





深度召回方法。感兴趣的同学别忘了点关注哦!
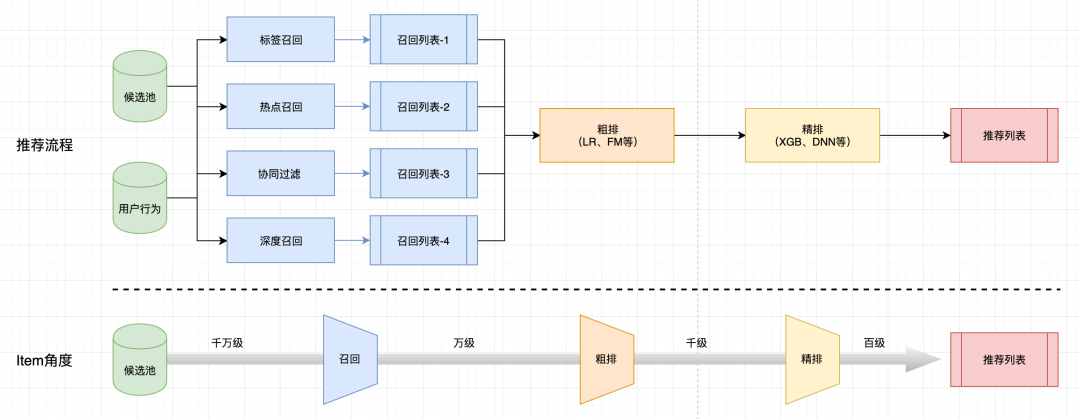
在推荐系统,经常听到大家将推荐系统分成召回、粗排、精排
,那什么是召回呢?
在推荐系统中,如果算力和存储效率足够(不管遇到多大数据都能在可用时间内计算完成),那推荐系统也就不需要召回、粗排和精排了。排序的多级策略(本质上召回、粗排和精排都属于排序)是为了权衡效率和性能。排序阶段越往后,模型越复杂,排序准确度越高,但所能处理的数据量越少。
❝召回是从海量候选池中快速筛选出部分用户感兴趣的物品,供后面排序阶段使用啊
❞
召回面对的是千万级的候选池,需要高效的将用户感兴趣的物品筛选出来。总结设计召回的原因:
❝1、快速筛选候选集,减小后续排序阶段开销
2、针对业务上的特殊要求(如热点事件),在召回层设计专门的召回策略
❞
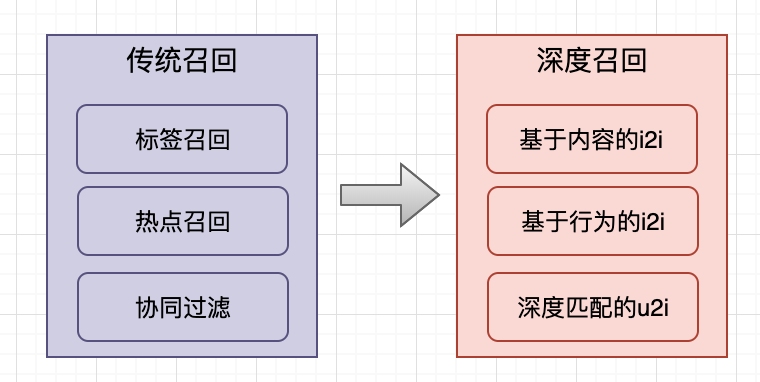
在工业界,召回层技术经历了从以标签、协同过滤为主的传统召回到以Embedding为主的深度召回的发展过程。本文主要针对介绍传统召回方法,下一篇文章会介绍深度召回方法,感兴趣的可以关注下。
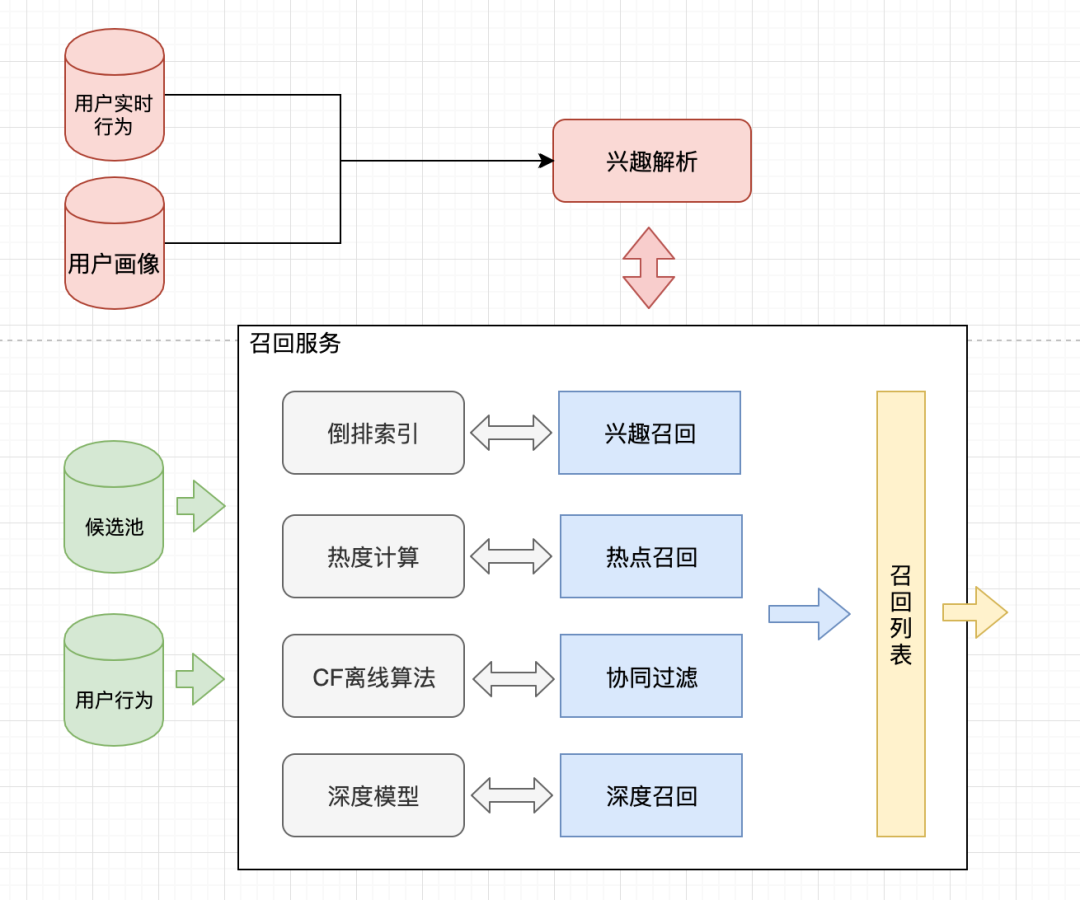
一、召回框架
召回框架如下图所示,总体可分为如下阶段:
根据用户实时行为和画像数据,解析出用户当前兴趣;
召回服务根据不同召回策略(如兴趣召回、热点召回、协同过滤、深度召回等等)从千万级的候选池中快速筛选出数千条用户可能感兴趣的候选物品;
召回服务将召回列表返回给后续的排序服务。
二、召回方法
传统召回方法主要分为四种:标签召回、热点召回、协同过滤、矩阵分解
1、标签召回
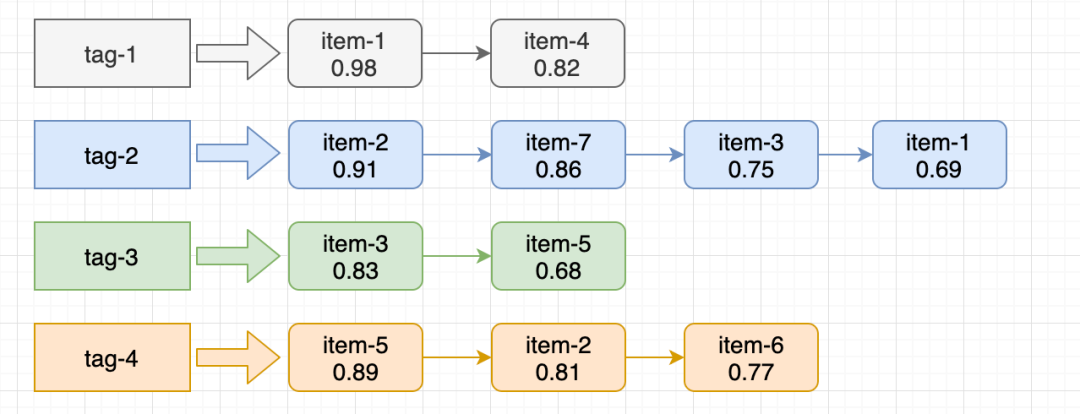
标签召回通常是将Item按照标签构造倒排索引,然后线上根据标签返回对应倒排的TopN的Item。这里核心有两点:1)标签选择;2)倒排
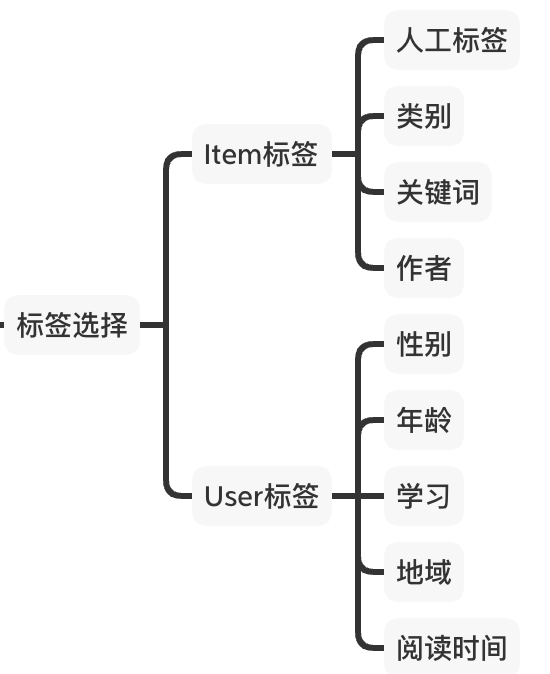
A) 标签选择
在标签选择中,主要是考虑选择能对Item进行刻画的标签,如Item的tag、category。也可以使用用户的属性类作为标签,如用户类型、性别、年龄等。
B) 倒排
在对标签选择完之后,我们就可以将Item归属到对应标签下,通过构造倒排索引来将Item排序并串起来。那么问题就来了,如何对Item进行排序呢?
通常是考虑Iem的消费热度:在固定时间段内(如最近7天),统计Item的消费指标(如消费PV,当然也可以综合考虑多个指标加权)。最终,根据Item的热度值来构建对应倒排索引。
这种基于消费热度的方式会有一个问题:倾向于将老内容排在前面,导致新内容很难被召回
因此,需要对热度计算做一个修正,可以采用牛顿冷却
来对热度进行衰减:
公式如下:
其中:
是温度(T)的时间(t)函数 代表室温, 就是当前温度与室温之间的温差。由于当前温度高于室温,所以这是一个正值。 常数 表示室温与降温速率之间的比例关系
假设时刻物体表面温度为,则对这一微分方程进行求解可得:
最终可得:
令室温H为0度,最终方程可简化为:
最终应用于现实为:
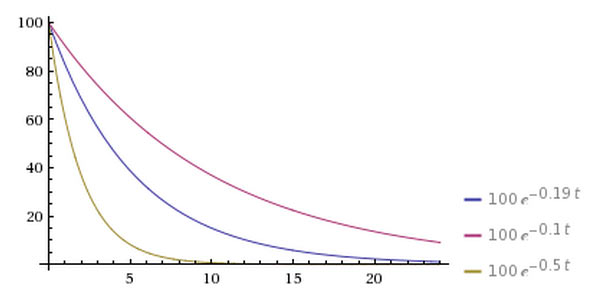
其中,控制热度的衰减速度:
表示在时间内,热度衰减到原来的 表示在时间内,热度衰减到原来的
2、热点召回
热点召回通过对用户进行不同的分组(如基础画像、画像交叉等),统计不同类型用户在看什么内容,从而得到不同的热点列表:
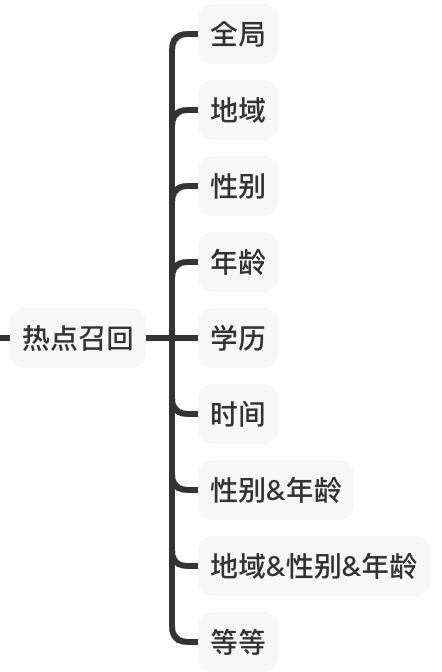
热点召回可以给冷启动用户(用户行为少,兴趣不明确)召回当前大家在看的热门内容(避免了由于用户兴趣缺失,导致召回内容不准的问题)。
同样在构建热门倒排时可以采用牛顿冷却算法来对热度进行衰减。
3、协同过滤
协同过滤算法本质是通过User对Item的行为构造共现矩阵(也称评分矩阵),然通过共现矩阵来刻画User或Item,最后根据User或Item间的相似性进行推荐。协同过滤主要分为如下两种:
UserCF
:基于用户间相似性来推荐(即将相似用户看的内容推给他)ItemCF
:基于物品间相似性来推荐(即将用户看过的相似内容推给他)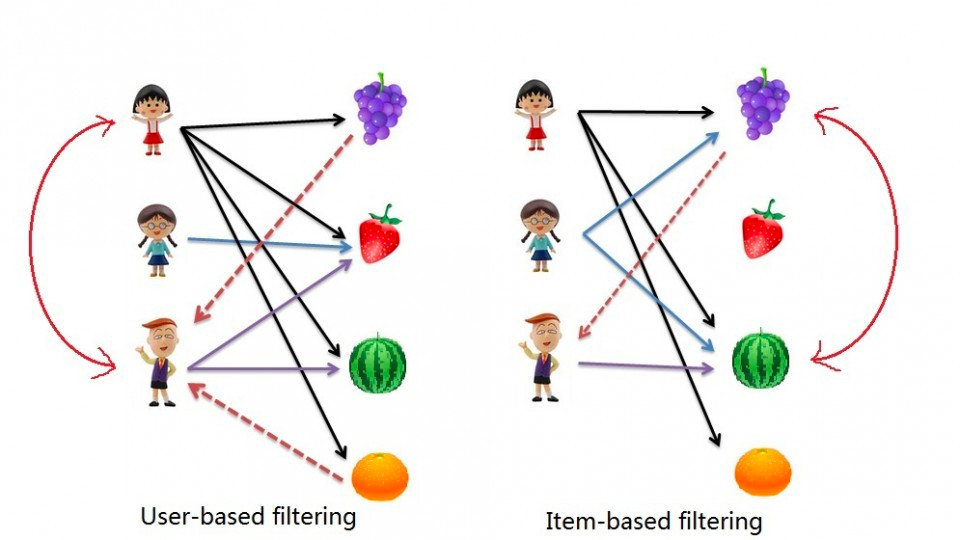
A)UserCF
直观上理解:UserCF是找一群相似用户,把相似用户喜欢的物品推荐给目标用户。因此算法核心可以分为两步:
A) 找到与目标用户相似的用户集合 B) 找到这个集合中的用户喜欢的Item,并推给目标用户
在A步中,核心是度量用户间的相似性。这里主要是利用用户行为的相似性来刻画用户间的相似度。由于共现矩阵中的行向量代表用户向量,因此计算用户相似度,就是计算共现矩阵中两个向量的相似度。主要可以考虑如下四种计算方法(更多相似度计算方法可以参考之前的文章《19种常用的距离度量方法》):
Jaccard距离
欧氏距离
余弦相似度
Pearson相关系数
其中和分别表示和的均值
需要注意的是,通过共现矩阵计算两个用户相似是由于他们都消费了相同的物品。
在B步中,UserCF会给用户推荐和他相似的Top k
个用户喜欢的Item。常用方法是以用户相似度为加权系数,对用户评分做加权平均:
其中表示与用户相似的Top k
的用户集合,表示用户对物品的投票(如消费为1,未消费为0)。
虽然CF算法原理很简单,但在实际应用中却很难,主要有如下两个问题:
计算和存储开销大
:需要存储全部用户和物品的共现矩阵,对于用户规模大的场景不太友好对历史行为稀疏的用户效果不佳
:用户历史行为稀疏导致无法有效刻画用户兴趣,仅从行为角度很难召回用户感兴趣的内容
B)ItemCF
相较于UserCF,ItemCF对计算和存储压力就小很多(Item量级远小于User量级),因此它也得到了广大互联网公司的青睐。
直观上理解:ItemCF是找到用户历史消费过的物品,把与这些物品相似的物品推荐给用户。因此算法核心同样可以分为两步:
A) 计算物品间的相似度 B) 找到用户历史消费过的相似物品推荐给用户
在A步中,在计算物品相似度时,同样可以采用与UserCF中相同的相似度计算方法,这里就不重复了。
在B步中,采用当前物品和用户历史物品评分的加权和来表示用户对物品的偏好:
其中,表示用户对物品的预估偏好,表示物品和物品的相似度,表示用户对物品的评分。
需要说明的是:两个物品具有相似性是因为他们共同被用户喜欢(喜欢A的用户也喜欢B)
UserCF和ItemCF的应用场景是不同的
UserCF适合用户兴趣较为分散的场景(如资讯、新闻推荐),能通过相似人群给用户推荐他们感兴趣的内容
ItemCF适合用户兴趣相对稳定的场景(如电商、视频推荐),能推荐和用户历史感兴趣的相似的物品
4、矩阵分解
A)SVD(Singular value decomposition)
矩阵分解的常用方法是SVD(奇异值分解)算法。任何矩阵,都可以通过SVD的方法分解成几个矩阵相乘的形式。
其中和是正交矩阵,是特征值矩阵。
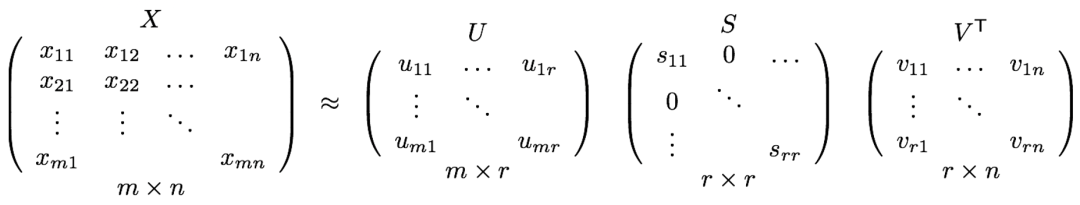
在推荐系统中,可以表示为共现矩阵,其中和分别表示平台的用户数和物品数。表示用户对物品的评分(也可以是点击、互动、播放、下载等行为),用于刻画用户对物品的有效操作。采用SVD算法将分解成、和。
虽然,从形式上看SVD分解简单直接,但由于日常共现矩阵是高度稀疏的,而SVD分解要求矩阵是稠密的,通常采用对共现矩阵中的缺失值进行补全(比如补0、全局平均值、用户物品平均值补全等)得到稠密矩阵。再用SVD分解并降维。但实际过程中,元素缺失值是非常多的,导致了传统SVD不论通过以上哪种方法进行补全都是很难在实际应用中起效果。
此外传统SVD在实际应用中还有一个严重的问题——计算复杂度(时间复杂度是,空间复杂度是)。当用户数和物品总量过大(如千上万级),对矩阵做SVD分解是非常耗时。这使得传统的SVD分解方法很难在实际业务中应用起来。
B)隐语义模型(Latent Factor Model)
LFM主要代表是2006年由Simon Funk在博客上公开的算法FunkSVD,将共现矩阵分解成两个低维矩阵(P和Q)相乘,可直接通过训练集中的观察值利用最小化均方根学习P,Q矩阵。
用户对物品的评分可以表示为,其中和分别是矩阵和对应第和的列向量,表示用户和物品的隐向量。FunkSVD核心思想是将在原始SVD上加了线性回归,使得我们可以用均方差作为损失函数来寻找P和Q的最佳值:
上式可以通过梯度下降法来求解,损失函数求偏导为:
参数更新如下:
在Funk-SVD获得巨大成功之后,研究人对其进行进一步优化工作,提出了一系列优化算法,如BiasSVD、SVD++等
虽然矩基于矩阵分解的方法原理简单,容易编程实现,具有较好的扩展性,在小规模数据上也有不错的表现。但对于互联网推荐场景的数据量级,矩阵分解方法很难得到广泛应用。
三、最后
虽然,传统召回算法具有简单、可解释性强的特点,但是也有自身的局限性:
标签召回需手动设计标签,领域知识要求高 协同过滤和矩阵分解都没有考虑用户、物品和上下文相关的特征,也没有考虑用户行为之间的相关性(如行为序列) 协同过滤和矩阵分解对无法有效解决冷启动问题
随着深度学习方法在推荐领域的应用和发展,召回层技术也开始想通过考虑更过上下文和用户行为关系的Embedding方向演化。下一篇我们开始讲深度学习召回方法
。
参考文献
[1] Linden, Greg, Brent Smith, and Jeremy York. "Amazon. com recommendations: Item-to-item collaborative filtering." IEEE Internet computing 7.1 (2003): 76-80.
[2] Zhang, Chunxia, et al. "An improved hybrid collaborative filtering algorithm based on tags and time factor." Big Data Mining and Analytics 1.2 (2018): 128-136.
[3] Aharon, Michal, Michael Elad, and Alfred Bruckstein. "K-SVD: An algorithm for designing overcomplete dictionaries for sparse representation." IEEE Transactions on signal processing 54.11 (2006): 4311-4322.
[4] Jenatton, Rodolphe, et al. "A latent factor model for highly multi-relational data." Advances in Neural Information Processing Systems 25 (NIPS 2012). 2012.
[5] Zhou, Renjie, Samamon Khemmarat, and Lixin Gao. "The impact of YouTube recommendation system on video views." Proceedings of the 10th ACM SIGCOMM conference on Internet measurement. 2010.
