点击下方,关注我们

介绍数据沿袭 (Data Lineage)
首先,什么是数据沿袭?数据沿袭是一个分配给表中每个列的标记,它标识着列的值来自数据模型中的原始列。
例如,下面的查询返回 Product 表中的不同类别:
EVALUATE VALUES ( 'Product'[Category] )
查询返回一个包含8个不同类别的表:

由 VALUES 返回的表包含8个字符串。然而,它们不仅仅是字符串。DAX 知道这些字符串来自 Product [Category] 列。因此,作为 Product 表的列,它们继承了通过关系传播筛选的方式筛选模型中其他表的能力。这就是为什么一个正在迭代 VALUES ( Product[Category] ) 的上下文转换可以筛选 Sales 表的原因。
例如下面的查询:
EVALUATEADDCOLUMNS (VALUES ( 'Product'[Category] ),"Amt", [Sales Amount])
查询的结果包含每个产品类别的销售额:
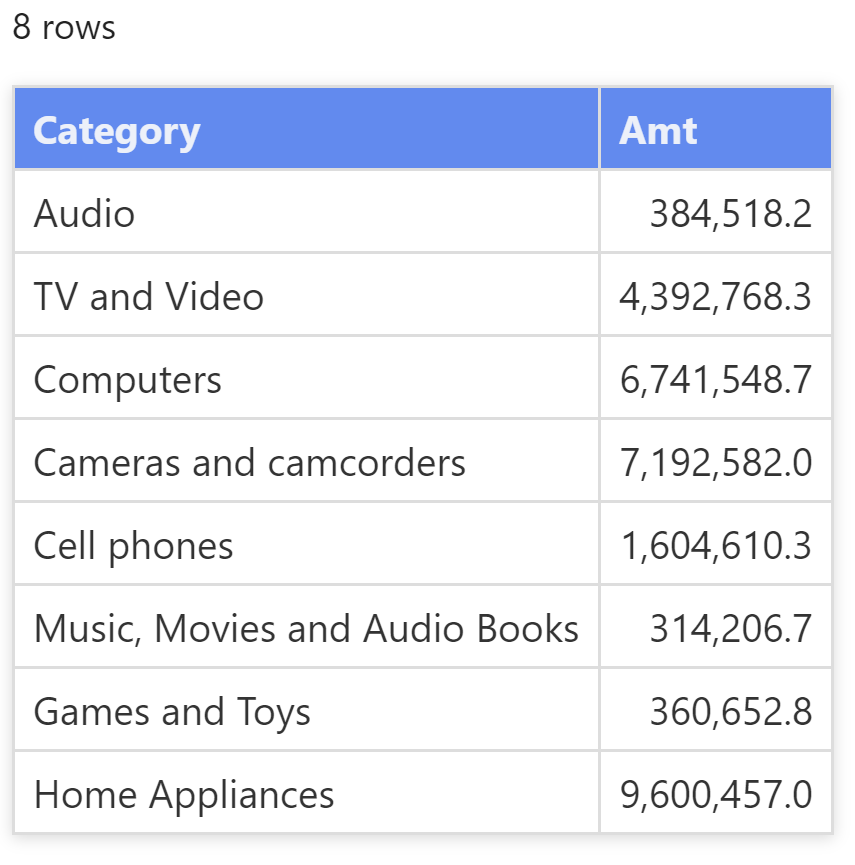
字符串 "Audio" 本身不能筛选 Sales 表。你可以通过运行以下查询轻松地验证这一点:
EVALUATEVAR Categories =DATATABLE ("Category", STRING,{{ "Category" },{ "Audio" },{ "TV and Video" },{ "Computers" },{ "Cameras and camcorders" },{ "Cell phones" },{ "Music, Movies and Audio Books" },{ "Games and Toys" },{ "Home Appliances" }})RETURNADDCOLUMNS ( Categories, "Amt", [Sales Amount] )
以上查询在 "Amt" 列中为所有行返回相同的值:
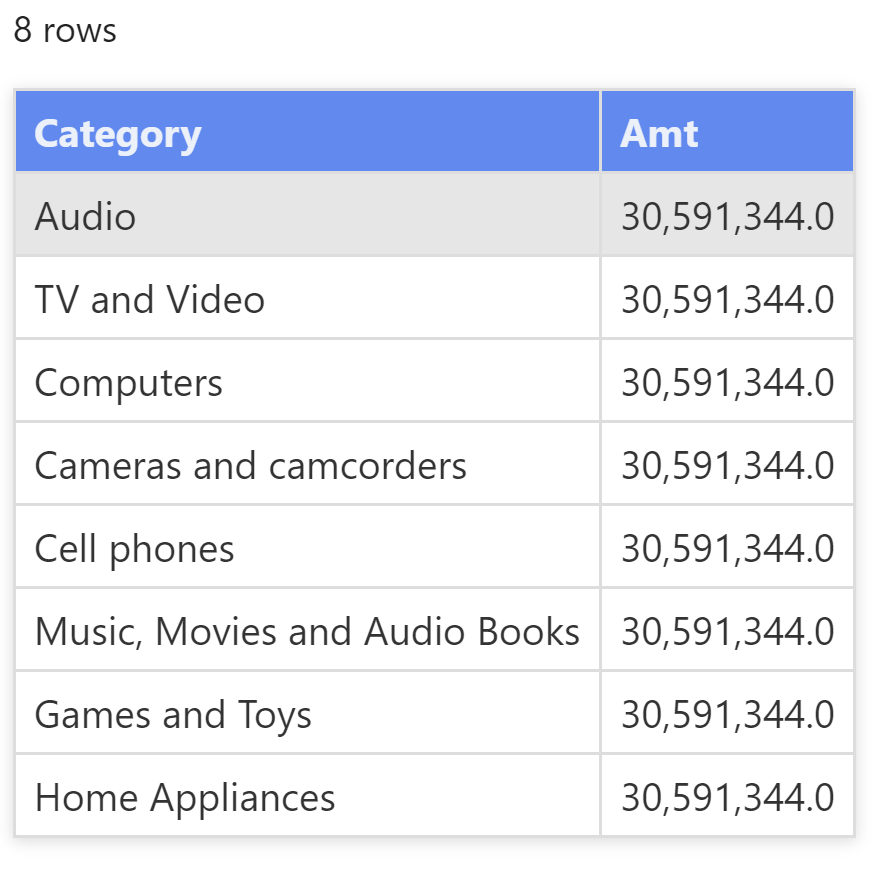
列名和列内容都不重要。真正重要的是一个列的数据沿袭,这个列即是已从中检索值的原始列。即使列被重命名,其仍然继承了数据沿袭。实际上,以下查询为每一行返回不同的值:
EVALUATEADDCOLUMNS (SELECTCOLUMNS (VALUES ( 'Product'[Category] ),"New name for Category", 'Product'[Category]),"Amt", [Sales Amount])
查询的结果为每一行返回不同的值:
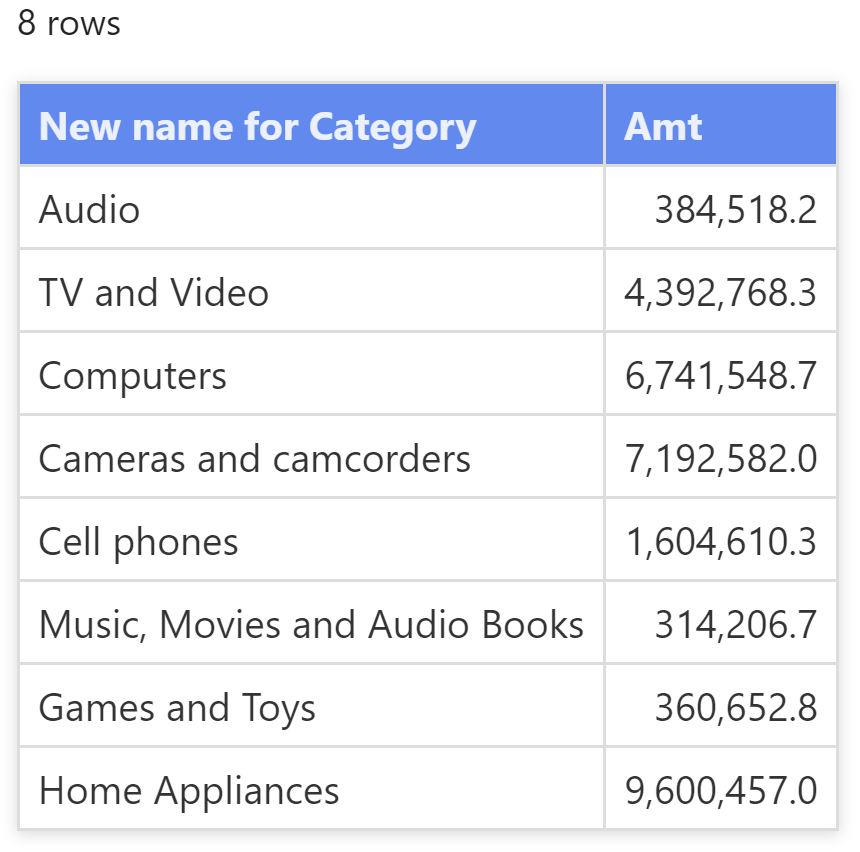
"New name for Category" 列继承了 Product [Category] 列的数据沿袭。因此,尽管结果中的列名与原始列名不同,DAX知道新列中的值来源于原始列 Product [Category],所以值筛选了 Product [Category] 列, 输出显示按类别划分的销售额。
只要表达式仅由一个基列(模型中的列,包含新建列)的引用组成,就会继承数据沿袭。例如,在前一个表达式的 Product [Category] 列中添加一个空字符串不会更改列的内容,但会破坏数据沿袭。在下面的代码中,"New name for Category" 由一个表达式定义而不仅仅是一个基列的引用。因此,新列的新的数据沿袭与模型中的任何列都无关。
EVALUATEADDCOLUMNS (SELECTCOLUMNS (VALUES ( 'Product'[Category] ),"New name for Category", 'Product'[Category] & ""),"Amt", [Sales Amount])
不出所料,结果在 "Amt" 列中的所有行显示相同的值。
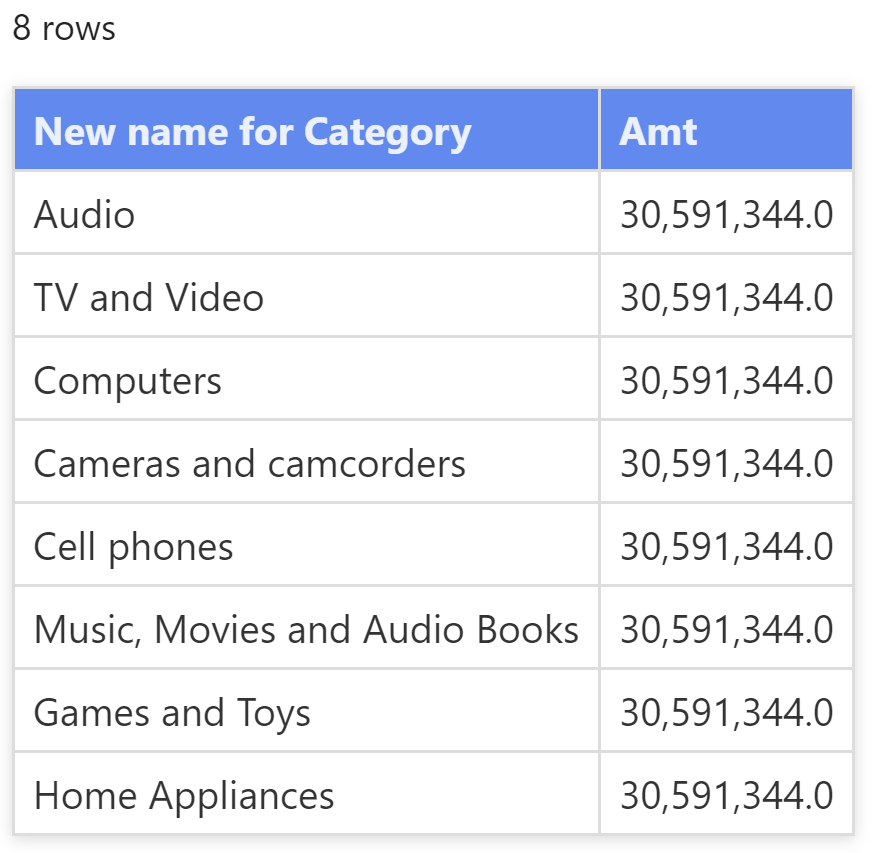
即使一个表包含来自不同表的列,每个列都有自己的数据沿袭。因此,一个表表达式的结果可以同时对多个表应用筛选器。在下面的查询中可以清楚地看到这一点,该查询包含 Product [Category] 和 Date [Calendar Year] 列。两列都通过来自上下文转换的筛选上下文将它们的筛选器应用于 Sales Amount 度量值。
EVALUATEFILTER (ADDCOLUMNS (CROSSJOIN (VALUES ( 'Product'[Category] ),VALUES ( 'Date'[Calendar Year] )),"Amt", [Sales Amount]),[Amt] > 0)
以下是查询的部分结果展示,其显示了给定类别和年份的销售额。Category 和 Calendar Year 列都在筛选 Sales Amount 度量值。
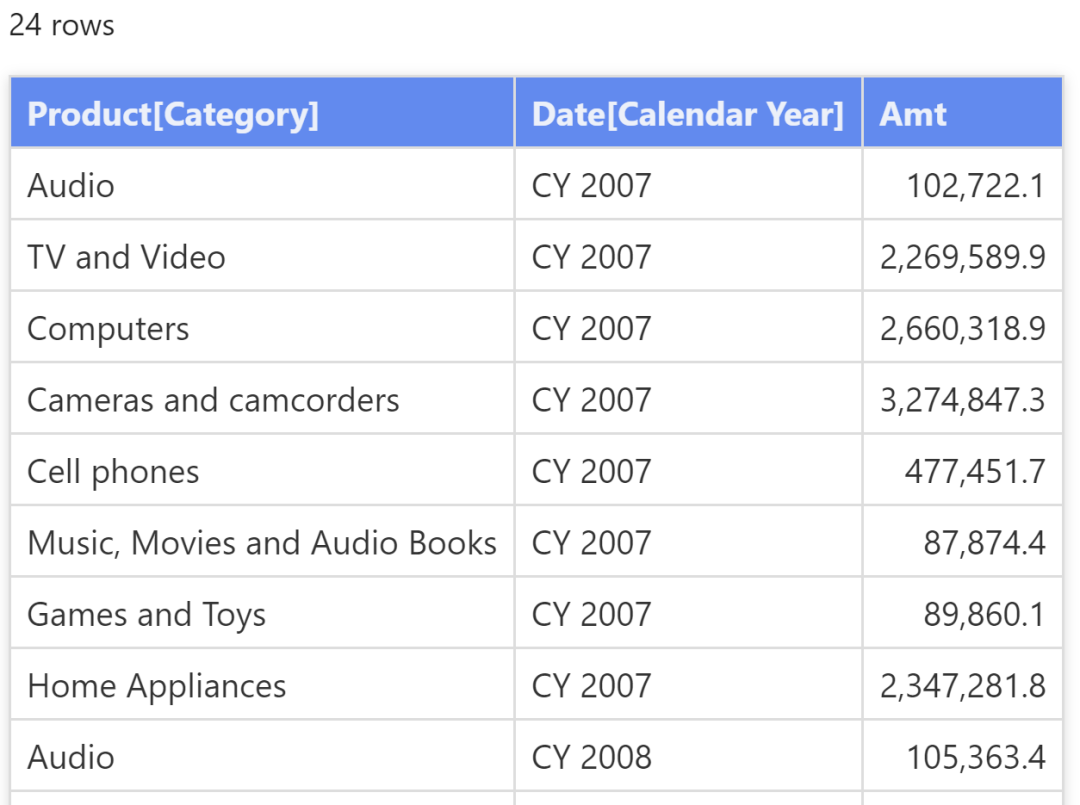
即使引擎以完全自动的方式保存和维护数据沿袭,开发人员也可以选择更改表的数据沿袭。在 DAX 中, 使用 TREATAS 函数可以更改表的数据沿袭。TREATAS 接受一个基表或者表的表达式作为它的第一个参数,后面是一组基列的引用。TREATAS 返回相同的输入表(第一个参数),其中每一个列带有特别作为参数引用的基列的数据沿袭标记。如果表中包含某些 - 在用于更改数据沿袭的基列中 - 不存在的值,则 TREATAS 将从输入表中删除这些值。
例如,下面的查询构建了一个带有一列字符串的表,其中一个(突出显示的 "Computers and geeky stuff" )不对应于模型中的任何类别。我们使用 TREATAS 将表的数据沿袭强制成为 Product [Category] 列的数据沿袭。
EVALUATEVAR Categories =DATATABLE ("Category", STRING,{{ "Audio" },{ "TV and Video" },{ "Computers and geeky stuff" },{ "Cameras and camcorders" },{ "Cell phones" },{ "Music, Movies and Audio Books" },{ "Games and Toys" },{ "Home Appliances" }})RETURNADDCOLUMNS (TREATAS (Categories,'Product'[Category]),"Amt", [Sales Amount])
查询结果是按类别划分的销售额,但不包含 "Computers and geeky stuff" 这一行。
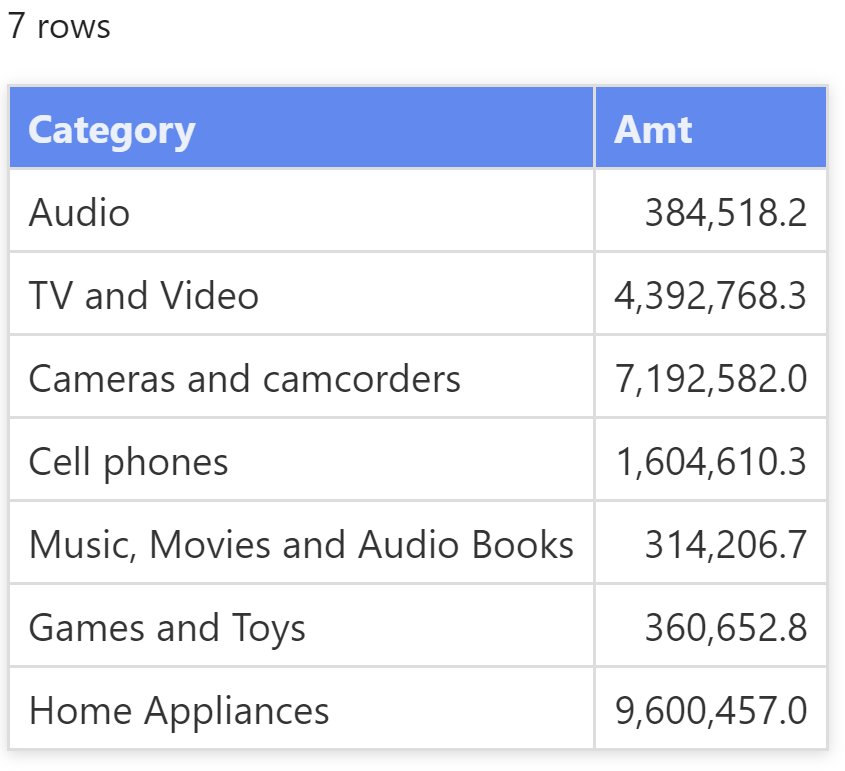
在数据模型中的 Product [Category] 列中没有名为 "Computers and geeky stuff" 的类别,因此,为了完成数据沿袭的转换,TREATAS 必须从输出的表中删除这一行。
操纵数据沿袭
现在我们已经理解了什么是数据沿袭,以及如何使用 TREATAS 来操纵它,接下来是一个例子,其中使用TREATAS 和数据沿袭操作生成一段非常优雅的 DAX 代码。考虑一个计算需求:每个产品在第一个销售日的销售额。同样的计算对客户、商店或任何其他维度都有意义,但我们在本例中只考虑产品。
每个产品都有不同的首次销售日期。其中一个解决方案是在逐个迭代产品的基础上计算有销售的第一个日期,然后计算在该日期的销售额,最后对所有产品聚合结果。代码如下:
FirstDaySales v1 =SUMX ('Product',VAR FirstSaleDate =CALCULATE ( MIN ( 'Sales'[Order Date] ) )RETURNCALCULATE ( [Sales Amount], 'Date'[Date] = FirstSaleDate ))
由 FirstDaySales 度量值产生的结果显示了每个品牌的首日销售额。
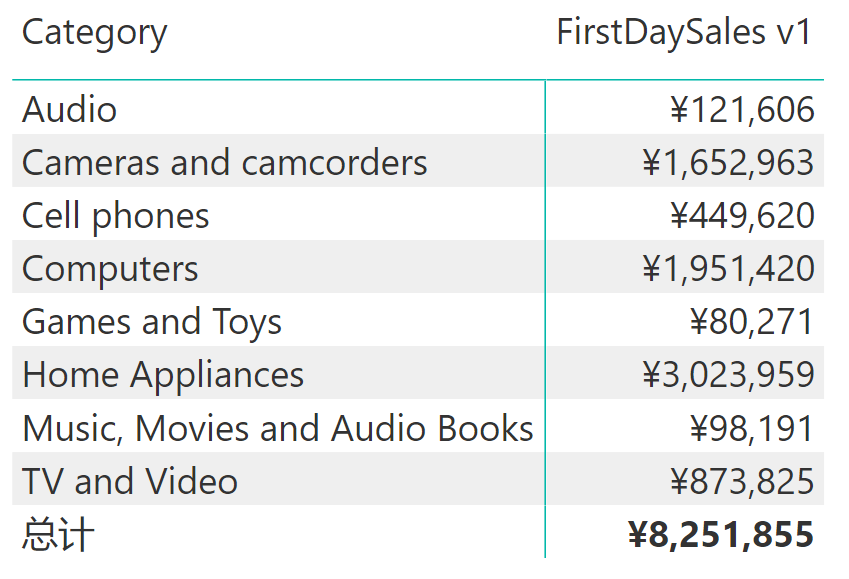
结果是正确的,但是上面的代码并不是最优的。实际上,它迭代 Product 表,为每个产品生成一个上下文转换,同时在 Date 上应用一个筛选器,而没有利用任何关系。这并不是说这是一个糟糕的代码,它只是没有它应有的优雅。我们现在将看到这个度量的替代版本,它以效率更高的方式返回相同的结果。
正确方向的第一步是构建一个表,其中包含产品名称和相应的第一次销售日期,然后使用这对值对 Sales 表应用筛选器。下面的代码是前一个代码的改进版本,但是它仍然不是最优的,因为 SUMX 仍然为每个产品生成一个上下文转换:
FirstDaySales v2 :=VAR ProductsWithSales =SUMMARIZE (Sales,'Product'[Product Name])VAR ProductsAndFirstDate =ADDCOLUMNS (ProductsWithSales,"Date First Sale", CALCULATE (MIN ( Sales[Order Date] )))VAR Result =SUMX (ProductsAndFirstDate,VAR DateFirstSale = [Date First Sale]RETURN CALCULATE ([Sales Amount],'Date'[Date] = DateFirstSale))RETURN Result
但是,现在将注意力集中在 ProductsAndFirstDate 变量中 ADDCOLUMNS 的结果上,它包含一列产品名称和一列日期。如果用作 CALCULATE 的筛选器参数,它将筛选一列产品和一列日期,从而避免为每一行生成一个上下文转换。因此,这个版本(不幸的是,这个版本是错误的)会更好:
FirstDaySales v3 (wrong) :=VAR ProductsWithSales =SUMMARIZE (Sales,'Product'[Product Name])VAR ProductsAndFirstDate =ADDCOLUMNS (ProductsWithSales,"Date First Sale", CALCULATE (MIN ( Sales[Order Date] )))VAR Result =CALCULATE ([Sales Amount],ProductsAndFirstDate)RETURN Result
如你所见,SUMX 迭代器从算法中消失了。不过,这个版本的代码是有缺陷的,因为它返回与 Sales Amount 相同的值,而没有应用任何筛选器。确实,在ProductsAndFirstDate 变量中的 ADDCOLUMNS 的结果中包含一列产品和一列日期; 但是从数据沿袭角度来看,产品名称继承了模型中 Product [Product Name] 列的数据沿袭,而作为 MIN 表达式结果的 First Sale 列中的日期没有继承日期列的数据沿袭。Firstsale 列有它自己的数据沿袭,其与数据模型中的其他表无关。
解决方案是更改 First Sale 列的数据沿袭,以强制它为模型中 Date [Date] 列的数据沿袭。TREATAS 的存在就是为了这个目的。正确优化的度量值如下:
FirstDaySales v4 :=VAR ProductsWithSales =SUMMARIZE (Sales,'Product'[Product Name])VAR ProductsAndFirstDate =ADDCOLUMNS (ProductsWithSales,"First Sale", CALCULATE (MIN ( Sales[Order Date] )))VAR ProductsAndFirstDateWithCorrectLineage =TREATAS (ProductsAndFirstDate,'Product'[Product Name],'Date'[Date])VAR Result =CALCULATE ([Sales Amount],ProductsAndFirstDateWithCorrectLineage)RETURN Result
像最后一个这样的解决方案不会作为模式的主要解决方案出现在我们大多数人的脑海中。然而,从性能方面来看,这段代码几乎是最佳的,这意味着我没有找到一个性能更好的版本——如果你确实找到了一个更好的版本,欢迎在评论中指出。一旦熟悉了数据沿袭,理解了筛选是如何通过使用数据沿袭从一个表转移到另一个表,你就会开始考虑类似上面的解决方案。
结论
在 DAX 开发人员的工具包中,理解数据沿袭是一项重要的技能。它不像行上下文、筛选上下文和上下文转换那么初级。然而,这无疑是 DAX 专业开发者区别于其他开发者的技能之一。
以下是关于数据沿袭的重要概念回顾:
数据沿袭是一个分配给表中每个列的标记,它标识着列的值来自数据模型中的原始列。
任何表中的列都有自己的数据沿袭,不管这个表是由变量定义的表还是模型中的表。能否筛选数据模型的关键是: 数据沿袭。
如果值所属的列继承了模型中原始列的数据沿袭,则 DAX 知道值来源于原始列,因此可以筛选数据模型。
如果值所属的列的数据沿袭和模型的任何表都不相关, 则不能筛选数据模型。
在类似 ADDCOLUMNS 和 SELECTCOLUMNS 可以创建新列的表函数中定义新列时:
简单的基列引用将继承该列的数据沿袭,不是只由基列引用组成的表达式将丢失数据沿袭。
列的名称不重要,只要用于定义新列的表达式仅仅由一个基列的引用组成,即使改变列的名称,以新名称命名的新列仍然继承了引用的基列的数据沿袭。
在 DAX 中,我们使用 TREATAS 函数修改表的数据沿袭。
代码的性能优化和结果准确性同等重要。当你试图通过嵌套迭代执行来自上下文转换的筛选时,虽然代码看起来很简洁,然而由于 DAX 引擎将对外层的迭代执行次优的查询计划 - 外层的迭代需要在内存中创建临时表用于存储最内层迭代产生的中间结果,这将导致内存消耗的增加和性能的下降。
最佳实践
当需要筛选多个列非所有可能的组合时,为了性能最优:
首先使用 ADDCOLUMNS 或 SELECTCOLUMNS 创建一个临时表存储要筛选的值。
然后使用 TREATAS 函数修改这个表的数据沿袭, 将其强制为基列的数据沿袭。
最后将继承原始列的数据沿袭的表作为 CALCULATE CALCULATETABLE 的筛选参数。
基列: 模型中存在的列,包含使用 DAX 表达式新建的列。
基表:模型中存在的表。

近期热读
“提醒下哦,阅读过的小伙伴们都关注并加星了,在高手之路上可不要掉队哦”