




本文目的是梳理在做推荐系统时容易被大家习惯性忽视的特征构造阶段的工作。因为特征决定了最终模型能达到的上限,在推荐场景优化的初期,在特征构造上的投入不仅能快速提升业务效果,还能帮助我们加强对业务的理解,为后续的优化打好基础。
一、推荐系统一般流程
推荐系统的目的是收集用户(User)偏好,在特定场景(Context)中个性化地为其展示物品(Item),如下图所示:
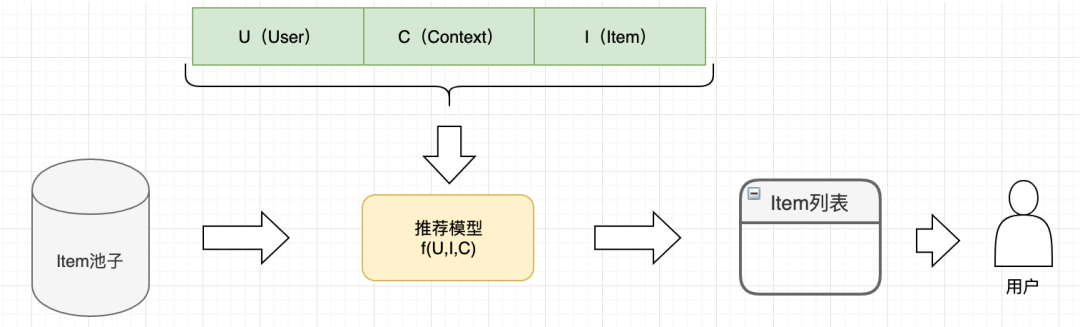
其中,第一部分包括了用户反馈、数据上报和特征构造;第二部分包括了模型优化和线上推荐。简要流程图下图所示:
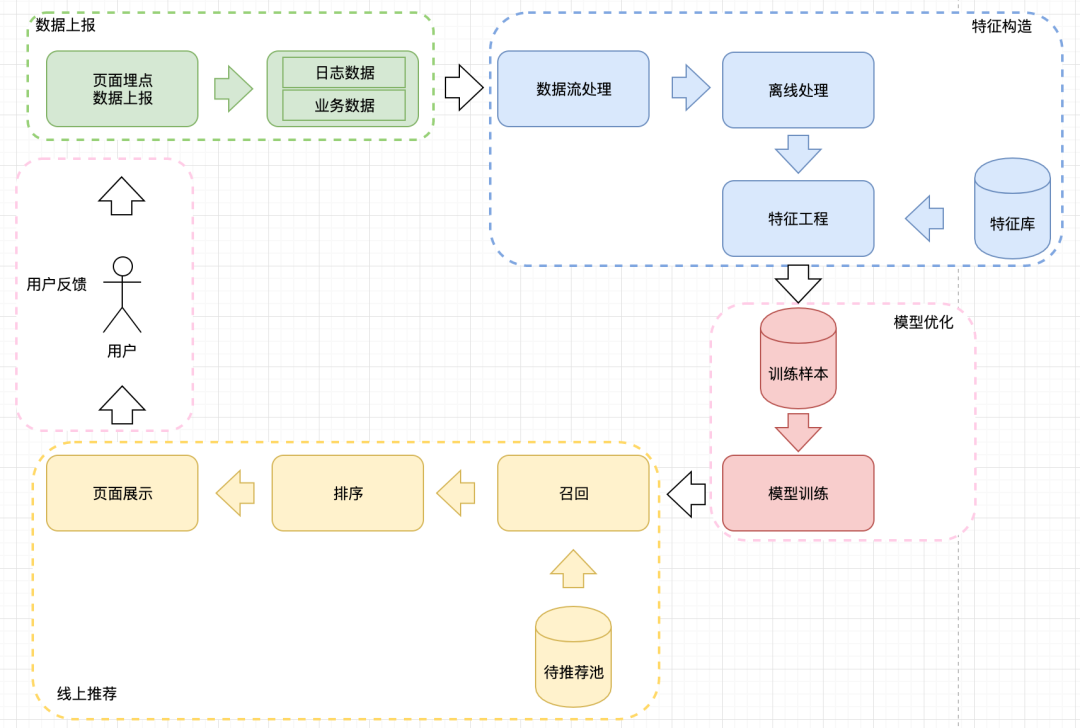
数据上报:User的线上行为会通过埋点的方式记录下来,并上报到日志系统中
特征构造:1)实时数据一般会通过Flink等流计算处理,构成推荐场景的实时特征;2)离线数据会通过离线特征工程的方式构造离线特征
模型优化:1)根据User对Item的行为构造用于模型训练的正、负样本,并结合特征库生成训练样本集,优化推荐模型
线上推荐:1)通过召回阶段,使用简单模型,从原始亿级Item中筛选出用户可能感兴趣的千级Item;2)通过排序阶段,使用更加复杂的模型来对召回的千级Item进行排序,最终将Top的Item(数十个)展示给用户
通常大家提到推荐系统时,往往会关注在模型的设计上(追求各种结构的模型),却选择性忽视特征构造这个阶段,潜台词是特征都是现成的。然而在推荐系统中,数据的质量决定了推荐效果的上限,后续的模型设计和优化都只不过是为了更好逼近这个上限而已。绕过特征来搞模型的方式难免舍本逐末了,且容易陷入为模型论的境地。
本文主要聚焦于推荐模型的起点——「特征构造」上,想跟大家一起探讨在面对推荐任务时如何构造特征、如何筛选对推荐目标有用的特征,也期望能对大家后续工作有一定启发。
下面先来聊聊针对推荐业务主要从哪些方面构造特征,然后再介绍不同类型特征的构造方法。
二、构造哪些特征
在针对特定推荐业务(场景)时,需要围绕业务目标(或优化目标)来确定特征,不能盲目的为了做特征而做。不合适的特征会在后续的存储、维护和选择上造成巨大包袱,不利于模型的后续优化。此外,随意构造的特征有时不但起不到正向效果,反而会造成模型推荐效果的下降。我个人总结构造特征的原则:
从业务目标出发,优先考虑能反映用户在当前场景所能看到的信息的特征
上面的原则可以提取三个核心点:
确定业务目标:当前场景推荐的目标是什么?是浏览深度、点击、时长? 用户在场景的状态:用户当前场景的状态、长短期兴趣偏好、设备和地域特征、用户上下文特征(之前看过什么?从哪里来的?) 用户在场景所见、所得:Item呈现给用户的有哪些信息(如标题、阅读量、互动量、标签、摘要等),Item被什么样的用户消费过?
在确定好目标之后,基本上就可以从Item、User、和场景这三个角度来考虑构造响应的特征。
下面以比较常见的信息流推荐为例(如下图所示),目标是希望推给用户的内容都是用户喜欢的。那这个喜欢如何衡量呢?我们可以通过用户对Item的点击、点赞、评论、分享、收藏、观看时长等数据来综合衡量用户对该Item的喜欢程度。
本文为了简单起见,就以点击为目标:喜欢推给用户的内容,用户都会点击进去(「P.S. 这里会造成标题党引流量的内容高频出现的问题,并非本文的重点,后续会专门介绍如何通过多目标学习来解决这类问题」)。
1、Item特征
在构造Item特征时,首先从场景和目标出发,找到能在场景中刻画与目标相关的特征,主要可以分为:1)页面可见元素;2)内容本身;3)潜在特征
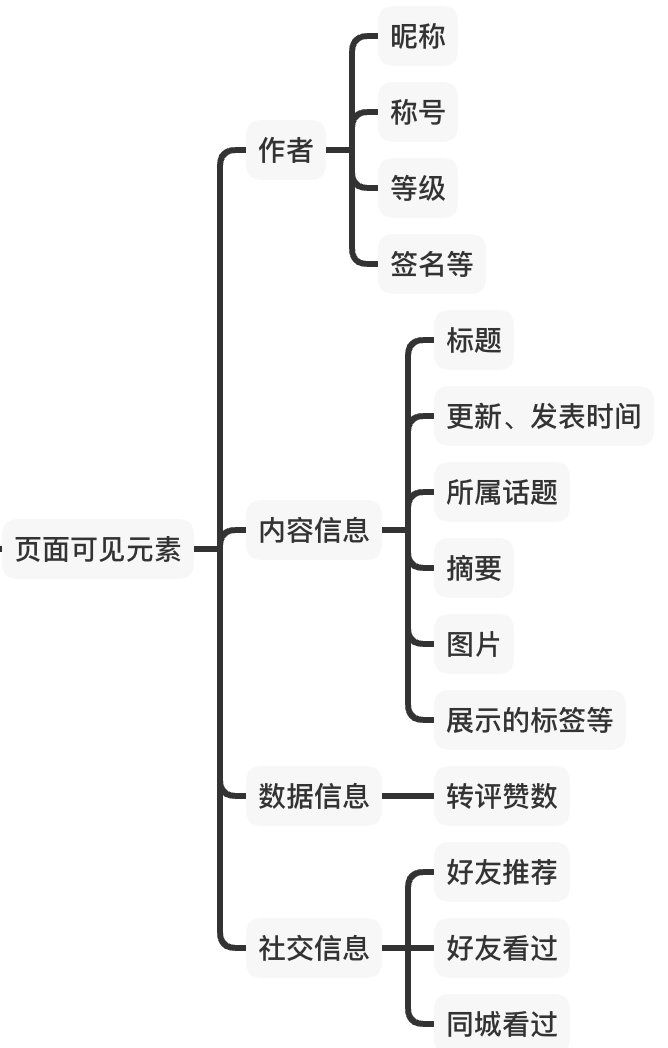
A) 页面可见元素
为什么要优先考虑刻画页面的可见元素呢?因为用户在决定是否点击Item时,首先看到的是页面展示信息。而Item详情往往是用户点进去之后才看到的。如果两个Item的展示元素完全相同,点进去之后的内容不同,用户对它们的点击率是不会有显著差异的,因为用户赖以判断是否点击的信息是一样的。
因此,对页面可见元素的刻画主要考虑内容在用户面前的展示信息,如下图所示:
B) 内容本身
与刻画“页面可见元素”不同的是,对内容本身的刻画着重于内容的基本信息,如内容是关于什么的、作者是谁等等,大致分为如下四类:
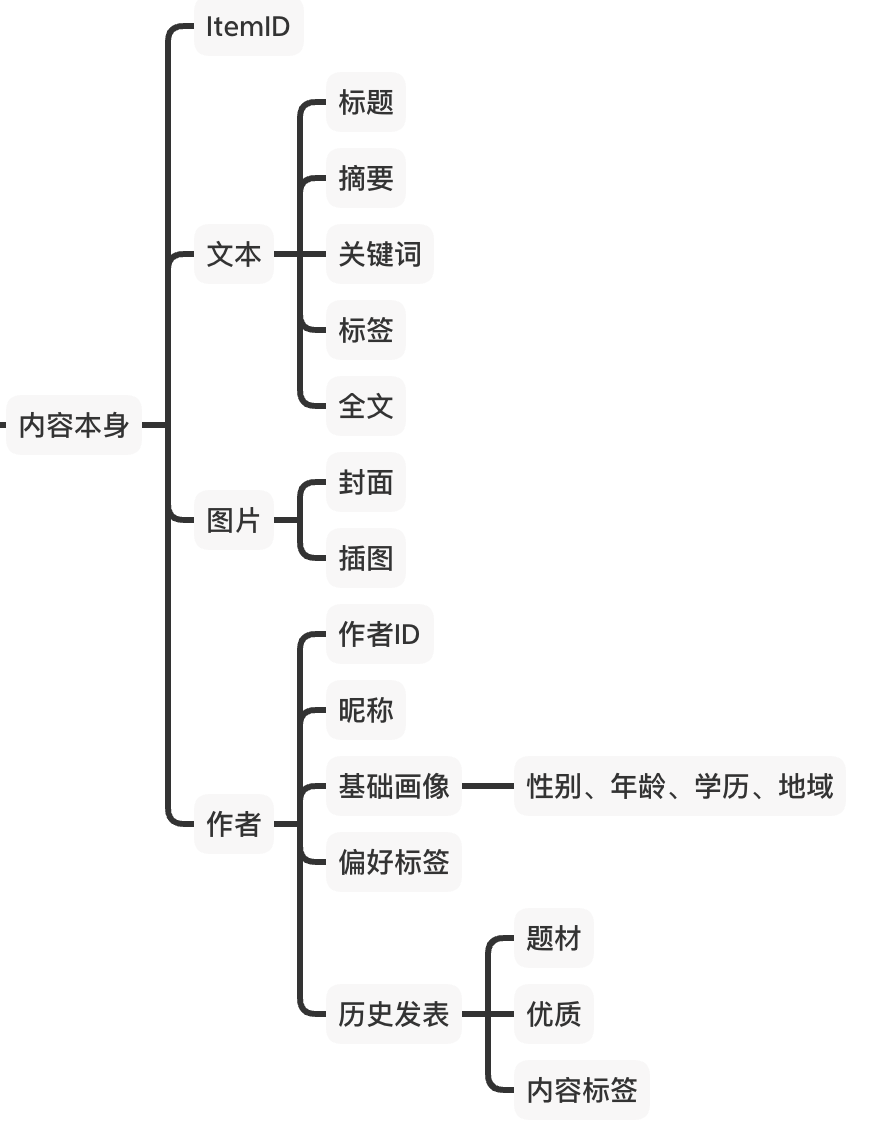
C) 潜在特征
这里主要通过内容的受众用户特点,来构造与推荐目标相关的指标特征,大致分为如下三类:
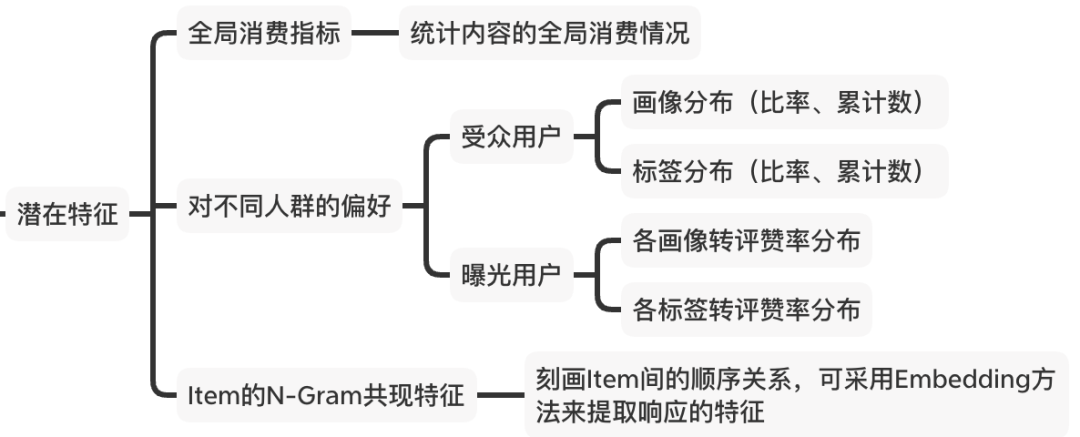
2、User特征
在刻画玩Item特征之后,就需要通过构造User特征来让后续模型能了解我们的用户。User特征主要包括固有特征和行为偏好特征。
A) 固有特征
固有特征也称用户属性,主要是用来刻画用户的长期或稳定的特征,如基础画像、长短期兴趣等:
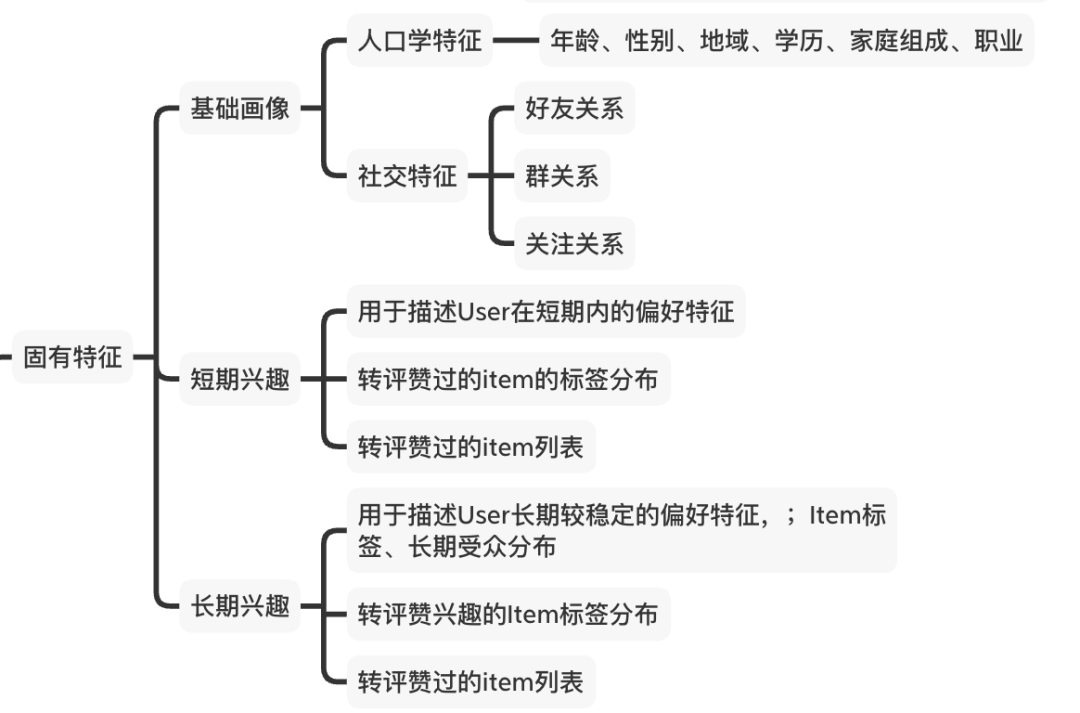
B) 行为偏好
行为偏好特征主要是用来刻画用户在当前场景的行为特点。如最近转评赞的内容、标签、作者,关注的人,互动的人,负反馈的信息等。行为偏好可以分为最近行为和负反馈两类,可以通过固定时间窗口来构建:
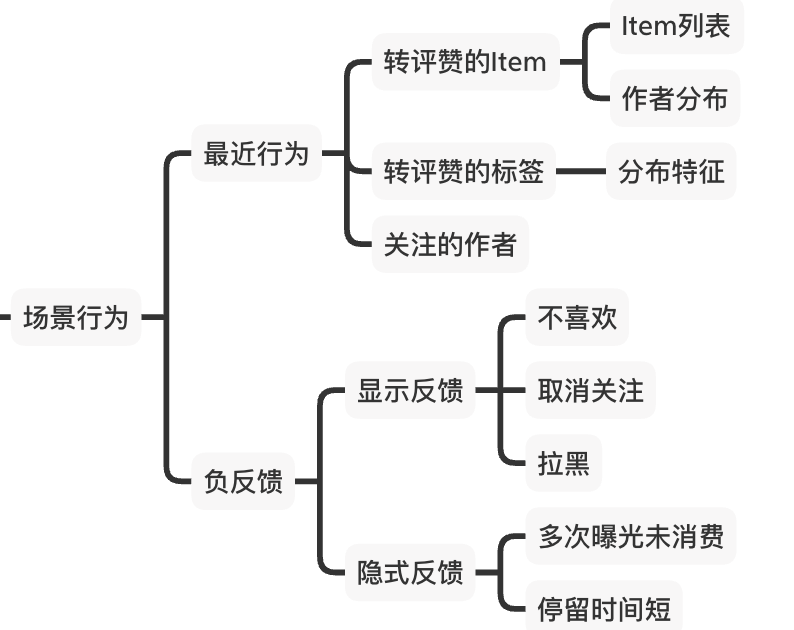
3、场景特征
场景特征是用于刻画User在对Item进行操作时所处的环境的状态和特征,如用户所在位置、时间、天气、用户的心情、用户所在产品的路径等等。这些场景数据对用户的决策非常重要,有时甚至是起决定性作用。比如,外卖平台这类LBS的产品,在给User推荐餐厅时一定要是在用户所在位置或者用户指定位置附近的。合理使用场景特征可以使推荐更精准、更有时效性。
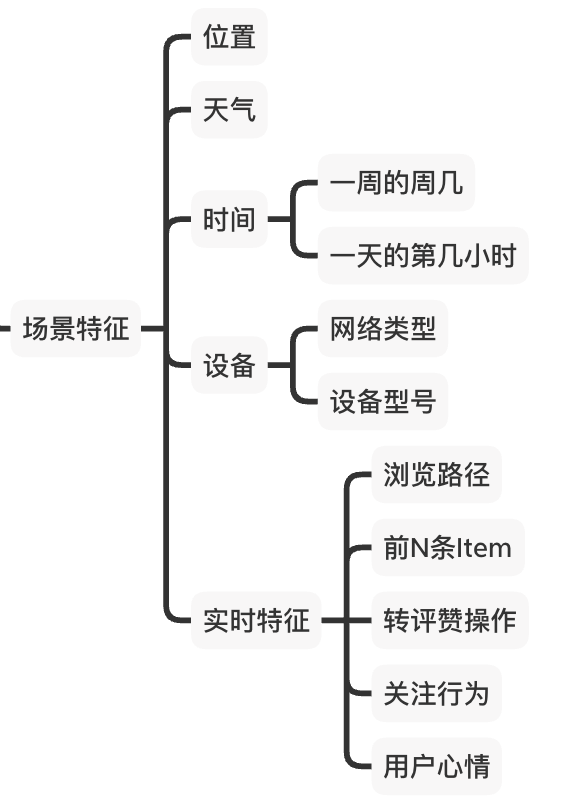
在针对特定场景构造特征时,可以参考上面的逻辑梳理可以构造的特征;然后根据人力和进度对Item、User和Context特征进行优先级排序,确保优先开发对User和Item覆盖度高且跟目标相对契合的特征;
最后,可以根据特征的刻画类型,构造交叉特征(如用户性别ⓧItem受众性别分布
、用户偏好标签ⓧ内容标签
等等)。此外,还可以构造二阶交叉特征,如用户性别&年龄ⓧItem受众的性别&年龄分布
。
需要注意的是:构造交叉特征时要权衡特征效果和特征大小,比如User_Id与Item_Id的交叉特征就不要轻易构造(非常稀疏)。交叉特征还需要有一定的解释性,如性别&年龄ⓧItem标签
可以用来刻画相同性别&年龄的用户可能会对相似文章感兴趣。
三、特征开发方法
上一节梳理完各种Item、User和Context特征之后,需要动手开发相应特征。但在此之前前,我们还要先看下用于构造特征的数据长什么样子(数据的组织形式),一般可以分为如下类型:
结构化:可以存储在关系型数据库的表中,每列代表一个属性或特征,每行是一个数据记录(如Item、User、行为等)
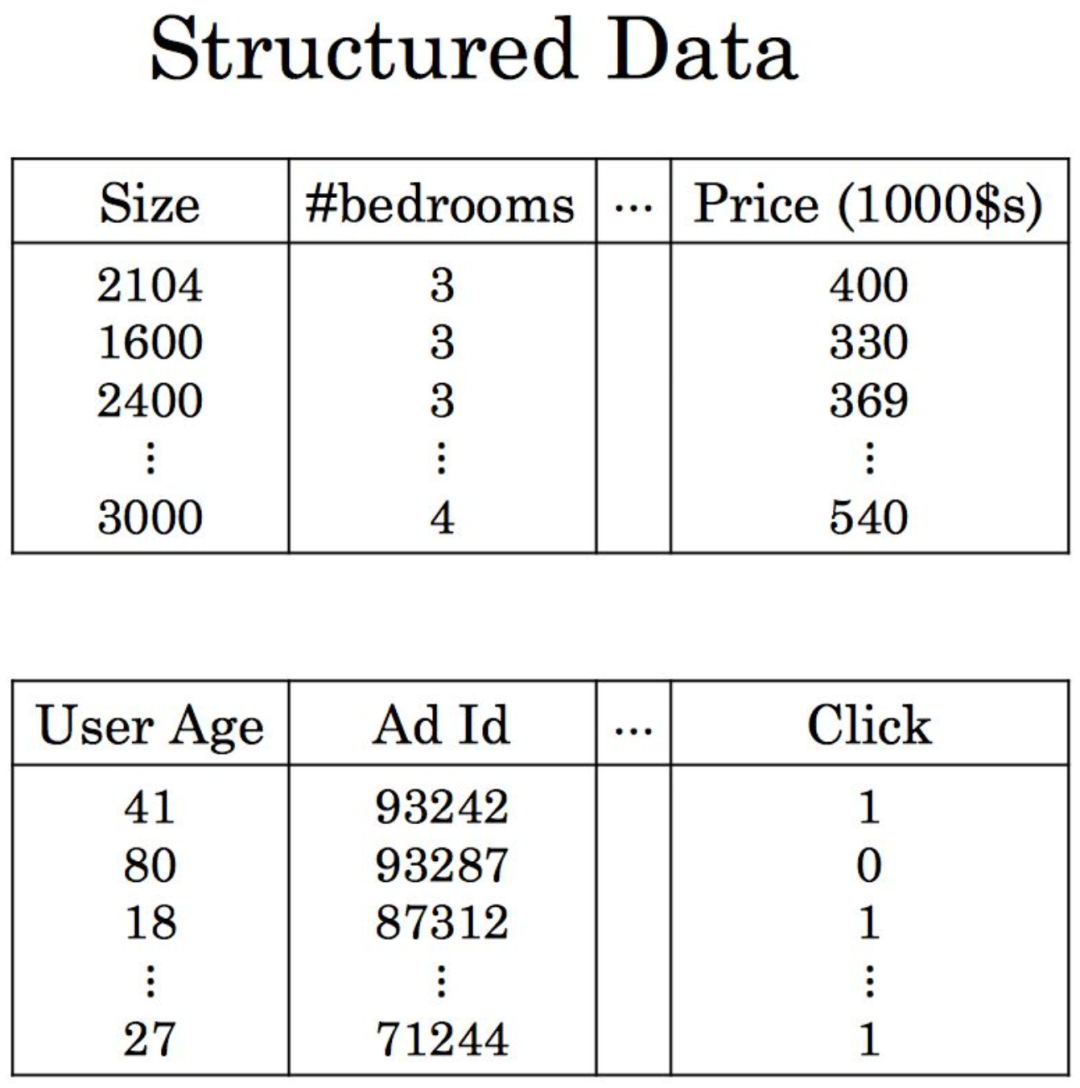
半结构化:数据不符合关系型数据库严格的结构,但有一定规律或者规范,可以利用特殊的标记或者规则来分隔语义元素。常见的有XML、Json类数据。Json数据格式如下:
{
"people": [
{
"firstName": "Brett",
"lastName": "McLaughlin",
"email": "aaaa"
},
{
"firstName": "Jason",
"lastName": "Hunter",
"email": "bbbb"
},
{
"firstName": "Elliotte",
"lastName": "Harold",
"email": "cccc"
}
]
}有时候用户的行为需要用半结构化数据来上报,这时半结构化数据可以作为协议中的一个字段。比如采用info字段来刻画用户视频观看时长、记录用户拖动进度条的具体信息等等。当然这些也完全可以做成结构化,但不同类型的内容和action要上报的信息并不相同,这样会导致协议字段繁多,久而久之会不好维护。
半结构化数据就可以使上报更灵活。但会增加后续数据处理难度。具体还需要根据业务特点来做权衡。
非结构化:数据结构不规则,没有预定义的数据模型,不方便用数据库二维逻辑表来表示的数据。如文本、图片、HTML、各类报表、图像和音频/视频信息。

了解数据的组织形式之后,我们需要再从特征类型这个维度来梳理这些要构造的特征,从而方便我们理清相同类型特征的构造方法,大致可以分为如下类型:
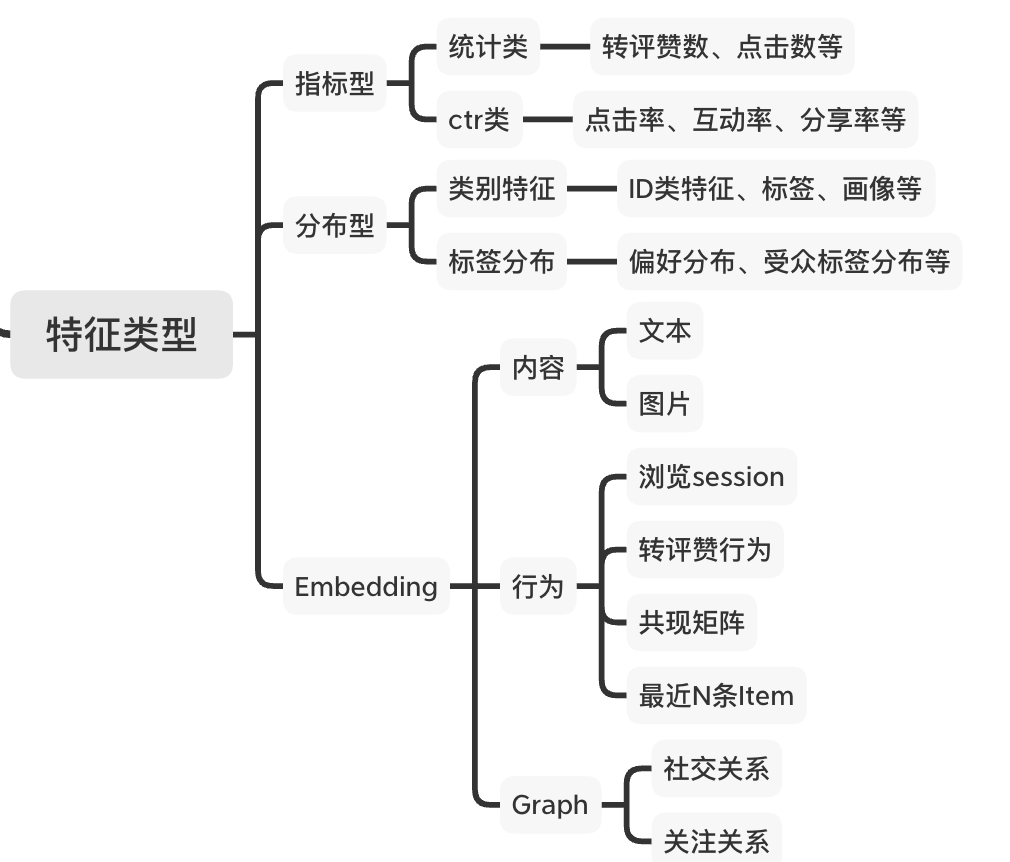
特征总体可以分为:
指标型:用来描述Item或User在该指标上的强弱特征,如播放量、分享率等 分布型:用来描述Item或User在某一特征域的偏好特征,如受众的性别分布、各年龄段的点击率等 Embedding型:通过Embedding方法对内容、行为或Graph提取的多维稠密特征,如文本和图片向量
下面分别介绍几种对应特征类型的开发方法。
1、指标型
指标类型特征开发相对比较简单,一般可以通过HiveSQL
完成。
对于统计类特征,通过指定维度来统计对应指标的量级,比如要构造Item最近7天的点击量、收藏量,作者的新增关注数等等:
对于CTR类特征,一般是分别统计CTR类的分子(如点击)和分母(如曝光),然后相除得到。有时候会面临曝光量过少,CTR波动很大的情况,可以通过Wilson
校准来缓解这个问题。
2、分布型
分布类型特征本质是将<User, Item, action>
的行为对,映射到<User, Tag, action>
或者<Item, Tag, action>
上。因此,不仅要统计行为协议的数据,还要考虑User或Item的标签属性。可以通过HiveSQL
来对行为和标签数据进行Jon
,最后统计对应标签的分布特征。
对于类别性特征,一般统计各标签的对应指标(如点击、转评赞、收藏等)的数量。然后再在同一特征域中,采用softmax
进行预处理,得到User或Item的的标签score。
此外,在对比不同人群的偏好分布时,可以采用TGI指数来构建(可以参考之前的文章《写在第一篇:TGI指数 (Target Group Index)》,这样的特征可以反映出人群对某些标签的偏好。
3、Embedding型
Embedding类型的特征一般需要通过模型来提取,这里的方法相对比较多,具体可以参考之前的文章《用万字长文聊一聊 Embedding 技术》。下面简单总结一下对于内容、行为和Graph的Embedding方法:
A) 内容
内容一般可以分为文本数据和图片数据:
文本:一般用NLP技术进行处理转化,最终转化为数值特征。1)传统的方法如TF-IDF、LDA等将每篇文档转化为一个高维的向量表示;2)静态词向量方法:基于Word2Vec等方法将训练高维词向量,再采用词向量来刻画文章;3)动态词向量方法:采用BERT或GPT等模型,将整篇文章转化成高维向量 图片:一般采用CV领域的技术来处理,最终转化为数值特征。1)传统方法如SIFT、Haar等特征提取方法,将一张图片提取成高维向量;2)卷积特征提取:采用预训练好的CNN模型,对整张图片提取特征;3)语义提取:采用图片语义提取模型,将图片中的内容转换成文本
B) 行为
行为数据可以采用行为序列或者构造行为图来表示:
行为序列:将用户的操作session中的指定行为(如点击)提取出来,构成Item序列,然后将Item当做词,采用NLP的文本向量化方法来处理,最终将Item作为词向量提取出来 行为图:这里的难点在于如何构造行为图,可以构造Item之间的流转图,需要统计Item和Item之间的边的权重(如边 <item1, item2, weight>
表示点击item1
之后再点击item2
的用户数。在构造行为图之后,可以采用DeepWalk
或者Node2vec
的算法提取图中item的向量特征
C) Graph
针对Graph(如社交网络、关注网络)的方法大致分为两大类:1)浅层图模型;2)深度图模型
浅层图模型:主要是采用 random-walk + skip-gram
模式的embedding方法。主要是通过在图中采用随机游走策略来生成多条节点列表,然后将每个列表相当于含有多个单词(图中的节点)的句子,再用skip-gram模型来训练每个节点的向量。这些方法主要包括DeepWalk、Node2vec、Metapath2vec等。深度图模型:将图与深度模型结合,实现end-to-end训练模型,从而在图中提取拓扑图的空间特征。主要分为四大类:Graph Convolution Networks (GCN),Graph Attention Networks (GAT),Graph AutoEncoder (GAE)和Graph Generative Networks (GGN)
更详细的介绍可以参考《用万字长文聊一聊 Embedding 技术》
四、总结
本文主要目的是梳理在做推荐系统时容易被大家习惯性忽视的“「特征构造」”阶段的工作。因为特征决定了最终模型能达到的上限,在推荐场景优化的初期,在特征构造上的投入不仅能快速提升业务效果,还能帮助我们加强对业务的理解,为后续的优化打好基础。
最后想说的是,推荐是一个系统性的工程,数据上报、特征构造、模型优化、线上推荐以及效果反馈等任何一个模块都会成为推荐的瓶颈。因此,不要习惯性的忽视某个模块的重要性,只有对每个模块的卡点有清晰认识才能在未来走得更远。
参考文献
[1] Binomial proportion confidence interval
[2] 结构化数据与非结构化数据的区别
[3] 腾讯QQ大数据:机器学习建模问题中的特征构造方法
[4] 写在第一篇:TGI指数 (Target Group Index)
[6] Wilson, E. B. (1927). "Probable inference, the law of succession, and statistical inference". Journal of the American Statistical Association. 22 (158): 209–212.
[7] Ramos, Juan. "Using tf-idf to determine word relevance in document queries." Proceedings of the first instructional conference on machine learning. Vol. 242. No. 1. 2003.
[8] Blei, David M., Andrew Y. Ng, and Michael I. Jordan. "Latent dirichlet allocation." the Journal of machine Learning research 3 (2003): 993-1022.
[9] Rublee, Ethan, et al. "ORB: An efficient alternative to SIFT or SURF." 2011 International conference on computer vision. Ieee, 2011.
[10] Lienhart, Rainer, and Jochen Maydt. "An extended set of haar-like features for rapid object detection." Proceedings. international conference on image processing. Vol. 1. IEEE, 2002.
