




上篇图文openGauss数据库源码解析系列文章——SQL引擎源码解析(一),从SQL引擎概述和SQL解析两方面进行了详细论述,本篇将接着从SQL引擎的查询优化展开介绍。
三、查询优化
openGauss数据库的查询优化过程功能比较明晰,从源代码组织的角度来看,相关代码分布在不同的目录下,如表1所示。
表1 查询优化模块说明
模块 | 目录 | 说明 |
查询重写 | src/gausskernel/optimizer/prep | 主要包括子查询优化、谓词化简及正则化、谓词传递闭包等查询重写优化技术 |
统计信息 | src/gausskernel/optimizer/commands/analyze.cpp | 生成各种类型的统计信息,供选择率估算、行数估算、代价估算使用 |
代价估算 | src/common/backend/utils/adt/selfuncs.cpp src/gausskernel/optimizer/path/costsize.cpp | 进行选择率估算、行数估算、代价估算 |
物理路径 | src/gausskernel/optimizer/path | 生成物理路径 |
动态规划 | src/gausskernel/optimizer/plan | 通过动态规划方法对物理路径进行搜索 |
遗传算法 | src/gausskernel/optimizer/geqo | 通过遗传算法对物理路径进行搜索 |
(一)查询重写
SQL语言是丰富多样的,非常的灵活,不同的开发人员依据经验的不同,手写的SQL语句也是各式各样,另外还可以通过工具自动生成。SQL语言是一种描述性语言,数据库的使用者只是描述了想要的结果,而不关心数据的具体获取方式,输入数据库的SQL语言很难做到是以最优形式表示的,往往隐含了一些冗余信息,这些信息可以被挖掘用来生成更加高效的SQL语句。查询重写就是把用户输入的SQL语句转换为更高效的等价SQL,查询重写遵循两个基本原则。
(1) 等价性:原语句和重写后的语句,输出结果相同。
(2) 高效性:重写后的语句,比原语句在执行时间和资源使用上更高效。
查询重写主要是基于关系代数式的等价变换,关系代数的变换通常满足交换律、结合律、分配率、串接率等,如表2所示。
表2 关系代数等价变换
等价变换 | 内容 |
交换律 | A × B == B × A A ⨝B == B ⨝ A A ⨝F B == B ⨝F A ……其中F是连接条件 Π p(σF (B)) == σF (Π p(B)) ……其中F∈p |
结合律 | (A × B) × C==A × (B × C) (A ⨝ B) ⨝ C==A ⨝ (B ⨝ C) (A ⨝F1 B) ⨝F2 C==A ⨝F1 (B ⨝F2 C) …… F1和F2是连接条件 |
分配律 | σF(A × B) == σF(A) × B …… 其中F ∈ A σF(A × B) == σF1(A) × σF2(B) …… 其中F = F1 ∪ F2,F1∈A, F2 ∈B σF(A × B) == σFX (σF1(A) × σF2(B)) …… 其中F = F1∪F2∪FX,F1∈A, F2 ∈B Π p,q(A × B) == Π p(A) × Π q(B) …… 其中p∈A,q∈B σF(A × B) == σF1(A) × σF2(B) …… 其中F = F1 ∪ F2,F1∈A, F2 ∈B σF(A × B) == σFx (σF1(A) × σF2(B)) …… 其中F = F1∪F2∪Fx,F1∈A, F2 ∈B |
串接律 | Π P=p1,p2,…pn(Π Q=q1,q2,…qn(A)) == Π P=p1,p2,…pn(A)……其中P ⊆ Q σF1(σF2(A)) == σF1∧F2(A) |
查询重写优化既可以基于关系代数的理论进行优化,例如谓词下推、子查询优化等,也可以基于启发式规则进行优化,例如Outer Join消除、表连接消除等。另外还有一些基于特定的优化规则和实际执行过程相关的优化,例如在并行扫描的基础上,可以考虑对Aggregation算子分阶段进行,通过将Aggregation划分成不同的阶段,可以提升执行的效率。
从另一个角度来看,查询重写是基于优化规则的等价变换,属于逻辑优化,也可以称为基于规则的优化,那么怎么衡量对一个SQL语句进行查询重写之后,它的性能一定是提升的呢?这时基于代价对查询重写进行评估就非常重要了,因此查询重写不只是基于经验的查询重写,还可以是基于代价的查询重写。
以谓词传递闭包和谓词下推为例,谓词的下推能够极大的降低上层算子的计算量,从而达到优化的效果,如果谓词条件有存在等值操作,那么还可以借助等值操作的特性来实现等价推理,从而获得新的选择条件。
例如,假设有两个表t1、t2分别包含[1,2,3,..100]共100行数据,那么查询语句SELECT t1.c1, t2.c1 FROM t1 JOIN t2 ON t1.c1=t2.c1 WHERE t1.c1=1则可以通过选择下推和等价推理进行优化,如图1所示。
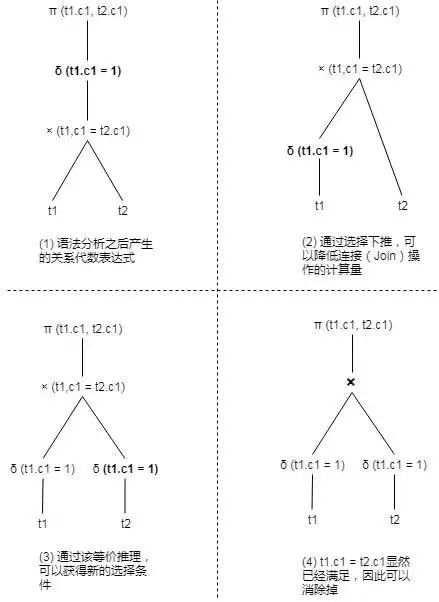
图1 查询重写前后对比图
如图1(1)所示,t1、t2表都需要全表扫描100行数据,然后再做join,生成100行数据的中间结果,最后再做选择操作,最终结果只有1行数据。如果利用等价推理,可以得到{t1.c1, t2.c1, 1}的是互相等价的,从而推导出新的t2.c1=1的选择条件,并把这个条件下推到t2上,从而得到图1(4)重写之后的逻辑计划。可以看到,重写之后的逻辑计划,只需要从基表上面获取1条数据即可,join时内、外表的数据也只有1条,同时省去了在最终结果上的过滤条件,性能大幅提升。
在代码层面,查询重写的架构大致如图2所示。
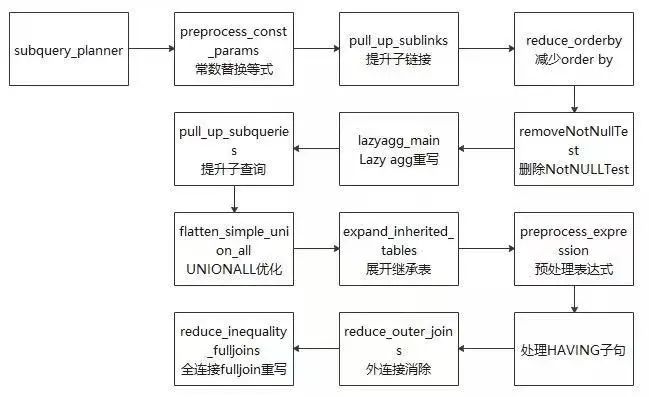
图2 查询重写的架构
(1) 提升子查询:子查询出现在RangeTableEntry中,它存储的是一个子查询树,若子查询不被提升,则经过查询优化之后形成一个子执行计划,上层执行计划和子查询计划做嵌套循环得到最终结果。在该过程中,查询优化模块对这个子查询所能做的优化选择较少。若该子查询被提升,转换成与上层的join,由查询优化模块常数替换等式:由于常数引用速度更快,故将可以求值的变量求出来,并用求得的常数替换它,实现函数为preprocess_const_params。
(2) 子查询替换CTE:理论上CTE(common table expression,通用表达式)与子查询性能相同,但对子查询可以进行进一步的提升重写优化,故尝试用子查询替换CTE,实现函数为substitute_ctes_with_subqueries。
(3) multi count(distinct)替换为多条子查询:如果出现该类查询,则将多个count(distinct)查询分别替换为多条子查询,其中每条子查询中包含一个count(distinct)表达式,实现函数为convert_multi_count_distinct。
(4) 提升子链接:子链接出现在WHERE/ON等约束条件中,通常伴随着ANY/ALL/IN/EXISTS/SOME等谓词同时出现。虽然子链接从语句的逻辑层次上是清晰的,但是效率有高有低,比如相关子链接,其执行结果和父查询相关,即父查询的每一条元组都对应着子链接的重新求值,此情况下可通过提升子链接提高效率。在该部分数据库主要针对ANY和EXISTS两种类型的子链接尝试进行提升,提升为Semi Join或者Anti-SemiJoin,实现函数为pull_up_sublinks。
(5) 减少ORDER BY:由于在父查询中可能需要对数据库的记录进行重新排序,故减少子查询中的ORDER BY语句以进行链接可提高效率,实现函数为reduce_orderby。
(6) 删除NotNullTest:即删除相关的非NULL Test以提高效率,实现函数为removeNotNullTest。
(7) Lazy Agg重写:顾名思义,即“懒聚集”,目的在于减少聚集次数,实现函数为lazyagg_main。
(8) 对连接操作的优化做了很多工作,可能获得更好的执行计划,实现函数为pull_up_subqueries。
(9) UNION ALL优化:对顶层的UNION ALL进行处理,目的是将UNION ALL这种集合操作的形式转换为AppendRelInfo的形式,实现函数为flatten_simple_union_all。
(10) 展开继承表:如果在查询语句执行的过程中使用了继承表,那么继承表是以父表的形式存在的,需要将父表展开成为多个继承表,实现函数为expand_inherited_tables。,实现函数为expand_inherited_tables。
(11)预处理表达式:该模块是对查询树中的表达式进行规范整理的过程,包括对链接产生的别名Var进行替换、对常量表达式求值、对约束条件进行拉平、为子链接生成执行计划等,实现函数为preprocess_expression。
(12) 处理HAVING子句:在Having子句中,有些约束条件是可以转变为过滤条件的(对应WHERE),这里对Having子句中的约束条件进行拆分,以提高效率。
(13) 外连接消除:目的在于将外连接转换为内连接,以简化查询优化过程,实现函数为reduce_outer_join函数。
(14) 全连接full join重写:对全连接函数进行重写,以完善其功能。比如对于语句SELECT * FROM t1 FULL JOIN t2 ON TRUE可以将其转换为:SELECT * FROM t1 LEFT JOIN t2 ON TRUE UNION ALL (SELECT * FROM t1 RIGHT ANTI FULL JOIN t2 ON TRUE),实现函数为reduce_inequality_fulljoins。
下面以子链接提升为例,介绍openGauss中一种最重要的子查询优化。所谓子链接(SubLink)是子查询的一种特殊情况,由于子链接出现在WHERE/ON等约束条件中,因此经常伴随ANY/EXISTS/ALL/IN/SOME等谓词出现,openGauss数据库为不同的谓词设置了不同的SUBLINK类型。代码如下:
Typedef enum SubLinkType {EXISTS_SUBLINK,ALL_SUBLINK,ANY_SUBLINK,ROWCOMPARE_SUBLINK,EXPR_SUBLINK,ARRAY_SUBLINK,CTE_SUBLINK} SubLinkType;
openGauss数据库为子链接定义了单独的结构体——SubLink结构体,其中主要描述了子链接的类型、子链接的操作符等信息。代码如下:
Typedef struct SubLink {Expr xpr;SubLinkType subLinkType;Node* testexpr;List* operName;Node* subselect;Int location;} SubLink;
子链接提升相关接口函数如图3所示。
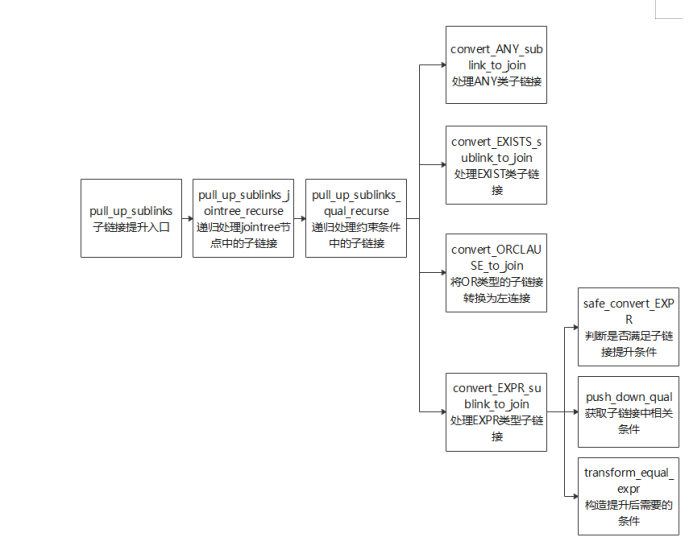
图3 子链接相关接口函数
子链接提升的主要过程是在pull_up_sublinks函数中实现,pull_up_sublinks函数又调用pull_up_sublinks_jointree_recurse递归处理Query->jointree中的节点,函数输入参数如表3所示。
表3 函数输入参数说明
参数名 | 参数类型 | 说明 |
root | PlannerInfo* | 输入参数,查询优化模块的上下文信息 |
jnode | Node* | 输入参数,需要递归处理的节点,可能是RangeTblRef、FromExpr或JoinExpr |
relids | Relids* | 输出参数,jnode参数中涉及的表的集合 |
返回值 | Node* | 经过子链接提升处理之后的node节点 |
jnode分为三种类型:RangeTblRef、FromExpr、JoinExpr。针对这三种类型pull_up_sublinks_jointree_recurse函数分别进行了处理。
1) RangeTblRef
RangeTblRef是Query->jointree的叶子节点,所以是该函数递归结束的条件,程序走到该分支,一般有两种情况。
(1) 当前语句是单表查询而且不存在连接操作,这种情况递归处理直到结束后,再去查看子链接是否满足其他提升条件。
(2) 查询语句存在连接关系,在对From->fromlist、JoinExpr->larg或者JoinExpr->rarg递归处理的过程中,当遍历到了RangeTblRef叶子节点时,需要把RangeTblRef节点的relids(表的集合)返回给上一层。主要用于判断该子链接是否能提升。
2) FromExpr
(1) 递归遍历From->fromlist中的节点,之后对每个节点递归调用pull_up_sublinks_jointree_recurse函数,直到处理到叶子节点RangeTblRef才结束。
(2) 调用pull_up_sublinks_qual_recurse函数处理From->qual,对其中可能出现的ANY_SUBLINK或EXISTS_SUBLINK进行处理。
3) JoinExpr
1) 调用pull_up_sublinks_jointree_recurse函数递归处理JoinExpr->larg和JoinExpr->rarg,直到处理到叶子节点RangeTblRef才结束。另外还需要根据连接操作的类型区分子链接是否能够被提升。
(2) 调用pull_up_sublinks_qual_recurse函数处理JoinExpr->quals,对其中可能出现的ANY_SUBLINK或EXISTS_SUBLINK做处理。如果连接类型不同,pull_up_sublinks_qual_recurse函数的available_rels1参数的输入值是不同的。
pull_up_sublinks_qual_recurse函数除了对ANY_SUBLINK和EXISTS_SUBLINK做处理,还对OR子句和EXPR类型子链接做了查询重写优化。其中Expr类型的子链接提升代码逻辑如下。
(1) 通过safe_convert_EXPR函数判断sublink是否可以提升。代码如下:
//判断当前SQL语句是否满足sublink提升条件if (subQuery->cteList ||subQuery->hasWindowFuncs ||subQuery->hasModifyingCTE ||subQuery->havingQual ||subQuery->groupingSets ||subQuery->groupClause ||subQuery->limitOffset ||subQuery->rowMarks ||subQuery->distinctClause ||subQuery->windowClause) {ereport(DEBUG2,(errmodule(MOD_OPT_REWRITE),(errmsg("[Expr sublink pull up failure reason]: Subquery includes cte, windowFun, havingQual, group, ""limitoffset, distinct or rowMark."))));return false;}
(2) 通过push_down_qual函数提取子链接中相关条件。代码如下:
Static Node* push_down_qual(PlannerInfo* root, Node* all_quals, List* pullUpEqualExpr){If (all_quals== NULL) {Return NULL;}List* pullUpExprList = (List*)copyObject(pullUpEqualExpr);Node* all_quals_list = (Node*)copyObject(all_quals);set_varno_attno(root->parse, (Node*)pullUpExprList, true);set_varno_attno(root->parse, (Node*)all_quals_list, false);Relids varnos = pull_varnos((Node*)pullUpExprList, 1);push_qual_context qual_list;SubLink* any_sublink = NULL;Node* push_quals = NULL;Int attnum = 0;While ((attnum = bms_first_member(varnos)) >= 0) {RangeTblEntry* r_table = (RangeTblEntry*)rt_fetch(attnum, root->parse->rtable);//这张表必须是基表,否则不能处理If (r_table->rtekind == RTE_RELATION) {qual_list.varno = attnum;qual_list.qual_list = NIL;//获得包含特殊varno的条件get_varnode_qual(all_quals_list, &qual_list);If (qual_list.qual_list != NIL && !contain_volatile_functions((Node*)qual_list.qual_list)) {any_sublink = build_any_sublink(root, qual_list.qual_list, attnum,pullUpExprList);push_quals = make_and_qual(push_quals, (Node*)any_sublink);}list_free_ext(qual_list.qual_list);}}list_free_deep(pullUpExprList);pfree_ext(all_quals_list);return push_quals;}
(3) 通过transform_equal_expr函数构造需要提升的SubQuery(增加GROUP BY子句,删除相关条件)。代码如下:
//为SubQuery增加GROUP BY和windowClasuesif (isLimit) {append_target_and_windowClause(root,subQuery,(Node*)copyObject(node), false);} else {append_target_and_group(root, subQuery, (Node*)copyObject(node));}//删除相关条件subQuery->jointree = (FromExpr*)replace_node_clause((Node*)subQuery->jointree,(Node*)pullUpEqualExpr,(Node*)constList,RNC_RECURSE_AGGREF | RNC_COPY_NON_LEAF_NODES);
(4) 构造需要提升的条件。代码如下:
//构造需要提升的条件joinQual = make_and_qual((Node*)joinQual, (Node*)pullUpExpr);…Return joinQual;
(5) 生成join表达式。代码如下:
//生成join表达式if (IsA(*currJoinLink, JoinExpr)) {((JoinExpr*)*currJoinLink)->quals = replace_node_clause(((JoinExpr*)*currJoinLink)->quals,tmpExprQual,makeBoolConst(true, false),RNC_RECURSE_AGGREF | RNC_COPY_NON_LEAF_NODES);} else if (IsA(*currJoinLink, FromExpr)) {((FromExpr*)*currJoinLink)->quals = replace_node_clause(((FromExpr*)*currJoinLink)->quals,tmpExprQual,makeBoolConst(true, false),RNC_RECURSE_AGGREF | RNC_COPY_NON_LEAF_NODES);}rtr = (RangeTblRef *) makeNode(RangeTblRef);rtr->rtindex = list_length(root->parse->rtable);// 构造左连接的JoinExprJoinExpr *result = NULL;result = (JoinExpr *) makeNode(JoinExpr);result->jointype = JOIN_LEFT;result->quals = joinQual;result->larg = *currJoinLink;result->rarg = (Node *) rtr;// 在rangetableentry中添加JoinExpr。在后续处理中,左外连接可转换为内连接rte = addRangeTableEntryForJoin(NULL,NIL,result->jointype,NIL,result->alias,true);root->parse->rtable = lappend(root->parse->rtable, rte);
(二)统计信息和代价估算
在不同数据分布下,相同查询计划的执行效率可能显著不同。因此,在选择计划时还应充分考虑数据分布对计划的影响。与通用逻辑优化不同,物理优化将计划的优化建立在数据之上,并通过最小化数据操作代价来提升性能。从功能上来看,openGauss的物理优化主要有以下3个关键步骤。
(1) 数据分布生成——从数据表中挖掘数据分布并存储。
(2) 计划代价评估——基于数据分布,建立代价模型评估计划的实际执行时间。
(3) 最优计划选择——基于代价估计,从候选计划中搜寻代价最小的计划。
首选,介绍数据分布的相关概念及其数据库内部的存储方式。
1. 数据分布的存储
数据集合D的分布由D上不同取值的频次构成。设D为表4在Grade列上的投影数据,该列有3个不同取值Grade = 1, 2, 3,其频次分布见表5。这里,将Grade取值的个数简称为NDV(Number of Distinct Values,不同值的数量)。
表4 Grade属性分布
Sno | Name | Gender | Grade |
001 | 小张 | 男 | 1 |
002 | 小李 | 男 | 2 |
003 | 小王 | 男 | 3 |
004 | 小周 | 女 | 1 |
005 | 小陈 | 女 | 1 |
表5 Grade频次分布
Grade | 1 | 2 | 3 |
频次 | 3 | 1 | 1 |
D可以涉及多个属性,将多个属性的分布称为联合分布。联合分布的取值空间可能十分庞大,从性能的角度考虑,数据库不会保存D的联合分布,而是将D中的属性分布分开保存,比如,数据库保存{ Gender=’男’}、{ Grade=’1’}的频次,而并不保存{ Gender=’男’, Grade=’1’}的频次。这种做法损失了D上分布的很多信息。在随后的选择率与数据分布小节的内容将看到,在系统需要的时候,openGauss将采取预测技术对联合分布进行推测。虽然在某些情况下,这种推测的结果可能与实际出入较大。
数据分布的数据结构对于理解数据库如何存储该信息尤为关键。一般来说,KV(key-value)键值对是描述分布最常用的结构,其中key表示取值,value表示频次。但在NDV很大的情况下,key值的膨胀使得KV的存储与读取性能都不高。为提高效率,openGauss实际采用“KV向量+直方图”的混合方式表示属性分布。
数据分布的逻辑结构:高频值频次采用KV存储,存储结构被称为最常见值;除高频值以外的频次采用等高直方图(equal-bin-count histogram,EH)描述。实现中,openGauss会将频次最高的k( k=100 )个key值放入MCV,其余放入直方图表示。
值得注意的是,等高直方图会将多个值的频次合并存放,在显著提升存取效率的同时,也会使得分布模糊化。但在后续章节可以看到,相对于低频值,高频值对计划代价的估算更为关键。因此,采取这种以损失低频值准确性为代价,换取高性能的混合策略,无疑是一种相当划算的做法。
数据分布的存放位置:在openGauss中,MCV、直方图等信息实际是放在系统表PG_STATISTIC中的,表定义如表6所示。
表6 系统表PG_STATISTIC定义
starelid | staattnum | stanullfrac | stakind1 | stanumbers1 | stavalues1 | Stakind2 | …… |
0001 | 1 | 0 | 1 | {0.2851, 0.1345} | {1, 2} | 2 | |
0001 | 2 | 0 | 1 | {0.1955, 0.1741} | {数学, 语文} | 2 |
表6中的一条元组存储了一条属性的统计信息。下分别对元组的属性意义进行解读。
(1) 属性starelid/staattnum表示的表OID和属性编号。
(2) 属性stanullfrac表示属性中为NULL的比例(为0表示该列没有NULL值)。
(3) 属性组{ stakind1, stanumbers1, stavalues1}构成PG_STATISTIC表的一个卡槽,存放表7中的一种数据结构类型的信息。在PG_STATISTIC表中有5个卡槽。一般情况下,第一个卡槽存储MCV信息,第二个卡槽存储直方图信息。以MCV卡槽为例:属性“stakind1”标识卡槽类型为MCV,其中“1”为“STATISTIC_KIND_MCV”的枚举值;属性stanumbers1与属性stavalues1记录MCV的具体内容,其中stavalues1记录key值,stanumbers1记录key对应的频次。上例中取值“1”的频次比例为0.2851,“2”的频次比例为0.1345。
表7 系统表PG_STATISTIC说明
类型 | 说明 |
STATISTIC_KIND_MCV | 高频值(常见值),在一个列里出现最频繁的值,按照出现的频率进行排序,并且生成一个一一对应的频率数组,这样就能知道一个列中有哪些高频值,这些高频值的频率是多少 |
STATISTIC_KIND_HISTOGRAM | 直方图,openGauss数据库用等频直方图来描述一个列中数据的分布,高频值不会出现在直方图中,这就保证了数据的分布是相对平坦的 |
STATISTIC_KIND_CORRELATION | 相关系数,相关系数记录的是当前列未排序的数据分布和排序后的数据分布的相关性,这个值通常在索引扫描时用来估计代价,假设一个列未排序和排序之后的相关性是0,也就是完全不相关,那么索引扫描的代价就会高一些 |
STATISTIC_KIND_MCELEM | 类型高频值(常见值),用于数组类型或者一些其他类型,openGauss数据库提供了ts_typanalyze系统函数来负责生成这种类型的统计信息 |
STATISTIC_KIND_DECHIST | 数组类型直方图,用于给数组类型生成直方图,openGauss数据库提供了array_typanalyze系统函数来负责生成这种类型的统计信息 |
注意,数据分布和PG_STATISTIC表中的内容不是在创建表的时候自动生成的,其生成的触发条件是用户对表进行了analyze操作。
2. 数据分布抽取方法
数据分布的存储给出了数据分布在openGauss的逻辑结构和存储方式。那么上面介绍的数据分布信息是如何从数据中获得呢?针对该问题,下面将简要介绍openGauss抽取分布的主要过程。为加深对方法的理解,先分析该问题面临的挑战。
获取分布最直接的办法是遍历所有数据,并通过计数直接生成MCV和直方图信息。但现实中的数据可能是海量的,遍历的I/O代价往往不可接受。比如,银行的账单数据涉及上千亿条记录,需要TB级的存储。除I/O代价外,计数过程的内存消耗也可能超过上限,这也使得算法实现变得尤为困难。因此,更现实的做法是降低数据分析的规模,采用小样本分析估算整体数据分布。那么,样本选择的好坏就显得尤为重要。
目前,openGauss数据库的样本生成过程在acquire_sample_rows函数实现,它采用了两阶段采样的算法对数据分布进行估算。第一阶段使用S算法对物理页进行随机采样,生成样本S1;第二阶段使用Z(Vitter)算法对S1包含的元组进行蓄水池采样,最终生成一个包含3000元组的样本S2。两阶段算法可以保证S2是原数据的一个无偏样本。因此,可以通过分析S2推断原数据分布,并将分布信息记录在PG_STATISTIC表的对应元组中。
openGauss将样本的生成划分成两个步骤,主要是为了提高采样效率。该方法的理论依据依赖于以下现实条件:数据所占据的物理页数量M可以准确获得,而每个物理页包含的元组数n未知。由于M已知,S算法可以用1/M的概率对页进行均匀抽样,可以生成原数据的小样本S1。一般认为,某元组属于任一物理页是等概率事件,这就保证了S1是一个无偏样本;而由于S1包含的元组远少于原数据,在S1的基础上进行二次抽样代价将大大减少。第二阶段没有继续使用S算法的主要原因是:S1的元组总数N未知(因为n未知),该算法无法获得采样概率——1/N。而Z(Vitter)的算法是一种蓄水池抽样算法,这类算法可以在数据总量未知条件下保证采样的均匀。蓄水池抽样算法原理不是本书的重点,读者可以自行查阅资料。
3. 选择率与数据分布
SQL查询常常带有where约束(过滤条件),比如:Select * from student where gender = ‘male’;Select * from student where grade > ‘1’。那么,约束对于查询结果的实际影响是什么呢?为度量约束的效能,首先引入选择率的概念。
选择率:给定查询数据集C(C可为数据表或任何中间结果集合)和约束表达式x,x相对C的选择率定义为
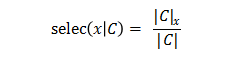
其中,|C|表示C的总记录数,|C|x表示C上满足x约束的记录数。如表8所示,在x为“grade = 1”时,selec(x|C)=3/5。
表8 数据集C选择率结果
Sno | Name | Gender | Grade |
001 | 小张 | 男 | 1 |
002 | 小李 | 男 | 2 |
003 | 小王 | 男 | 3 |
004 | 小周 | 女 | 1 |
005 | 小陈 | 女 | 1 |
记C的数据分布为π。从定义可知,selec(x|C)其实是对π按照语义x的一种描述。从这里可看到数据分布的关键用处:数据分布可以辅助选择率的计算、而使得计算过程不必遍历原数据。在代价估算部分中,将看到选择率对计划代价估算的巨大作用。
根据该思路,介绍openGauss计算选择率的基本过程。注意,由于简单约束下的选择率计算具有代表性,本部分将主要围绕着该进行问题进行讲解。简单约束的定义为:仅涉及基表单个属性的非范围约束。
涉及非简单约束选择率的计算方法,读者可以参照本文自行阅读源码。
1) 简单约束的选择率计算
假设x为简单约束,且x所涉及的属性分布信息已存在于PG_STATISTIC表元组r中(参见数据分布的存储部分内容)。openGauss通过调用clause_selectivity函数将元组r按x要求转换为选择率。
clause_selectivity的第二个参数clause为约束语句x。面对不同SQL查询,输入clause_selectivity的clause可能有多种类型,典型类型如表9所示。
表9 简单约束类型
简单约束类型 | 实例 |
Var | SELECT * FROM PRODUCT WHERE ISSOLD; |
Const | SELECT * FROM PRODUCT WHERE TRUE; |
Param | SELECT * FROM PRODUCT WHERE $1; |
OpExpr | SELECT * FROM PRODUCT WHERE PRIZE = ‘100’; |
AND | SELECT * FROM PRODUCT WHERE PRIZE = ‘100’ AND TYPE = ‘HAT’; |
OR | SELECT * FROM PRODUCT WHERE PRIZE = ‘100’ OR TYPE = ‘HAT’; |
NOT | SELECT * FROM PRODUCT WHERE NOT EXIST TYPE = ‘HAT’; |
其他 |
{Var, Const, Param, OpExpr}属于基础约束类型,而包含{AND, OR, NOT}的约束都是建立约束基础上的集合运算,称为SET约束类型。进一步观察可以发现,约束{Var, Const, Param}可以看作OpExpr约束的一个特例。比如:“SELECT * FROM PRODUCT WHERE ISSOLD”与“SELECT * FROM PRODUCT WHERE ISSOLD = TRUE”等价。限于篇幅,这里将着重介绍基于OpExpr类型的选择率计算,并简要给出SET类型计算的关键逻辑。
(1) OpExpr类型选择率。
以查询语句SELECT * FROM PRODUCT WHERE PRIZE = ‘100’为例。clause_selectivity函数首先根据clause(PRIZE = ‘100’)类型找到OpExpr分支。然后调用treat_as_join_clause函数判断clause是否是一个join约束;结果为假,说明clause是过滤条件(OP),则调用restriction_selectivity函数对clause参数进行选择率估算。
代码如下:
Selectivityclause_selectivity(PlannerInfo *root,Node *clause,int varRelid,JoinType jointype,SpecialJoinInfo *sjinfo){Selectivity s1 = 0.5;/* default for any unhandled clause type */RestrictInfo *rinfo = NULL;if (clause == NULL) /* can this still happen? */return s1;if (IsA(clause, Var))...else if (IsA(clause, Const))...else if (IsA(clause, Param))// not子句处理分支else if (not_clause(clause)){/* inverse of the selectivity of the underlying clause */s1 = 1.0 - clause_selectivity(root,(Node *) get_notclausearg((Expr *) clause),varRelid,jointype,sjinfo);}// and子句处理分支else if (and_clause(clause)){/* share code with clauselist_selectivity() */s1 = clauselist_selectivity(root,((BoolExpr *) clause)->args,varRelid,jointype,sjinfo);}// or子句处理分支else if (or_clause(clause)){ListCell *arg;s1 = 0.0;foreach(arg, ((BoolExpr *) clause)->args){Selectivity s2 = clause_selectivity(root,(Node *) lfirst(arg),varRelid,jointype,sjinfo);s1 = s1 + s2 - s1 * s2;}}join或op子句处理分支else if (is_opclause(clause) || IsA(clause, DistinctExpr)){OpExpr *opclause = (OpExpr *) clause;Oidopno = opclause->opno;// join子句处理if (treat_as_join_clause(clause, rinfo, varRelid, sjinfo)){/* Estimate selectivity for a join clause. */s1 = join_selectivity(root, opno,opclause->args,opclause->inputcollid,jointype,sjinfo);}op子句处理else{/* Estimate selectivity for a restriction clause. */s1 = restriction_selectivity(root, opno,opclause->args,opclause->inputcollid,varRelid);}}... ...return s1;}
restriction_selectivity函数识别出PRIZE = ‘100’是形如Var = Const的等值约束,它将通过eqsel函数间接调用var_eq_const函数进行选择率估算。在该过程中,var_eq_const函数会读取PG_STATISTIC表中PRIZE列分布信息,并尝试利用信息中MCV计算选择率。首选调用get_attstatsslot函数判断‘100’是否存在于MCV中,有以下几种情况。
l 情况1:存在,直接从MCV中返回‘100’的占比作为选择率。
l 情况2:不存在,则计算高频值的总比例sumcommon,并返回(1.0 – sumcommon – nullfrac) otherdistinct作为选择率。其中,nullfrac是NULL的比例,otherdistinct是低频值的NDV。
加入查询的约束是PRIZE < ‘100’,restriction_selectivity函数,该约束将根据操作符类型调用scalargtsel函数并尝试利用PG_STATISTIC表中信息计算选择率。由于满足< ‘100’的值可能分别存在于MCV和直方图中,所以需要分别在两种结构中收集满足条件的值。相比于MCV来说,在直方图中收集满足条件值的过程较为复杂,因此下面重点介绍:借助于直方图key的有序性,openGauss采用二分查找快速搜寻满足条件的值,并对其总占比进行求和并记作selec_histogram。注意,等高直方图不会单独记录‘100’的频次,而是将‘100’和相邻值合并放入桶(记作B桶)中,并仅记录B中数值的总频次(Fb)。为解决该问题,openGauss假设桶中元素频次相等,并采用公式

估算B中满足条件值的占比。该过程的具体代码实现在ineq_histogram_selectivity函数中。最终,restriction_selectivity函数返回的选择率值为selec =selec_mcv + selec_histogram,其中,selec_mcv是MCV中满足条件的占比。
(2) SET类型选择率。
对于SET类型约束,clause_selectivity函数递归计算其包含的基本约束选择率。然后根据SET类型的语义,通过表10所列方式返回最终选择率。
表10 SET类型选择率说明
SET类型 | 说明 |
NOT运算符 | selec(B) = 1 –selec(A) {B = NOT A} |
AND运算符 | {A AND B} |
OR运算符 | {A OR B} |
回顾数据分布的存储部分的内容,openGauss并没有保存多属性联合分布。而从表6-15可以看出,openGauss是在不同列取值相互独立的假设下对联合分布进行推算的。在列不独立的场景下,这种预测常常存在偏差。例如:对于学生表来说,性别和专业存在相关性。因此,不能通过男同学占比×计算机系人数去推测该系的人数。但在一般情况下,使用独立的假设往往也能获得较准确的结果。
(3) 选择率默认参数。
在数据分布未知的情况下,不能通过常规方法对选择率进行估算。例如:未对数据表进行analyze操作,或者过滤条件本身就是一个不确定的参数。为给优化器一个合理的参考值,openGauss给出了一系列选择率的经验参数,如表11所示。
表11 选择率参数说明
变量名 | 值 | 说明 |
DEFAULT_EQ_SEL | 0.005 | 为等值约束条件的默认选择率,例如A = b |
DEFAULT_INEQ_SEL | 0.3333333333333333 | 为不等值约束条件的默认选择率,例如A < b |
DEFAULT_RANGE_INEQ_SEL | 0.005 | 为涉及同一个属性(列)的范围约束条件的默认选额率,例如A > b AND A < c |
DEFAULT_MATCH_SEL | 0.005 | 为基于模式匹配的约束条件的默认选择率,例如LIKE |
DEFAULT_NUM_DISTINCT | 200 | 为对一个属性消重(distinct)之后的值域中有多少个元素,通常和DEFAULT_EQ_SEL互为倒数 |
DEFAULT_UNK_SEL | 0.005 | 为对BoolTest或NullText这种约束条件的默认选择率,例如IS TRUE或IS NULL |
DEFAULT_NOT_UNK_SEL | (1.0 - DEFAULT_UNK_SEL) | 为对BoolTest或NullText这种约束条件的默认选择率,例如IS NOT TRUE或IS NOT NULL |
4. 代价估算
查询执行的代价分为I/O代价和CPU代价。这两种代价都与查询过程中所处理的元组数量正相关。因此,通过选择率对查询计划的总代价进行评估是较为准确的。但由于硬件环境的差别,openGauss的代价模型输出的“代价”只是一种度量计划好坏的通用指标,而不是指执行时间。为描述度量的过程,下面将从代价模型参数的介绍为切入点,逐一展开I/O和CPU的代价评估方法。
(1) I/O代价评估
在磁盘上,元组是按数据页的方式进行组织的。页的存取方式主要有:顺序读和随机读。受制于存储介质的性能,顺序读的效率明显高于随机读。比如:机械硬盘面临大量随机访问时,磁头寻道的时间占据了数据读取的大部分时间。在openGauss中,不同存取方式I/O代价如下所示:
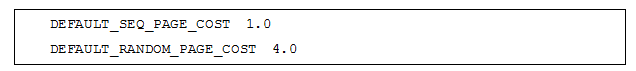
默认参数将数据页“顺序读”和“随机读”的开销设置为了1:4。
设置对于机械磁盘来说是比较合理的。但对于寻址能力出众的SSD盘来说,该参数就需要根据具体情况进行调整了。此外,现实中的数据库部署十分复杂,一个系统中可能同时存在多种不同的存储介质。为使得代价模型能同时应对不同存储介质的I/O性能,openGauss给用户提供了设定文件I/O单位代价的方法。

根据I/O代价参数和选择率,可以很容易对候选计划的I/O开销进行评估。下面将以顺序扫描(SeqScan)和索引扫描(IndexScan)为例,讲解代价评估的具体过程。
① SeqScan:对表的数据进行从头至尾的遍历,属于顺序读。因此,SeqScan的IO代价为:表数据页总数×DEFAULT_SEQ_PAGE_COST。
② IndexScan:通过索引查找满足约束的表数据,属于随机读。因此,IndexScan的I/O代价为:P * DEFAULT_RANDOM_PAGE_COST。
其中,P(满足数据页数量)与R(满足约束的元组数量)正相关,且R = 表元组总量×选择率;openGauss计算出R后,将调用index_pages_fetched(R, ...)函数估算P。该函数在costsize.c文件中实现,具体细节请参考Mackert L F和Lohman G M的论文Index scans using a finite LRU buffer: A validated I/O model。
通过观察代价模型可以发现当选择率超过一定阈值时,P会相对较大,而使得IndexScan的代价超过SeqScan。因此说明,IndexScan的效率并不总高于SeqScan。
(2) CPU代价评估。
数据库在数据寻址和数据加工阶段都需要消耗CPU资源,比如:元组投影选择、索引查找等。显然,针对不同的操作,CPU花费的代价都是不相同的。openGauss将CPU代价细分为:元组处理代价和数据操作代价。
① 元组处理代价:将一条磁盘数据转换成元组形式的代价;针对普通表数据和索引数据,代价参数分别如下:
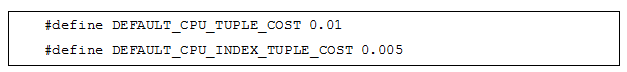
② 数据操作代价:对元组进行投影,或根据约束表达式判断元组是否满足条件的代价。代价参数如下:
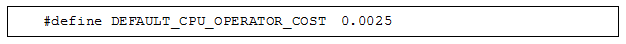
给定以上参数,CPU的代价估算与问题的计算规模成正比,而问题的计算规模取决于选择率。这种关系类似于算法例复杂度与n的关系。限于篇幅,本节不做具体介绍。
(三) 物理路径
在数据库中,路径使用path结构体来表示,path结构体“派生”自Node结构体,path结构体同时也是一个“基”结构体,类似于C++中的基类,每个具体路径都从path结构体中“派生”,例如索引扫描路径使用的IndexPath结构体就是从path结构体中“派生”的。
typedef struct Path{NodeTag type;NodeTag pathtype; /* 路径的类型,可以是T_IndexPath、T_NestPath等 */RelOptInfo *parent; /* 当前路径执行后产生的中间结果 */PathTarget *pathtarget; /* 路径的投影,也会保存表达式代价*/* 需要注意表达式索引的情况*/ParamPathInfo *param_info; /* 执行期使用参数,在执行器中,子查询或者一些特殊*/* 类型的连接需要实时的获得另一个表的当前值 */Bool parallel_aware; * 并行参数,区分并行还是非并行 */bool parallel_safe; /* 并行参数,由set_rel_consider_parallel函数决定 */int parallel_workers; /* 并行参数,并行线程的数量 */double rows; /* 当前路径执行产生的中间结果估计有多少数据 */Cost startup_cost; /* 启动代价,从语句执行到获得第一条结果的代价 */Cost total_cost; /* 当前路径的整体执行代价 */List *pathkeys; * 当前路径产生的中间结果的排序键值,如果无序则为NULL */} Path;
(四) 动态规划
目前openGauss已经完成了基于规则的查询重写优化和逻辑分解优化,并且已经生成各个基表的物理路径。基表的物理路径仅仅是优化器规划中很小的一部分,现在openGauss将进入优化器优化的另一个重要的工作,即生成Join连接路径。openGauss采用的是自底向上的优化方式,对于多表连接路径主要采用的是动态规划和遗传算法两种方式。这里主要介绍动态规划的方式,但如果表数量有很多,就需要用遗传算法。遗传算法可以避免在表数量过多情况下带来的连接路径搜索空间膨胀的问题。对于一般场景采用动态规划的方式即可,这也是openGauss默认采用的优化方式。
经过逻辑分解优化后,语句中的表已经被拉平,即从原来的树状结构变成了扁平的数组结构。各个表之间的连接关系也被记录到了root目录下的SpecialJoinInfo结构体中,这些也是对连接做动态规划的基础。
1. 动态规划方法
首先动态规划方法适用于包含大量重复子问题的最优解问题,通过记忆每个子问题的最优解,使相同的子问题只求解一下,下次就可以重复利用上次子问题求解的记录即可,这就要求这些子问题的最优解能够构成整个问题的最优解,也就是说应该要具有最优子结构的性质。所以对于语句的连接优化来说,整个语句连接的最优解也就是某一块语句连接的最优解,在规划的过程中无法重复计算局部最优解,直接用上次计算的局部最优解即可。

图4 重复子问题的最优解
例如,图1中两个连接树中A×B的连接操作就属于重复子问题,因为无论是生成A×B×C×D还是A×B×C连接路径的时候都需要先生成A×B连接路径,对于多表连接生成的路径即很多层堆积的情况下可能有上百种连接的方法,这些连接树的重复子问题数量会比较多,因此连接树具有重复子问题,可以一次求解多次使用,也就是对于连接A×B只需要一次生成最优解即可。
多表连接动态规划算法代码主要是从make_rel_from_joinlist函数开始的,如图5所示。

图5 多表连接动态规划算法
1) make_rel_from_joinlist函数
动态规划的实现代码主入口是从make_rel_from_joinlist函数开始的,它的输入参数是deconstruct_jointree函数拉平之后的RangeTableRef链表,每个RangeTableRef代表一个表,然后就可以根据这个链表来查找基表的RelOptInfo结构体,用查找到的RelOptInfo去构建动态规划连接算法一层中的基表RelOptInfo,后续再继续在这第1层RelOotInfo进行“累积”。代码如下:
//遍历拉平之后的joinlist,这个链表是RangeTableRef的链表foreach(jl, joinlist){Node *jlnode = (Node *) lfirst(jl);RelOptInfo *thisrel;//多数情况下都是RangeTableRef链表,根据RangeTableRef链表中存放的下标值(rtindex)//查找对应的RelOptInfoif (IsA(jlnode, RangeTblRef)){int varno = ((RangeTblRef *) jlnode)->rtindex;thisrel = find_base_rel(root, varno);}//受到from_collapse_limit参数和join_collapse_limit参数的影响,也存在没有拉平的节点,这里递归调用make_rel_from_joinlist函数else if (IsA(jlnode, List))thisrel = make_rel_from_joinlist(root, (List *) jlnode);elseereport (……);//这里就生成了第一个初始链表,也就是基表的链表,这个链表是//动态规划方法的基础initial_rels = lappend(initial_rels, thisrel);
2) standard_join_search函数
动态规划方法在累积表的过程中,每一层都会增加一个表,当所有的表都增加完毕的时候,最后的连接树也就生成了。因此累积的层数也就是表的数量,如果存在N个表,那么在此就要堆积N次,具体每一层堆积的过程在函数join_search_one_level中进行介绍,那么这个函数中主要做的还是为累积连接进行准备工作,包括分配每一层RelOptInfo所占用的内存空间以及每累积一层RelOptInfo后保留部分信息等工作。
创建一个“连接的数组”,类似于[LIST1, LIST2, LIST3]的结构,其中数组中的链表就用来保存动态规划方法中一层所有的RelOptInfo,例如数组中的第一个链表存放的就是有关所有基表路径的链表。代码如下:
//分配“累积”过程中所有层的RelOptInfo链表root->join_rel_level = (List**)palloc0((levels_needed + 1) * sizeof(List*));//初始化第1层所有基表RelOptInforoot->join_rel_level[1] = initial_rels;
做好了初始化工作之后,就可以开始尝试构建每一层的RelOptInfo。代码如下:
for (lev = 2; lev <= levels_needed; lev++) {ListCell* lc = NULL;//在join_search_one_level函数中生成对应的lev层的所有RelOptInfojoin_search_one_level(root, lev);……}
3) join_search_one_level函数
join_search_one_level函数主要用于生成一层中的所有RelOptInfo,如图6所示。如果要生成第N层的RelOptInfo主要有三种方式:一是尝试生成左深树和右深树,二是尝试生成浓密树,三是尝试生成笛卡儿积的连接路径(俗称遍历尝试)。

图6 生成第N层的RelOptInfo方式
(1) 左深树和右深树。
左深树和右深树生成的原理是一样的,只是在make_join_rel函数中对候选出的待连接的两个RelOptInfo进行位置互换,也就是每个RelOptInfo都有一次作为内表或作为外表的机会,这样其实创造出更多种连接的可能有助于生成最优路径。
如图7所示两个待选的RelOptInfo要进行连接生成A×B×C,左深树也就是对A×B和C进行了一下位置互换,A×B作为内表形成了左深树,A×B作为外表形成了右深树。
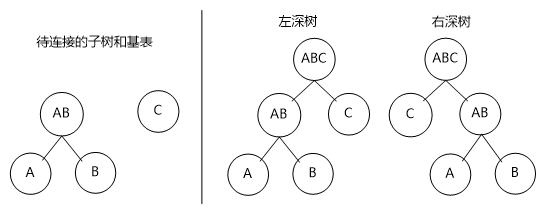
图7 左深树和右深树示意图
具体代码如下:
//对当前层的上一层进行遍历,也就是说如果要生成第4层的RelOptInfo//就要取第3层的RelOptInfo和第1层的基表尝试做连接foreach(r, joinrels[level - 1]){RelOptInfo *old_rel = (RelOptInfo *) lfirst(r);如果两个RelOptInfo之间有连接关系或者连接顺序的限制优先给这两个RelOptInfo生成连接has_join_restriction函数可能误判,不过后续还会有更精细的筛查if (old_rel->joininfo != NIL || old_rel->has_eclass_joins ||has_join_restriction(root, old_rel)){ListCell *other_rels;要生成第N层的RelOptInfo,就需要第N-1层的RelOptInfo和1层的基表集合进行连接即如果要生成第2层的RelOptInfo,那么就变成第1层的RelOptInfo和第1层的基表集合进行连接因此,需要在生成第2层基表集合的时候做一下处理,防止自己和自己连接的情况if (level == 2)other_rels = lnext(r);elseother_rels = list_head(joinrels[1]);//old_rel“可能”和其他表有连接约束条件或者连接顺序限制other_rels中就是那些“可能”的表,make_rels_clause_joins函数会进行精确的判断make_rels_by_clause_joins(root, old_rel, other_rels);}else{//对没有连接关系的表或连接顺序限制的表也需要尝试生成连接路径make_rels_by_clauseless_joins(root, old_rel, list_head(joinrels[1]));}}
(2) 浓密树。
要生成第N层的RelOptInfo,左深树或者右深树是将N-1层的RelOptInfo和第1层的基表进行连接,不论是左深树,还是右深树本质上都是通过引用基表RelOptInfo去构筑当前层RelOptInfo。而生成浓密树抛开了基表,它是将各个层次的RelOptInfo尝试进行随意连接,例如将第N-2层RelOptInfo和第2层的RelOptInfo进行连接,依次可以类推出(2,N﹣2)、(3,N﹣3)、(4, N﹣4)等多种情况。浓密树的建立要满足两个条件:一是两个RelOptInfo要存在相关的约束条件或者存在连接顺序的限制,二是两个RelOptInfo中不能存在有交集的表。
for (k = 2;; k++){int other_level = level - k;foreach(r, joinrels[k]){//有连接条件或者连接顺序的限制if (old_rel->joininfo == NIL && !old_rel->has_eclass_joins &&!has_join_restriction(root, old_rel))continue;……for_each_cell(r2, other_rels){RelOptInfo *new_rel = (RelOptInfo *) lfirst(r2);不能有交集if (!bms_overlap(old_rel->relids, new_rel->relids)){//有相关的连接条件或者有连接顺序的限制if (have_relevant_joinclause(root, old_rel, new_rel) ||have_join_order_restriction(root, old_rel, new_rel)){(void) make_join_rel(root, old_rel, new_rel);}}}}}
3) 笛卡儿积。
在尝试过左深树、右深树以及浓密树之后,如果还没有生成合法连接,那么就需要努力对第N﹣1层和第1层的RelOptInfo做最后的尝试,其实也就是将第N﹣1层中每一个RelOptInfo和第1层的RelOptInfo合法连接的尝试。
2. 路径生成
前面已经介绍了路径生成中使用的动态规划方法,并且介绍了在累积过程中如何生成当前层的RelOptInfo。对于生成当前层的RelOptInfo会面临几个问题:一是需要判断两个RelOptInfo是否可以进行连接,二是生成物理连接路径。目前物理连接路径主要有三种实现,分别是NestLoopJoin、HashJoin和MergeJoin,建立连接路径的过程就是不断地尝试生成这三种路径的过程。
1) 检查
在动态规划方法中需要将N-1层的每个RelOptInfo和第1层的每个RelOptInfo尝试做连接,然后将新连接的RelOptInfo保存在当前第N层,算法的时间复杂度在O(M×N)左右,如果发生第N-1层和第1层中RelOptInfo都比较多的情况下,搜索空间会膨胀得比较大。但有些RelOptInfo在做连接的时候是可以避免掉的,这也是我们需要及时检查的目的,提前检测出并且跳过两个RelOptInfo之间的链接,会节省不必要的开销,提升优化器生成优化的效率。
(1) 初步检查。
下面几个条件是初步检查主要进行衡量的因素。
l 一是RelOptinfo中joininfo不为NULL。那就说明这个RelOptInfo和其他的RelOptInfo存在相关的约束条件,换言之就是说当前这个RelOptInfo可能和其他表存在关联。
l 二是RelOptInfo中has_eclass_joins为true,表明在等价类的记录中当前RelOptInfo和其他RelOptInfo可能存在等值连接条件。
l 三是has_join_restriction函数的返回值为true,说明当前的RelOptInfo和其他的RelOptInfo有连接顺序的限制。
初步检查就是利用RelOptInfo的信息进行一种“可能性”的判断,主要是检测是否有连接条件和连接顺序的约束。
static bool has_join_restriction(PlannerInfo* root, RelOptInfo* rel){ListCell* l = NULL;//如果当前RelOptInfo涉及Lateral语义,那么就一定有连接顺序约束foreach(l, root->lateral_info_list){LateralJoinInfo *ljinfo = (LateralJoinInfo *) lfirst(l);if (bms_is_member(ljinfo->lateral_rhs, rel->relids) ||bms_overlap(ljinfo->lateral_lhs, rel->relids))return true;}//仅处理除内连接之外的条件foreach (l, root->join_info_list) {SpecialJoinInfo* sjinfo = (SpecialJoinInfo*)lfirst(l);//跳过全连接检查,会有其他机制保证其连接顺序if (sjinfo->jointype == JOIN_FULL)continue;如果这个SpecialJoinInfo已经被RelOptInfo包含就跳过if (bms_is_subset(sjinfo->min_lefthand, rel->relids) &&bms_is_subset(sjinfo->min_righthand, rel->relids))continue;//如果RelOptInfo结构体的relids变量和min_lefthand变量或min_righthand变量有交集,那么它就有可能有连接顺序的限制if (bms_overlap(sjinfo->min_lefthand, rel->relids) ||bms_overlap(sjinfo->min_righthand, rel->relids))return true;}return false;}
(1) 精确检查。
在进行了初步检查之后,如果判断出两侧RelOptInfo不存在有连接条件或者连接顺序的限制,那么就进入make_rels_by_clauseless_joins函数中,将RelOptInfo中所有可能的路径和第1层RelOptInfo进行连接。如果当前RelOptInfo可能有连接条件或者连接顺序的限制,那么就会进入make_rel_by_clause_joins函数中,会逐步将当前的RelOptInfo和第1层其他RelOptInfo进一步检查以确定是否可以进行连接。
在have_join_order_restriction函数判断两个RelOptInfo是否具有连接顺序的限制,主要从两个方面判断是否具有连接顺序的限制:一是判断两个RelOptInfo之间是否具有Lateral语义的顺序的限制,二是判断SpecialJoinInfo中的min_lefthand和min_righthand是否对两个RelOptInfo具有连接顺序的限制。
对have_join_order_restriction部分源码分析如下:
bool have_join_order_restriction(PlannerInfo* root, RelOptInfo* rel1, RelOptInfo* rel2){bool result = false;ListCell* l = NULL;//如果有Lateral语义的依赖关系,则一定具有连接顺序的限制foreach(l, root->lateral_info_list){LateralJoinInfo *ljinfo = (LateralJoinInfo *) lfirst(l);if (bms_is_member(ljinfo->lateral_rhs, rel2->relids) &&bms_overlap(ljinfo->lateral_lhs, rel1->relids))return true;if (bms_is_member(ljinfo->lateral_rhs, rel1->relids) &&bms_overlap(ljinfo->lateral_lhs, rel2->relids))return true;}//遍历root目录中所有SpecialJoinInfo,判断两个RelOptInfo是否具有连接限制foreach (l, root->join_info_list) {SpecialJoinInfo* sjinfo = (SpecialJoinInfo*)lfirst(l);if (sjinfo->jointype == JOIN_FULL)continue;//"最小集"分别是两个表的子集,两个表需要符合连接顺序if (bms_is_subset(sjinfo->min_lefthand, rel1->relids) &&bms_is_subset(sjinfo->min_righthand, rel2->relids)) {result = true;break;}//反过来同上,"最小集"分别是两个表的子集,两个表需要符合连接顺序if (bms_is_subset(sjinfo->min_lefthand, rel2->relids) &&bms_is_subset(sjinfo->min_righthand, rel1->relids)) {result = true;break;}//如果两个表都和最小集的一端有交集,那么这两个表应该在这一端下做连接//故让他们先做连接if (bms_overlap(sjinfo->min_righthand, rel1->relids) && bms_overlap(sjinfo->min_righthand, rel2->relids)) {result = true;break;}//反过来同上if (bms_overlap(sjinfo->min_lefthand, rel1->relids) && bms_overlap(sjinfo->min_lefthand, rel2->relids)) {result = true;break;}}//如果两个表上和其他表有相对应的连接关系//那么可以让他们先和具有连接关系的表进行连接if (result) {if (has_legal_joinclause(root, rel1) || has_legal_joinclause(root, rel2))result = false;}return result;}
(2) 合法连接。
由于RelOptInfo会导致搜索空间膨胀,如果上来就对两个RelOptInfo进行最终的合法连接检查会导致搜索时间过长,这也就是为什么要提前做初步检查和精确检查的原因,可以减少搜索时间其实达到了“剪枝”的效果。
对于合法连接,主要代码在join_is_legal中,它主要就是判断两个RelOptInfo可不可以进行连接生成物理路径,入参就是两个RelOpInfo。对于两个待选的RelptInfo,仍不清楚他们之间的逻辑连接关系,有可能是Inner Join、LeftJoin、SemiJoin,或者压根不存在合法的逻辑连接关系,故这时候就需要确定他们的连接关系,主要分成两个步骤。
步骤1:对root中join_info_list链表中的SpecialJoinInfo进行遍历,看是否可以找到一个“合法”的SpecialJoinInfo,因为除InnerJoin外的其他逻辑连接关系都会生成对应的一个SpecialJoinInfo,并在SpecialJoinInfo中还记录了合法的链接顺序。
步骤2:对RelOptInfo中的Lateral关系进行排查,查看找到的SpecialJoinInfo是否符合Lateral语义指定的连接顺序要求。
2) 建立连接路径
至此已经筛选出两个满足条件的RelOptInfo,那么下一步就是要对他们中的路径建立物理连接关系。通常的物理连接路径有NestLoop、Merge Join和Hash Join三种,这里主要是借由sort_inner_and_outer、match_unsorted_outer和hash_inner_and_outer函数实现的。
像sort_inner_and_outer函数主要是生成MergeJoin路径,其特点是假设内表和外表的路径都是无序的,所以必须要对其进行显示排序,内外表只要选择总代价最低的路径即可。而matvh_unsorted_outer函数则是代表外表已经有序,这时候只需要对内表进行显示排序就可以生成MergeJoin路径或者生成NestLoop以及参数化路径。最后的选择就是对两表连接建立HashJoin路径,也就是要建立哈希表。
为了方便MergeJoin的建立,首先需要对约束条件进行处理,故把适用于MergeJoin的约束条件从中筛选出来(select_mergejoin_clauses函数),这样在sort_inner_and_outer和match_unsorted_outer函数中都可以利用这个Mergejoinable连接条件。代码如下:
//提取可以进行Merge Join的条件foreach (l, restrictlist) {RestrictInfo* restrictinfo = (RestrictInfo*)lfirst(l);//如果当前是外连接并且是一个过滤条件,那么就忽略if (isouterjoin && restrictinfo->is_pushed_down)continue;//对连接条件是否可以做Merge Join进行一个初步的判断//restrictinfo->can_join和restrictinfo->mergeopfamilies都是在distribute_qual_to_rels生成if (!restrictinfo->can_join || restrictinfo->mergeopfamilies == NIL) {//忽略FULL JOIN ON FALSE情况if (!restrictinfo->clause || !IsA(restrictinfo->clause, Const))have_nonmergeable_joinclause = true;continue; /* not mergejoinable */}//检查约束条件是否是outer op inner或者inner op outer的形式if (!clause_sides_match_join(restrictinfo, outerrel, innerrel)) {have_nonmergeable_joinclause = true;continue; /* no good for these input relations */}//更新并使用最终的等价类//"规范化"pathkeys,这样约束条件就能和pathkeys进行匹配update_mergeclause_eclasses(root, restrictinfo);if (EC_MUST_BE_REDUNDANT(restrictinfo->left_ec) || EC_MUST_BE_REDUNDANT(restrictinfo->right_ec)) {have_nonmergeable_joinclause = true;continue; /* can't handle redundant eclasses */}result_list = lappend(result_list, restrictinfo);}
(1) sort_inner_and_outer函数。
sort_inner_and_outer函数主要用于生成MergeJoin路径,它需要显式地对两个字RelOptInfo进行排序,只考虑子RelOptInfo中的cheapest_total_path函数即可。通过MergeJoinable(能够用来生成Merge Join的)的连接条件来生成pathkeys,然后不断地调整pathkeys中pathke的顺序来获得不同的pathkeys集合,再根据不同顺序的pathkeys来决定内表的innerkeys和外表的outerkeys。代码如下:
//对外表和内表中的每一条路径进行连接尝试遍历foreach (lc1, outerrel->cheapest_total_path) {Path* outer_path_orig = (Path*)lfirst(lc1);Path* outer_path = NULL;j = 0;foreach (lc2, innerrel->cheapest_total_path) {Path* inner_path = (Path*)lfirst(lc2);outer_path = outer_path_orig;//参数化路径不可生成MergeJoin路径if (PATH_PARAM_BY_REL(outer_path, innerrel) ||PATH_PARAM_BY_REL(inner_path, outerrel))return;//必须满足外表和内表最低代价路径if (outer_path != linitial(outerrel->cheapest_total_path) &&inner_path != linitial(innerrel->cheapest_total_path)) {if (!join_used[(i - 1) * num_inner + j - 1]) {j++;continue;}}//生成唯一化路径jointype = save_jointype;if (jointype == JOIN_UNIQUE_OUTER) {outer_path = (Path*)create_unique_path(root, outerrel, outer_path, sjinfo);jointype = JOIN_INNER;} else if (jointype == JOIN_UNIQUE_INNER) {inner_path = (Path*)create_unique_path(root, innerrel, inner_path, sjinfo);jointype = JOIN_INNER;}//根据之前提取的条件确定可供MergeJoin路径生成的PathKeys集合all_pathkeys = select_outer_pathkeys_for_merge(root, mergeclause_list, joinrel);//处理上面pathkeys集合中每一个Pathkey尝试生成MergeJoin路径foreach (l, all_pathkeys) {……//生成内表的Pathkeyinnerkeys = make_inner_pathkeys_for_merge(root, cur_mergeclauses, outerkeys);//生成外表的Pathkeymerge_pathkeys = build_join_pathkeys(root, joinrel, jointype, outerkeys);//根据pathkey以及内外表路径生成MergeJoin路径try_mergejoin_path(root, ……,innerkeys);}j++;}i++;}
(2) match_unsorted_outer函数。
match_unsorted_outer函数大部分整体代码思路和sort_inner_and_outer一致,最主要的一点不同是sort_inner_and_outer是根据条件去推断出内外表的pathkey。而在match_unsorted_outer函数中,是假定外表路径是有序的,它是按照外表的pathkeys反过来排序连接条件的,也就是外表的pathkeys直接就可以作为outerkeys使用,查看连接条件中哪些是和当前的pathkeys匹配的并把匹配的连接条件筛选出来,最后再参照匹配出来的连接条件生成需要显示排序的innerkeys。
(3) hash_inner_and_outer函数。
顾名思义,hash_inner_and_outer函数的主要作用就是建立HashJoin的路径,在distribute_restrictinfo_to_rels函数中已经判断过一个约束条件是否适用于Hashjoin。因为Hashjoin要建立哈希表,至少有一个适用于Hashjoin的连接条件存在才能使用HashJoin,否则无法创建哈希表。
3) 路径筛选
至此为止已经生成了物理连接路径Hashjoin、NestLoop、MergeJoin,那么现在就是要根据他们生成过程中计算的代价去判断是否是一条值得保存的路径,因为在连接路径阶段会生成很多种路径,并会生成一些明显比较差的路径,这时候筛选可以帮助做一个基本的检查,能够节省生成计划的时间。因为如果生成计划的时间
太长,即便选出了“很好”的执行计划,那么也是不能够接受的。
add_path为路径筛选主要函数。代码如下:
switch (costcmp) {case COSTS_EQUAL:outercmp = bms_subset_compare(PATH_REQ_OUTER(new_path),PATH_REQ_OUTER(old_path));if (keyscmp == PATHKEYS_BETTER1) {if ((outercmp == BMS_EQUAL || outercmp == BMS_SUBSET1) &&new_path->rows <= old_path->rows)//新路径代价和老路径相似,PathKeys要长,需要的参数更少//结果集行数少,故接受新路径放弃旧路径remove_old = true; /* new dominates old */} else if (keyscmp == PATHKEYS_BETTER2) {if ((outercmp == BMS_EQUAL || outercmp == BMS_SUBSET2) &&new_path->rows >= old_path->rows)//新路径代价和老路径相似,pathkeys要短,需要的参数更多//结果集行数更多,不接受新路径保留旧路径accept_new = false; /* old dominates new */} else {if (outercmp == BMS_EQUAL) {//到这里,新旧路径的代价、pathkeys、路径参数均相同或者相似//如果新路径返回的行数少,选择接受新路径,放弃旧路径if (new_path->rows < old_path->rows)remove_old = true; /* new dominates old *///如果新路径返回行数多,选择不接受新路径,保留旧路径else if (new_path->rows > old_path->rows)accept_new = false; /* old dominates new *///到这里,代价、pathkeys、路径参数、结果集行数均相似//那么就严格规定代价判断的范围,如果新路径好,则采用新路径,放弃旧路径else {small_fuzzy_factor_is_used = true;if (compare_path_costs_fuzzily(new_path, old_path, SMALL_FUZZY_FACTOR) ==COSTS_BETTER1)remove_old = true; /* new dominates old */elseaccept_new = false; /* old equals or* dominates new */}//如果代价和pathkeys相似,则比较行数和参数,好则采用,否则放弃} else if (outercmp == BMS_SUBSET1 &&new_path->rows <= old_path->rows)remove_old = true; /* new dominates old */else if (outercmp == BMS_SUBSET2 &&new_path->rows >= old_path->rows)accept_new = false; /* old dominates new *//* else different parameterizations, keep both */}break;case COSTS_BETTER1://所有判断因为新路径均好于或者等于旧路径//则接受新路径,放弃旧路径if (keyscmp != PATHKEYS_BETTER2) {outercmp = bms_subset_compare(PATH_REQ_OUTER(new_path),PATH_REQ_OUTER(old_path));if ((outercmp == BMS_EQUAL || outercmp == BMS_SUBSET1) &&new_path->rows <= old_path->rows)remove_old = true; /* new dominates old */}break;case COSTS_BETTER2://所有判断因素旧路径均差于或者等于新路径//则不接受新路径,保留旧路径if (keyscmp != PATHKEYS_BETTER1) {outercmp = bms_subset_compare(PATH_REQ_OUTER(new_path),PATH_REQ_OUTER(old_path));if ((outercmp == BMS_EQUAL || outercmp == BMS_SUBSET2) &&new_path->rows >= old_path->rows)accept_new = false; /* old dominates new */}break;default:/** can't get here, but keep this case to keep compiler* quiet*/break;}
(五) 遗传算法
遗传算法(genetic algorithm,GA)作为进化算法的一种,借鉴了达尔文生物进化论中的自然选择以及遗传学机理。通过模拟大自然中“物竞天择,适者生存”这种进化过程来生成最优的个体。
当生成一定数量的原始个体后,可以通过基因的排列组合产生新的染色体,再通过染色体的杂交和变异获得下一代染色体。为了筛选出优秀的染色体,需要通过建立适应度函数计算出适应度的值,从而将适应度低的染色体淘汰。如此,通过个体间不断的遗传、突变,逐渐进化出最优秀的个体。将这个过程代入解决问题,个体即为问题的解。通过遗传算法,可以通过此类代际遗传来使得问题的解收敛于最优解。
区别于动态规划将问题分解成若干独立子问题求解的方法,遗传算法是一个选择的过程,它通过将染色体杂交构建新染色体的方法增大解空间,并在解空间中随时通过适应度函数进行筛选,推举良好基因,淘汰掉不良的基因。这就使得遗传算法获得的解不会像动态规划一样,一定是全局最优解,但可以通过改进杂交和变异的方式,来争取尽量的靠近全局最优解。
得益于在多表连接中的效率优势,在openGauss数据库中,遗传算法是动态规划方法的有益补充。只有在Enable_geqo参数打开,并且待连接的RelOptInfo的数量超过Geqo_threshold(默认12个)的情况下,才会使用遗传算法。
遗传算法的实现有下面5个步骤。
(1) 种群初始化:对基因进行编码,并通过对基因进行随机的排列组合,生成多个染色体,这些染色体构成一个新的种群。另外,在生成染色体的过程中同时计算染色体的适应度。
(2) 选择染色体:通过随机选择(实际上通过基于概率的随机数生成算法,这样能倾向于选择出优秀的染色体),选择出用于交叉和变异的染色体。
(3) 交叉操作:染色体进行交叉,产生新的染色体并加入种群。
(4) 变异操作:对染色体进行变异操作,产生新的染色体并加入种群。
(5) 适应度计算:对不良的染色体进行淘汰。
举个例子,如果用遗传算法解决货郎问题(TSP),则可以将城市作为基因,走遍各个城市的路径作为染色体,路径的总长度作为适应度,适应度函数负责筛选掉比较长的路径,保留较短的路径。算法的步骤如下。
(1) 种群初始化:对各个城市进行编号,将各个城市根据编号进行排列组合,生成多条新的路径(染色体),然后根据各城市间的距离计算整体路径长度(适应度),多条新路径构成一个种群。
(2) 选择染色体:选择两个路径进行交叉(需要注意交叉生成新染色体中不能重复出现同一个城市),对交叉操作产生的新路径计算路径长度。
(3) 变异操作:随机选择染色体进行变异(通常方法是交换城市在路径中的位置),对变异操作后的新路径计算路径长度。
(4) 适应度计算:对种群中所有路径进行基于路径长度由小到大排序,淘汰掉排名靠后的路径。
openGauss数据库的遗传算法正是模拟了解决货郎问题的方法,将RelOptInfo作为基因、最终生成的连接树作为染色体、连接树的总代价作为适应度,适应度函数则是基于路径的代价进行筛选,但是openGauss数据库的连接路径的搜索和货郎问题的路径搜索略有不同,货郎问题不存在路径不通的问题,两个城市之间是相通的,可以计算任何两个城市之间的距离,而数据库中由于连接条件的限制,可能两个表无法正常连接,或者整个连接树都无法生成。另外,需要注意的是,openGauss数据库的基因算法实现方式和通常的遗传算法略有不同,在于其没有变异的过程,只通过交叉产生新的染色体。
openGauss数据库遗传算法的总入口是geqo函数,输入参数为root(查询优化的上下文信息)、number_of_rels(要进行连接的RelOptInfo的数量)、initial_rels(所有的基表)。
1. 文件结构
遗传算法作为相对独立的优化器模块,拥有自己的一套文件目录结构,见表12。
表12 优化器文件目录结构说明
文件名称 | 功能说明 |
geqo_copy.cpp | 复制基因函数,即gepo_copy函数 |
geqo_cx.cpp | 循环交叉(CYCLE CROSSOVER)算法函数,即cx函数 |
geqo_erx.cpp | 基于边重组交叉(EGDE RECOMBINATION CROSSOVER)实现,提供调用gimme_edge_table函数 |
geqo_eval.cpp | 主要进行适应度计算,调用make_one_rel函数生成连接关系 |
geqo_main.cpp | 遗传算法入口,即主函数geqo函数 |
geqo_misc.cpp | 遗传算法信息打印函数,辅助功能 |
geqo_mutation.cpp | 基因变异函数,在循环交叉cx函数失败时调用,即geqo_mutation函数 |
geqo_ox1.cpp | 顺序交叉(ORDER CROSSOVER)算法方式一函数,即ox1函数 |
geqo_ox2.cpp | 顺序交叉(ORDER CROSSOVER)算法方式二函数,即ox2函数 |
geqo_pmx.cpp | 部分匹配交叉(PARTIALLY MATCHED CROSSOVER)算法函数,即pmx函数 |
geqo_pool.cpp | 处理遗传算法的基因池,基因池是表示所有个体(包括染色体和多表连接后得到的新的染色体)的集合 |
geqo_px.cpp | 位置交叉(POSITION CROSSOVER)算法函数,即px函数 |
geqo_random.cpp | 遗传算法的随机算法函数,用来随机生成变异内容 |
geqo_recombination.cpp | 遗传算法初始化群体函数,即init_tour函数 |
geqo_selection.cpp | 遗传算法随机选择个体函数,即geqo_selection函数 |
这些文件作为优化器遗传算法的各个模块都在src/gausskernel/optimizer/gepo下。接下来的几个单元会着重根据这些文件中的代码进行解读。
2. 种群初始化
在使用遗传算法前,可以利用参数Gepo_threshold的数值来调整触发的条件。为了方便代码解读,将这个边界条件降低至4(即RelOptInfo数量或者说基表数量为4的时候就尝试使用遗传算法)。下面在解读代码的过程中,以t1,t2,t3,t4四个表为例进行说明。
RelOptInfo作为遗传算法的基因,首先需要进行基因编码,openGauss数据库采用实数编码的方式,也就是用{1,2,3,4}分别代表t1,t2,t3,t4这4个表。
然后通过gimme_pool_size函数来获得种群的大小,种群的大小受Geqo_pool_size和Geqo_effort两个参数的影响,种群用Pool结构体进行表示,染色体用Chromosome结构体来表示。代码如下:
/* 染色体Chromosome结构体 */typedef struct Chromosome {/* string实际是一个整型数组,它代表基因的一种排序方式,也就对应一棵连接树 *//* 例如{1,2,3,4}对应的就是t1 JOIN t2 JOIN t3 JOIN t4 *//* 例如{2,3,1,4}对应的就是t2 JOIN t3 JOIN t1 JOIN t4 */Gene* string;Cost worth; /* 染色体的适应度,实际上就是路径代价 */} Chromosome;/* 种群Pool结构体 */typedef struct Pool {Chromosome *data; /* 染色体数组,数组中每个元组都是一个连接树 */int size; /* 染色体的数量,即data中连接树的数量,由gimme_pool_size生成 */int string_length; /* 每个染色体中的基因数量,和基表的数量相同 */} Pool;
另外通过gimme_number_generations函数来获取染色体交叉的次数,交叉的次数越多则产生的新染色体也就越多,也就更可能找到更好的解,但是交叉次数多也影响性能,用户可以通过Geqo_generations参数来调整交叉的次数。
在结构体中确定的变量如下。
(1) 通过gimme_pool_size确定的染色体的数量(Pool.size)。
(2) 每个染色体中基因的数量(Pool.string_length),和基表的数量相同。
然后就可以开始生成染色体,染色体的生成采用的是Fisher-Yates洗牌算法,最终生成Pool.size条染色体。具体的算法实现如下:
/* 初始化基因序列至{1,2,3,4} */for (i = 0; i < num_gene; i++)tmp[i] = (Gene)(i + 1);remainder = num_gene - 1; /* 定义剩余基因数 *//* 洗牌方法实现,多次随机挑选出基因,作为基因编码的一部分 */for (i = 0; i < num_gene; i++) {/* choose value between 0 and remainder inclusive */next = geqo_randint(root, remainder, 0);/* output that element of the tmp array */tour[i] = tmp[next]; /* 基因编码 *//* and delete it */tmp[next] = tmp[remainder]; /* 将剩余基因序列更新 */remainder--;}
表13是生成一条染色体的流程,假设4次的随机结果为{1,1,1,0}。
表13 生成染色体的流程
基因备选集 Tmp | 结果集 tour | 随机数 范围 | 随机数 | 说明 |
1 2 3 4 | 2 | 0~3 | 1 | 随机数为1,结果集的第一个基因为tmp[1],值为2,更新备选集tmp,将未被选中的末尾值放在前面被选中的位置上 |
1 4 3 | 2 4 | 0~2 | 1 | 随机数为1,结果集的第二个基因为4,再次更新备选集tmp |
1 3 | 2 4 3 | 0~1 | 1 | 随机数为1,结果集的第三个基因为3,由于末尾值被选,无须更新备选集 |
1 | 2 4 3 1 | 0~0 | 0 | 最后一个基因为1 |
在多次随机生成染色体后,得到一个种群,假设Pool种群中共有4条染色体,用图来描述其结构,如图8所示。

图8 染色体结构
然后对每条染色体计算适应度(worth),计算适应度的过程实际上就是根据染色体的基因编码顺序产生连接树,并对连接树求代价的过程。
在openGauss数据库中,每个染色体都默认使用的是左深树,因此每个染色体的基因编码确定后,它的连接树也就随之确定了,比如针对{2, 4, 3, 1}这样一条染色体,它对应的连接树就是(((t2,t4),t3), t1),如图9所示。
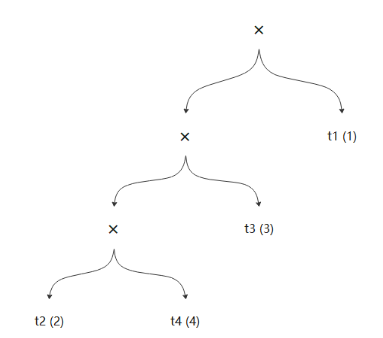
图9 染色体连接树
openGauss数据库通过geqo_eval函数来生成计算适应度,它首先根据染色体的基因编码生成一棵连接树,然后计算这棵连接树的代价。
遗传算法使用gimme_tree函数来生成连接树,函数内部递归调用了merge_clump函数。merge_clump函数将能够进行连接的表尽量连接并且生成连接子树,同时记录每个连接子树中节点的个数。再将连接子树按照节点个数从高到低的顺序记录到clumps链表。代码如下:
/* 循环遍历所有的表,尽量将能连接的表连接起来 */For (rel_count = 0; rel_count < num_gene; rel_count++) {int cur_rel_index;RelOptInfo* cur_rel = NULL;Clump* *cur_clump = NULL;/* tour 代表一条染色体,这里是获取染色体里的一个基因,也就是一个基表 */cur_rel_index = (int) tour[rel_count];cur_rel = (RelOptInfo *) list_nth(private->initial_rels, cur_rel_index - 1);/* 给这个基表生成一个Clump,size=1代表了当前Clump中只有一个基表*/cur_clump = (Clump*)palloc(sizeof(Clump));cur_clump->joinrel = cur_rel;cur_clump->size = 1;/* 开始尝试连接,递归操作,并负责记录Clump到clumps链表 */clumps = merge_clump(root, clumps, cur_clump, false);}
以之前生成的{2, 4, 3, 1}这样一条染色体为例,并假定。
(1) 2和4不能连接。
(2) 4和3能够连接。
(3) 2和1能够连接。
在这些条件下,连接树生成的过程见表14。
表14 连接树生成过程
轮数 relcount | 连接结果集 clumps | 说明 |
初始 | NULL | 创建基因为2的节点cur_clump,cur_clump.size = 1 |
0 | {2} | 因为clumps == NULL,cur_clump没有连接表,将cur_clump直接加入clumps |
1 | {2},{4} | 创建基因为4的节点cur_clump,cur_clump.size = 1,将基因为4的cur_clump和clumps链表的里的节点尝试连接,因为2和4不能连接,节点4也被加入clumps |
2 | {2} | 创建基因为3的节点cur_clump,cur_clump.size = 1,遍历clumps链表,分别尝试和2、4进行连接,发现和4能进行连接,创建基于3和4的连接的新old_clumps节点,ols_clumps.size = 2,在clumps链表中删除节点4 |
{3, 4} {2} | 用2和4连接生成的新的old_clumps作为参数递归调用merge_clump,用old_clumps和clumps链表里的节点再尝试连接,发现不能连接(即{3,4}和{2}不能连接),那么将old_clumps加入clumps,因为old_clumps.size目前最大,插入clumps最前面 | |
3 | {3, 4} | 创建基因为1的节点cur_clump,cur_clump.size = 1 遍历clumps链表,分别尝试和{3,4}、{2}进行连接,发现和2能进行连接,创建基于1和2的新old_clumps节点,ols_clumps.size = 2,在clumps链表中删除节点2 |
{3, 4} {1, 2} | 用1和2连接生成的新的old_clumps作为参数递归调用merge_clump,用old_clumps和clumps链表里的节点尝试连接,发现不能连接,将old_clumps加入clumps,因为old_clumps.size = 2,插入clumps最后 |
结合例子中的步骤,可以看出merge_clumps函数的流程就是不断的尝试生成更大的clump。
/* 如果能够生成连接,则通过递归尝试生成节点数更多的连接 */if (joinrel != NULL) {…………/* 生成新的连接节点,连接的节点数增加 */old_clump->size += new_clump->size;pfree_ext(new_clump);/* 把参与了连接的节点从clumps连表里删除 */clumps = list_delete_cell(clumps, lc, prev);/* 以clumps和新生成的连接节点(old_clump)为参数,继续尝试生成连接 */return merge_clump(root, clumps, old_clump, force);}
根据上方表中的示例,最终clumps链表中有两个节点,分别是两棵连接子树,然后将force设置成true后,再次尝试连接这两个节点。
/* clumps中有多个节点,证明连接树没有生成成功 */if (list_length(clumps) > 1) {……foreach(lc, clumps) {Clump* clump = (Clump*)lfirst(lc);/* 设置force参数为true,尝试无条件连接 */fclumps = merge_clump(root, fclumps, clump, true);}clumps = fclumps;
3. 选择算子
在种群生成之后,就可以进行代际遗传优化,从种群中随机选择两个染色做交叉操作,这样就能产生一个新的染色体。
由于种群中的染色体已经按照适应度排序了,对来说适应度越低(代价越低)的染色体越好,因为希望将更好的染色体遗传下去,所以需要在选择父染色体和母染色体的时候更倾向于选择适应度低的染色体。在选择过程中会涉及倾向(bias)的概念,它在算子中是一个固定的值。当然,bias的值可以通过参数Geqo_selection_bias进行调整(默认值为2.0)。

要生成基于某种概率分布的随机数(),需要首先知道概率分布函数或概率密度函数,openGauss数据库采用的概率密度函数(probability density function,PDF)fx(x)为:

把基于概率的随机数生成算法的代码提取出来单独进行计算验证,看一下它生成随机数的特点。设bias = 2.0,然后利用概率密度函数计算各个区间的理论概率值进行分析,比如对于0.6~0.7的区间,计算其理论概率如下

各个区间的理论概率值如图10所示。
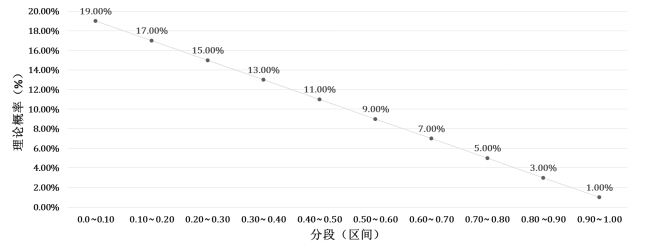
图10 随机数生成理论概率值
从图6-15可以看出各个区间的理论概率值的数值是依次下降的,也就是说在选择父母染色体的时候是更倾向于选择适应度更低(代价更低)的染色体。
4. 交叉算子
通过选择算子选择出父母染色体之后,则可以对选出的父母染色体进行交叉操作,生成新的子代染色体。
openGauss提供了多种交叉方法,包括有基于边的重组交叉方法(edge combination crossover)、部分匹配交叉方法(partially matched crossover)、循环交叉(cycle crossover)、位置交叉(position crossover)、顺序交叉(order crossover)等。在源代码分析的过程中,以位置交叉方法为例进行说明。
假如选择父染色体的基因编码为{1, 3, 2, 4},适应度为100,母染色体的基因编码为{2, 3, 1, 4},适应度为200,在子染色体还没有生成,处于未初始化状态时,这些染色体的状态如图11所示。
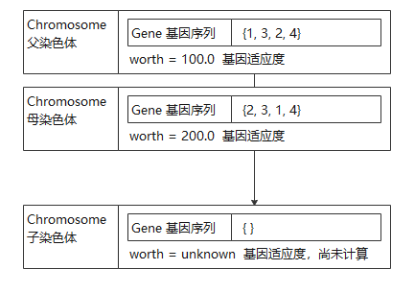
图11 染色体状态
交叉操作需要生成一个随机数num_positions,这个随机数的位置介于基因总数的1/3~2/3区间的位置,这个随机数代表了有多少父染色体的基因要按位置遗传给子染色体。具体代码如下:
/* num_positions决定了父染色体遗传多少基因给子染色体 */num_positions = geqo_randint(root, 2 * num_gene / 3, num_gene / 3);/* 选择随机位置*/for (i = 0; i < num_positions; i++){/* 随机生成位置,将父染色体这个位置的基因遗传给子染色体 */pos = geqo_randint(root, num_gene - 1, 0);offspring[pos] = tour1[pos];/* 标记这个基因已经使用,母染色体不能再遗传相同的基因给子染色体 */city_table[(int) tour1[pos]].used = 1;}
假设父染色体需要遗传2个基因给子染色体,分别传递第1号基因和第2号基因,那么子染色体目前的状态如图12所示。
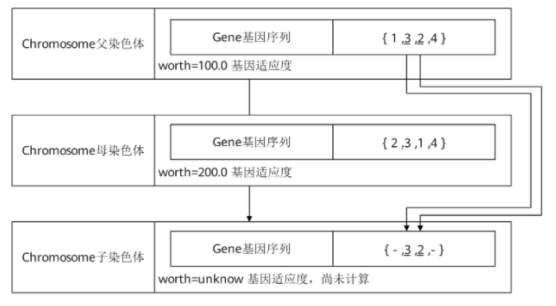
图12 当前染色体状态
目前子染色体已经有了3和2两个基因,则母染色体排除这两个基因后,还剩下1和4两个基因,将这两个基因按照母染色体中的顺序写入子染色体,新的子染色体就生成了,如图6-18所示。
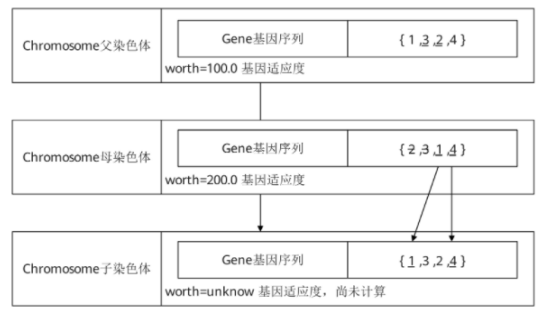
图13 新的染色体装状态
5. 适应度计算
当得到了新生成的子染色体后,需要通过geqo_eval函数来计算适应度,随后使用spread_chromo函数将染色体加入到种群中。
/* 适应度分析*/kid->worth = geqo_eval(root, kid->string, pool->string_length);/* 基于适应度将染色体扩散*/spread_chromo(root, kid, pool);
由于种群中的染色体始终应保持有序的状态,spread_chromo函数可以使用二分法遍历种群来比较种群中的染色体和新染色体的适应度大小并根据适应度大小来查找新染色体的插入位置,排在它后面的染色体自动退后一格,最后一个染色体被淘汰,如果新染色体的适应度最大,那么直接会被淘汰。具体代码如下:
/* 二分法遍历种群Pool中的染色体 */top = 0;mid = pool->size / 2;bot = pool->size - 1;index = -1;/* 染色体筛选 */while (index == -1) {/* 下面4种情况需要进行移动*/if (chromo->worth <= pool->data[top].worth) {index = top;} else if (chromo->worth - pool->data[mid].worth == 0) {index = mid;} else if (chromo->worth - pool->data[bot].worth == 0) {index = bot;} else if (bot - top <= 1) {index = bot;} else if (chromo->worth < pool->data[mid].worth) {/** 下面这两种情况单独处理,因为他们的新位置还没有被找到*/bot = mid;mid = top + ((bot - top) / 2);} else { /* (chromo->worth > pool->data[mid].worth) */top = mid;mid = top + ((bot - top) / 2);}}
遗传算法会通过选择优秀的染色体以及多次的代际交叉,不断地生成新种群的染色体,循环往复,推动算法的解从局部最优向全局最优逼近。
四、 小结
本文对SQL引擎的主要实现流程进行了介绍,包括SQL解析流程、查询重写、查询优化等。SQL引擎内容较多代码耦合度高,实现逻辑较为复杂,需要读者对代码整体流程以及关键结构体有所掌握,并在应用实践中不断总结才能做到更好的理解。
欢迎访问openGauss官方网站

openGauss开源社区官方网站:
https://opengauss.org
openGauss组织仓库:
https://gitee.com/opengauss
openGauss镜像仓库:
https://github.com/opengauss-mirror

扫码关注我们
微信公众号|openGauss
微信社群小助手|openGauss-bot
