensorflow社区的定义:Embedding是离散实例连续化的映射
❝An embedding is a mapping from discrete objects, such as words, to vectors of real numbers.
❞
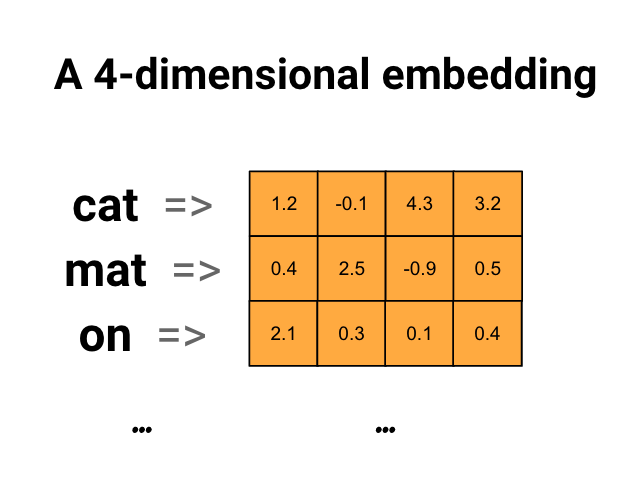
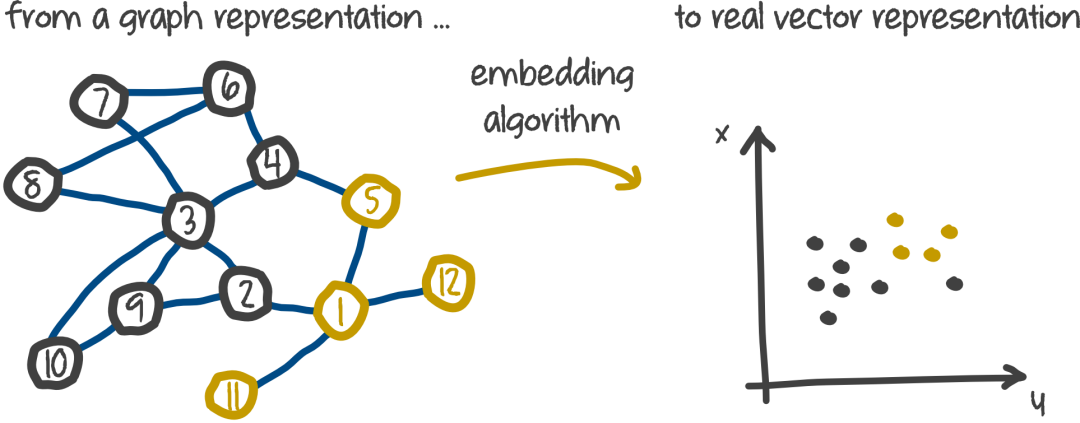
如下图所示,可以将离散型词Embedding成一个四维的连续稠密向量;也可以将图中的离散节点Embedding成指定维度的连续稠密向量。原始object之间的关系,可以通过Embedding向量的距离(如cosine、內积、欧氏距离等)来刻画。
Embedding在推荐系统中的应用可以简单总结如下:
作为Embedding层嵌入到深度模型中,实现将高维稀疏特征到低维稠密特征的转换(如Wide&Deep、DeepFM等模型); 作为预训练的Embedding特征向量,与其他特征向量拼接后,一同作为深度学习模型输入进行训练(如FNN); 在召回层中,通过计算user和item的Embedding向量相似度,作为召回策略(比Youtube推荐模型等); 实时计算user和item的Embedding向量,并将其作为实时特征输入到深度学习模型中(比Airbnb的embedding应用)。
后续内容主要针对Embedding在召回层中的i2i召回策略的应用进行讨论,「后续会有相应的文章来介绍其他的应用」。
二、Embedding+i2i框架
在引入Embedding技术之后,i2i召回框架如下所示:
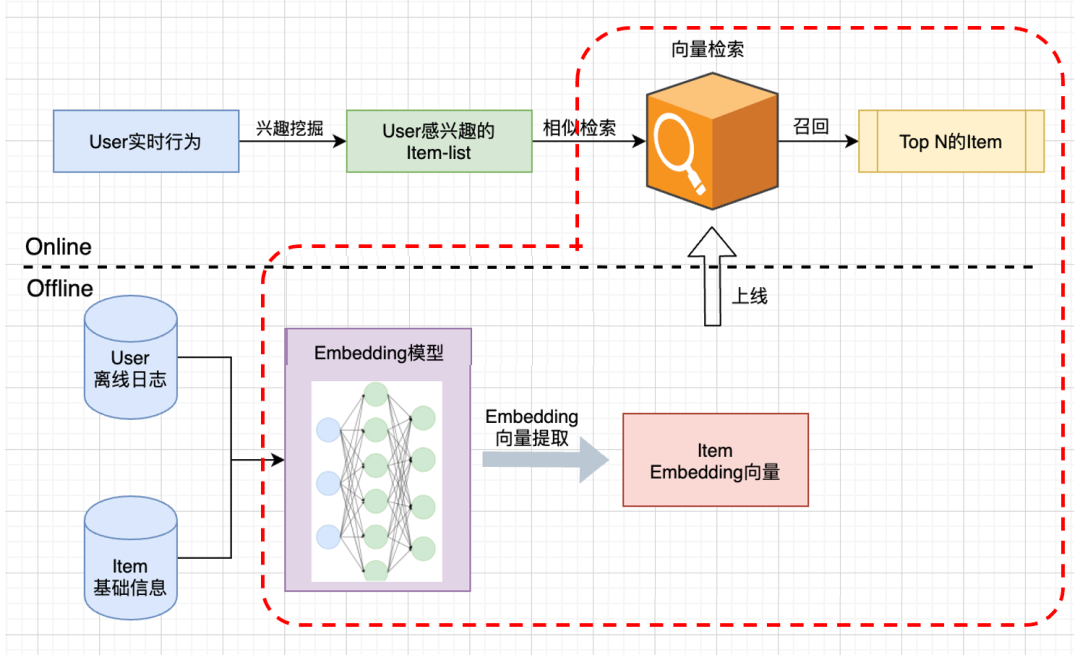 如红色框所示,主要分两个步骤:
如红色框所示,主要分两个步骤:
在离线的时候,根据user和item相关信息,通过Embedding模型(通常是深度模型)得到item的embedding向量 线上根据用户实时感兴趣的item-list,从向量检索模块中找到Top N的item
关于线上部分是如何对向量快速检索的可以参考之前的文章《「向量召回」相似检索算法——HNSW》,这里就不赘述了。
在离线部分,我们核心要做的是如何得到Item的embedding向量,即如何对item进行embedding。
三、如何Embedding
对Item的embedding大致可以分为两大类:基于内容的和基于行为的。笔者在之前的文章《用万字长文聊一聊 Embedding 技术》中已经详细介绍了各种embedding方法,感兴趣的读者可以跳过去了解下。下面简单介绍常用的几种embedding方法。
1、基于内容
在推荐系统中,文本类型数据是最常见的内容形式。因此,本节基于内容的embedding方法主要是针对文本类型数据,即文本的Embedding算法。文本的Embedding方法主要分静态向量化和动态向量化两种。
A)静态向量化
静态向量指的是一旦训练完成后,对应的向量便不再发生改变,如一个词经过向量化之后,在后续的场景中该词对应的向量不会发生改变。主要模型有Word2Vec、GloVe和FastText。
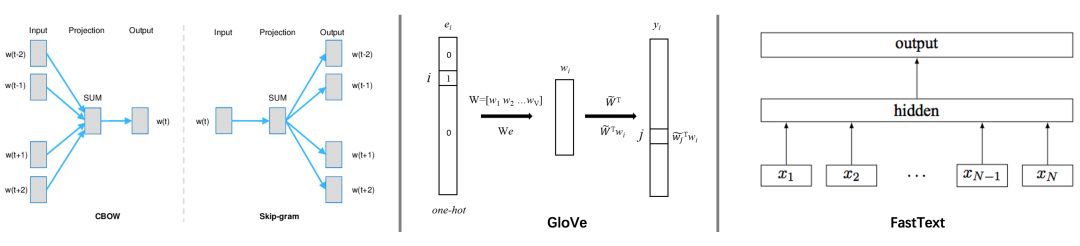
在得到词向量之后,对Item的向量刻画可以按照文本长短分为两种:
短文本(如标题):将文本分词,去除停用词和高频词之后,将剩余词的embedding向量取均值来得到对应item的向量表示 长文本(如正文):对文本提取关键词,采用关键词的词向量均值来得到item的向量表示
静态向量表示算法简单,但每个词被表示成一个固定的向量,无法有效解决一词多义的问题。
B)动态向量化
动态向量化不在对单个次进行明确向量表示,而是利用模型根据上下文来推断每个词对应的意思,从而得到该文本的embedding向量。在对词进行向量表示时,能结合当前语境对多义词进行理解,实现不同上下文,其向量会有所改变。主要模型有:ELMo、GPT和BERT。
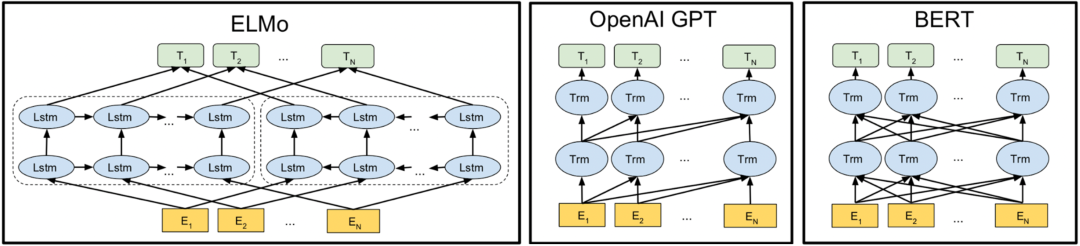
对Item的刻画同样可以根据文本长短来处理:
短文本:直接采用模型进行预测,得到item的embedding向量 长文本:采用文章的 开头+结尾
来构造合适长度的文本,然后再用模型进行预测,得到item的embedding向量
2、基于行为
基于行为的方法主要可以分为两大类:1)基于行为序列的Embedding;2)基于Graph的embedding。
这里只是简单给出对应算法的核心思想,具体细节建议去看笔者在之前的文章《用万字长文聊一聊 Embedding 技术》
A)基于行为序列的Embedding
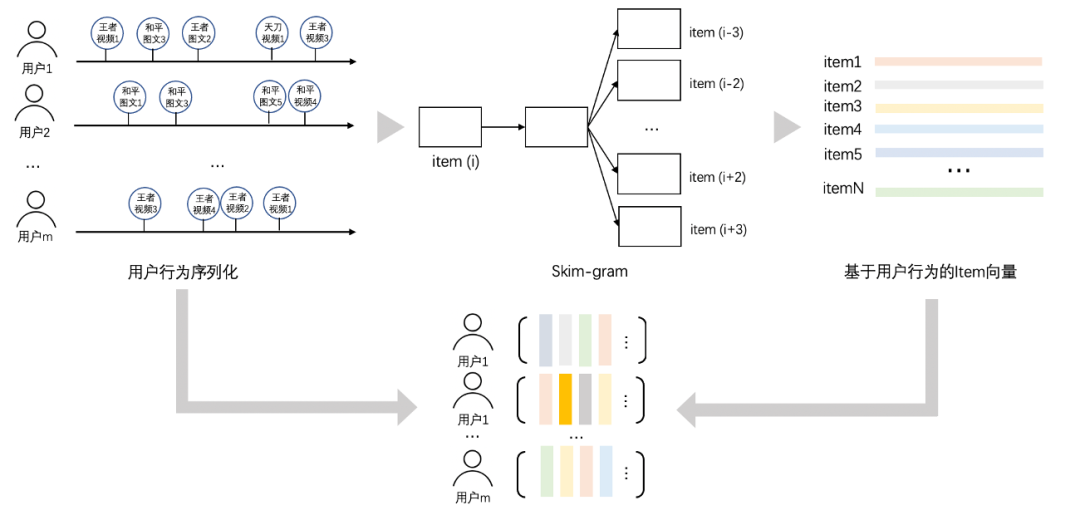
核心思想是将用户的行为序列当做句子
,序列中的item相当于词
,然后采用文本的embedding方法得到每个词
的embedding向量。与文本embedding不同的是,这里得到的就是item的embedding向量,无需做向量的聚合。
B)基于Graph的Embedding
核心思想是根据用户行为,构造user、item的关系图,然后采用Graph embedding方法实现对图中节点(即user、item)的embedding向量。
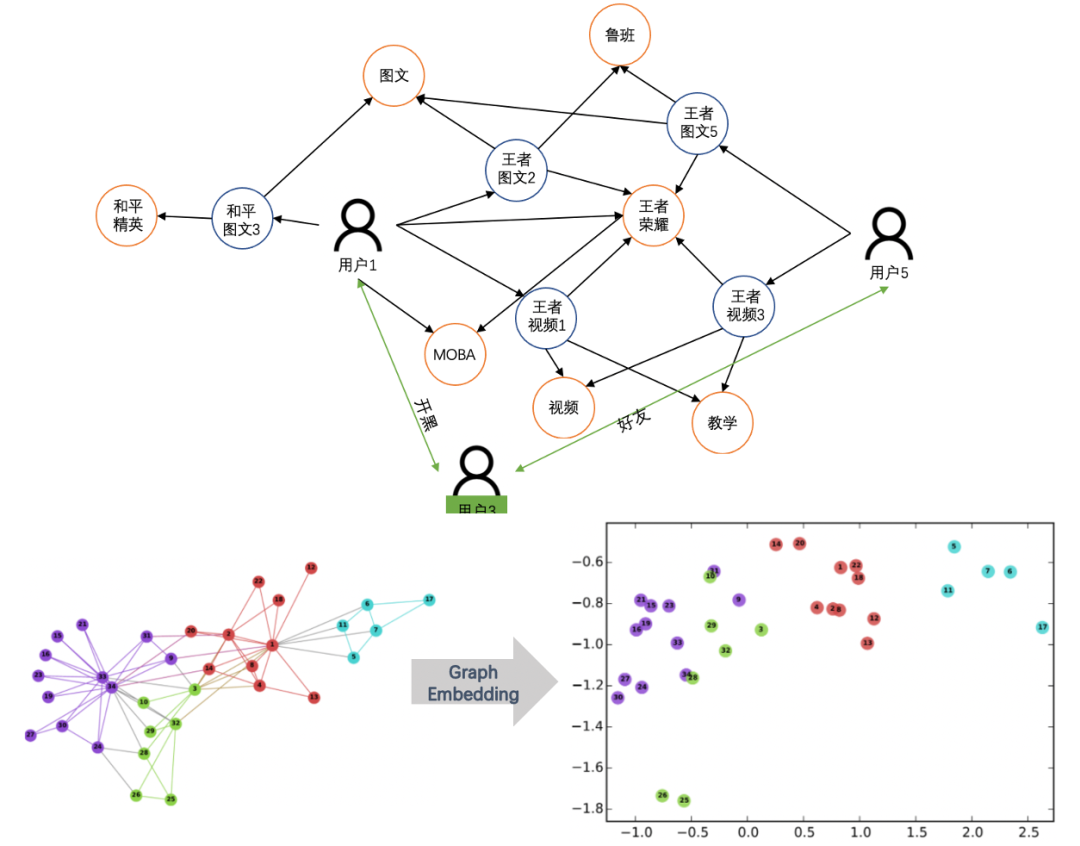
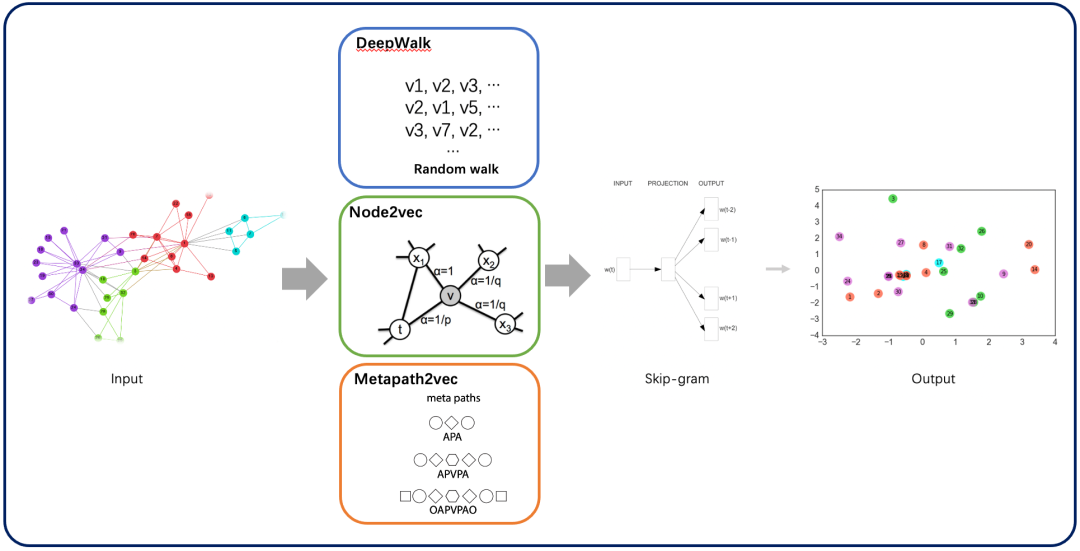
在实际应用应用中,Graph Embedding模型可以分为两大类:
浅层图模型:采用
random-walk + skip-gram
模式的embedding方法。主要是通过在图中采用随机游走策略来生成多条节点列表,然后将每个列表相当于含有多个单词(图中的节点)的句子,再用skip-gram模型来训练每个节点的向量。这些方法主要包括DeepWalk、Node2vec、Metapath2vec等。
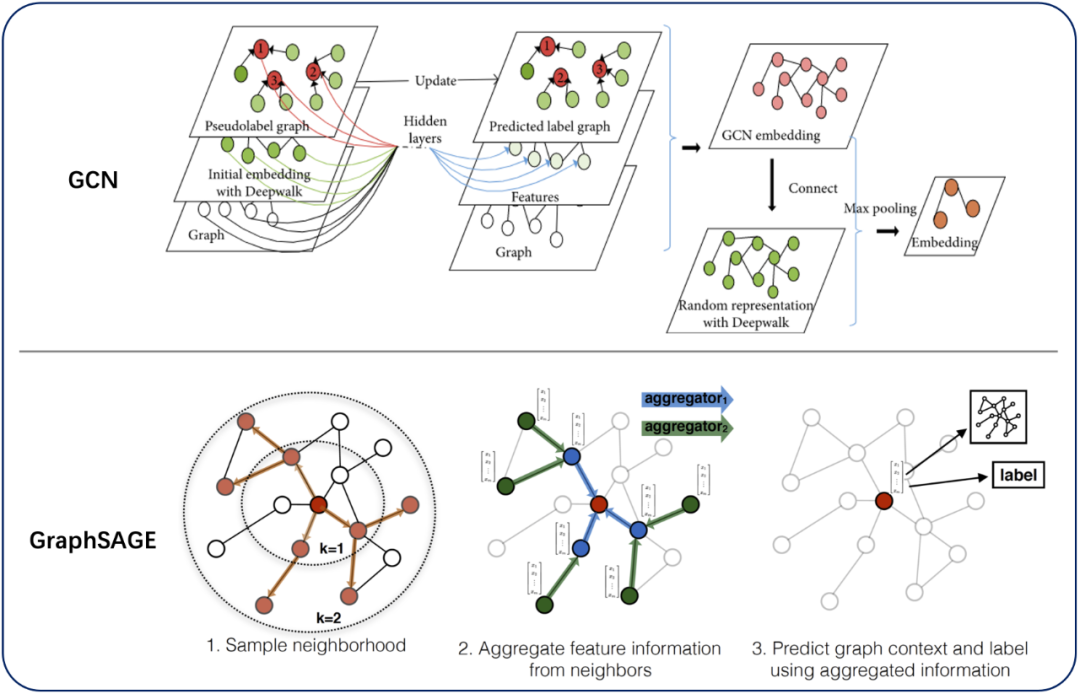
深层图模型:从而在图中提取拓扑图的空间特征,实现end-to-end训练模型。主要方法有基于Spatial Domain的GCN和基于spectral domain的GraphSAGE。
最后:一些小Tricks
前面章节介绍了用于i2i召回中的item embedding构造方法,在应用中主要是通过user行为和item基础信息离线构造item的embedding向量。线上通过向量检索(如FAISS和hnswlib等工具)实现快速检索。下面简单分享下笔者在实际应用中的一些小tricks:
训练词向量时要与处理的业务相关,公开数据集的词向量用起来虽然方便,并不能有效表示业务特点,如王者荣耀中的鲁班和后裔的信息用通用词向量无法刻画 动态词向量模型在业务相关预料中进行finetune之后,效果更佳 对于长文本(超过512字的)可以按照段落来取段首句子,然后在拼接成较短的文本 行为序列中用户行为的选择要尽量与目标相关,如目标是观看时长,可以以用户观看超过N秒为阈值进行筛选 当用户行为记录不够时,可以按照用户属性(如性别&年龄&地域等)构造聚合的id 在上线embedding向量时,要保证原子更新:向量检索模块和id2vec模块的向量要保证一致 item向量更新可以不用特别频繁,在item库变化不大的情况下,周更新即可 对用户的 item_list
进行召回时,对每个item召回Top
参考文献
[1] Mikolov, Tomas, et al. "Distributed representations of words and phrases and their compositionality." Advances in neural information processing systems. 2013.
[2] Pennington, Jeffrey, et al. "Glove: Global vectors for word representation." Conference on empirical methods in natural language processin. 2014.
[3] Bojanowski, Piotr, et al. "Enriching word vectors with subword information." Transactions of the Association for Computational Linguistics 5 (2017): 135-146.
[4] Peters, Matthew E., et al. "Deep contextualized word representations." arXiv preprint arXiv:1802.05365 (2018). [5] Radford, Alec, et al. "Improving language understanding by generative pre-training." (2018): 12.
[6] Devlin, Jacob, et al. "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018).
[7] Perozzi, Bryan, et al. "Deepwalk: Online learning of social representations." ACM SIGKDD international conference on Knowledge discovery and data mining. 2014.
[8] Grover, Aditya, et al. "node2vec: Scalable feature learning for networks." Proceedings of the 22nd ACM SIGKDD international conference on Knowledge discovery and data mining. 2016.
[9] Dong, Yuxiao, et al. "metapath2vec: Scalable representation learning for heterogeneous networks." Proceedings of the 23rd ACM SIGKDD international conference on knowledge discovery and data mining. 2017.
[10] Wilson L Taylor. 1953. cloze procedure: A new tool for measuring readability. Journalism Bulletin, 30(4):415–433.
[11] Hammond, David K., Pierre Vandergheynst, and Rémi Gribonval. "Wavelets on graphs via spectral graph theory." Applied and Computational Harmonic Analysis 30.2 (2011): 129-150.
[12] Kipf, Thomas N., and Max Welling. "Semi-supervised classification with graph convolutional networks." arXiv preprint arXiv:1609.02907 (2016).
[13] Hamilton, Will, et al. "Inductive representation learning on large graphs." Advances in neural information processing systems. 2017.
