




为什么要使用连接池?
PostgreSQL允许我们通过参数max_connections来控制最大连接数 ,但是如果为前端应用的每次请求都分配一个新的DB连接,那么DB服务端可能在链接风暴到来时需要一次性提供大量的连接插槽,这会严重消耗服务端的内存,并且会导致性能急剧下降。
在高并发请求的应用场景,为了保护DB,取而代之的我们可以利用连接池的连接复用特性,来避免DB被突然到来的连接洪峰淹没。这样,当应用程序一次性发送成千上万个查询的时候,如果超过了DB的处理能力,请求将在会连接池中排队,而不会导致后端PostgreSQL崩溃。
与突然分配大量DB连接相比,这种在连接池中配置固定数量的连接处理来接收请求,查询的性能要好得多。另外,客户端的连接非常轻巧,除了文件描述符外基本没有其他消耗。但我们服务端连接却很重,需要适当配置。用较少的服务器连接来支持大量的客户端连接,是我们在PostgreSQL使用pgouncer的主要用例。
能够缓存和PostgreSQL的连接,当有连接请求进来的时候,直接分配空闲进程,而不需要PostgreSQL fork出新进程来建立连接,以节省创建新进程,创建连接的资源消耗。 能够有效提高连接的利用率,避免过多的无效连接,导致数据库消耗资源过大,CPU占用过高。 对客户端连接进行限制,预防过多或恶意的连接请求。
PgBouncer的特点
C语言编写,效率高,内存消耗低(默认为2k/连接),因为Bouncer不需要每次都接受完整的数据包
可以把不同的数据库连接到一个机器上,而对客户端保持透明
支持在线的重新配置而无须重启
仅支持V3协议,因此后端版本须>=7.4
使用libevent进行socket通信,通信效率高。
PgBouncer的编译安装需要依赖下面相关包:
GNU Make 3.81+Libevent 2.0+(需要编译安装)pkg-configOpenSSL 1.0.1+ for TLS support(optional) c-ares as alternative to Libevent’s evdns(optional) PAM libraries
依赖包安装:
download libevent-2.1.11-stable.tar.gztar -xvf libevent-2.1.11-stable.tar.gzconfigure --prefix=/MySql/pg/libeventmake && make install"
环境变量配置:
vi .bash_profileexport LIBDIR=/MySql/pg/libevent/libexport LD_RUN_PATH=$LIBDIRexport PKG_CONFIG_PATH=$LIBDIR/pkgconfig
解决安装包之后,编译安装其实比较简单:
$ ./configure --prefix=/usr/local$ make$ make install
配置文件主要分2部分
[databases]
要连接的数据库名,默认跟 客户端相同的名字 。
[pgbouncer]
这个部分的配置项比较多,主要分为下面几类:
通用配置项
日志配置项
控制界面访问控制配置项
连接健康检查和超时配置项
危险的超时配置项
底层网络配置项
1. 创建一个pgbouncer.ini文件
简例:
[databases] postgres = --databaseshost=127.0.0.1 port=5432 dbname=template1 [pgbouncer] listen_port = 666 listen_addr = 127.0.0.1auth_type = md5 auth_file = home/postgres/pgbouncer/user.txtlogfile = home/postgres/pgbouncer/pgbouncer.logpidfile = home/postgres/pgbouncer/pgbouncer.pidadmin_users = someuserpool_mode = Transaction
2. 配置文件详解
[databases]部分配置
数据库连接字符串:database name = connect string连接字符串参数有:
dbname=(这种指定的的数据库名为真实的数据库名 与前面的 database name 应该与其一致,试过 bazdb = host=127.0.0.1 port=5432 dbname=sheen,结果在pgadmin 端进行连接时,可以连接到pgbouncer,也能看到 连接的服务器端数据库集群中所有的数据库,但是却不能连接,会报找不到指定数据库,连 数据库名是时sheen 的也不能连接,改为 sheen = ... dbname=sheen 才可连接到 sheen 这个数据库上)。
host= 要连接的数据库的主机IP
port= 要连接的数据库的监听端口(默认5432)
user= 如果指定了用户名,所有的连接到该设置的数据库连接都会以指定的用户名进行连接,那么也意味着所有的连接在连接该数据库时都只能共用一个连接池,如果没有设置,那么pgbouncer 在连接该数据库时,将会使用客户端的用户名。这种情况下是一个用户独自使用一个连接池
password=指定用户登录数据库的密码
client_encoding=指定客户端的编码格式
datestyle=指定日期格式
timezone=指定时区
pool_size=这个数据库连接每个连接池最大的连接数
connect_query=建立连接后执行的sql 查询,如果查询失败将会被记录在日志中,没有设置将会被忽略
sheen = host=127.0.0.1 port=5432 dbname=sheen
fsdb_paas = host=127.0.0.1 port=5432 dbname=postgres connect_query='SELECT 1'
wenzhong = host=127.0.0.1 port=5432 dbname=wenzhong connect_query='SELECT 1'
针对库 postgres 创建了一个连接池,该连接池对调用方的呈现的数据库名为 fsdb_paas,它映射到了 postgres库上,即所有访问 pgbouncer上的 fsdb_paas的请求都会转到 postgres库上完成。
pgbouncer 的相关设置:
logfile=/dir/of/logfile/pgbouncer.log 日志文件的存放位置pidfile=/dir/of/pidfile/pgbouncer.pid pid 文件的存放目录listen_addr = 指定监听的IP 如不做对指定客户端监听 使用 * 监听所有listen_port = pgbouncer 的监听端口使用unix 套接字的话,使用如下参数设置unix_socket_dir=unix_socket_mode=unix_socket_group=
授权设置
auth_type = trunst 授权方式 (any ,trust , plain , crypt , md5)auth_file = /etc/pgbouncer/userlist.txt 授权文件,到指定的文件中读取用户及密码,也只有文件中存在的用户才能登录 userlist.txt 的格式:"username" "password"auth_type 和 auth_file 是 pgbouncer用于完成对客户端身份认证的配置项, auth_file中保存用户名和密码,根据验证方式auth_type的不同,auth_file中的内容也不同。md5: 基于md5的密码验证,auth_file中需要有普通文本和md5值两种形式的密码;crypt: 基于crypt的密码验证(man 3 crypt), auth_file必须包含文本密码;plain: 明文验证方式;trust: 不进行验证,但auth_file依然需要保存用户名;any: 也不进行验证,而且auth_file中不需要保存用户名了。但此种方式需要在pg_template1中明确说明用户名进行真实数据库的登录。如: pg_template1?=?host=127.0.0.1 user=exampleuser dbname=template1.否则会报错的。注意:auth_file中的用户名、密码都必须使用双引号。
允许登录pgbouncer 的用户
admin_users= 管理用户名,随便设置一个名字,用于登录pgbouncer 数据库用,这里设置的用户具有更改设置的权限
stats_users = 只允许使用show 命令的用户名
连接池设置
pool_mode = (session ,transaction , statement 上面已经有说过3种连接方式)
server_reset_query = DISCARD ALL pg 8.3 后使用该参数,清空server_reset_query。当上一个查询连接释放后,确保可以给下一个客户端使用前连接中没有任何事物,也不能包含 ABORT 或者ROLLBACK
max_client_conn = 允许客户端的最大链接数。如果连接串中没有指定用户名的 max_client_conn + (max_pool_size * total_databases * total_users)如果连接串中指定了用户名的 max_client_conn + (max_pool_size * total_databases)
default_pool_size 链接池的大小(per user/database)
reserve_pool_size 当发生问题时,额外的链接数
reserve_pool_timeout 额外链接超时
log_pooler_errors 记录从连接池发送到客户端的错误信息
超时设置
server_lifetime 默认值 1200 秒 连接到服务器端超过这个时间自动关闭连接
server_idle_timeout = 60 空闲连接超过60秒关闭连接
server_connect_timeout = 15 连接超时,链接服务器超15秒没响应取消
server_login_retry = 15 登录服务器失败后重连的时间间隔 默认15秒
client_login_timeout=60
autodb_idle_timeout = 3600
危险的超时设置
query_timeout 默认0 关闭,当查询超过设置的时间关闭
query_wait_timeout默认0 关闭,当查询等待服务器端响应超过设置时间关闭
client_idle_timeout默认0 关闭,当客户端在设置实际内没有活动,连接关闭
底层参数调节
pkt_buf = 2048 流包缓冲区大小
listen_backlog =128 确定队列中保存多少新的未答复的连接尝试。当队列已满,进一步新的连接将被丢弃
网络层参数调节 tcp
tcp_defer_accept (linux 默认45 其他OS 为0)tcp_socket_buffer (linux 默认4096)tcp_keepalive (0/1)
下面的参数只有在linux 中可以设置,同样需要设置tcp_keepalive =1
tcp_keepcnt=tcp_keepidle=tcp_keepintvl=dns_max_ttldns_zone_check_period=
3. 简易版的pgbouncer 连接配置
[databases]sheen = host=127.0.0.1 port=5432 dbname=sheen[pgbouncer]logfile=/dir/of/logfile/pgbouncer.logpidfile=/dir/of/pidfile/pgbouncer.pidlisten_addr =*listen_port =6432auth_type = trustauth_file = etc/pgbouncer/userlist.txtadminuser=pgbouncer
配置pgbouncer.ini 的时候,在原来自带的那份 pgbouncer.ini 上面进行修改就好了,要启用哪个参数 前面的;去掉,设上相应的值即可
userlist.txt 生成方式
postgres=# copy (select usename,passwd from pg_shadow) to '/etc/pgbouncer/userlist.txt';或postgres=# \o etc/pgbouncer/userlist.txtpostgres=# select usename,passwd from pg_shadow;

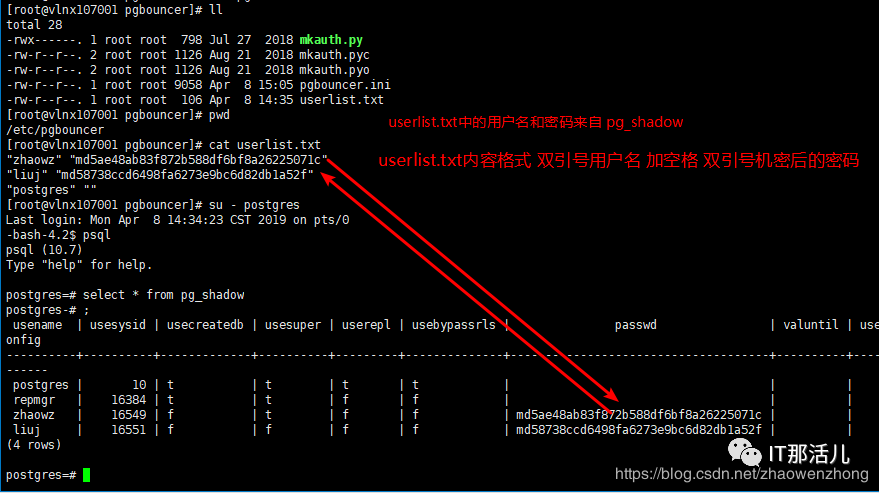
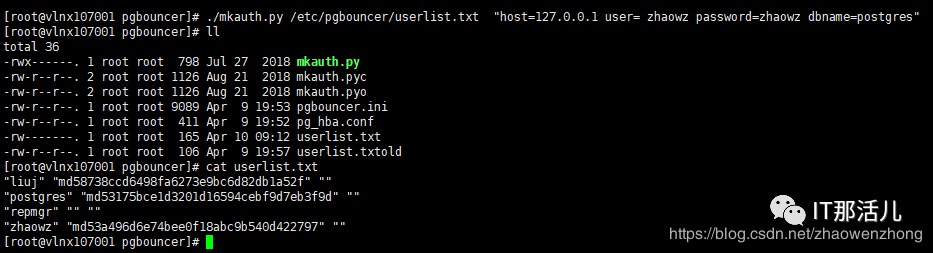
第二种方法:使用 pgbouncer 自带的工具 mkauth.py 工具导出用户名和密码;这种方法需要首先安装 psycopg2这个python模块,因为mkauth是利用该模块连接postgres数据库的。
mkauth脚本使用格式方法:./mkauth.py 密码文件名 连接参数
[root@vlnx107001 pgbouncer]# ./mkauth.py etc/pgbouncer/userlist.txt "host=127.0.0.1 user= zhaowz password=zhaowz dbname=postgres"
4. 重点参数介绍
pool_mode
有三种模式:session,transaction,statement
session :是默认的模式,每开启一个进程,DB端也会开启一个新的进程
transaction :是基于事务模式的
statement :是基于每个查询的,开启此模式不适合执行事务,会报错。
原文见安装后pgbouncer中的usage.txt,本次文件地址:/home/postgres/pgbouncer/share/doc/pgbouncer
Session pooling :: Most polite method. When client connects, a server connection will be assigned to it for the whole duration the client stays connected. When the client disconnects, the server connection will be put back into the pool. This is the default method. Transaction pooling :: A server connection is assigned to client only during a transaction. When PgBouncer notices that transaction is over, the server connection will be put back into the pool. Statement pooling :: Most aggressive method. The server connection will be put back into pool immediately after a query completes. Multi-statement transactions are disallowed in this mode as they would break. |
auth_type和auth_file
这两个是pgbouncer用以完成客户端身份认证参数。auth_file中保存用户名和密码,根据验证方式(auth_type)的不同,auth_file的内容也有不同。
md5: 基于md5的密码验证,auth_file中需要有普通文本和md5值两种形式的密码;
crypt: 基于crypt的密码验证(man 3 crypt), auth_file必须包含文本密码;
plain: 明文验证方式;
trust: 不进行验证,但auth_file依然需要保存用户名;
any: 也不进行验证,而且auth_file中不需要保存用户名了。但此种方式需要在pg_template1中明确说明用户名进行真实数据库的登录。如: pg_template1 = host=127.0.0.1 user=exampleuser dbname=template1.否则会报错的。
需要说明的是:auth_file中的用户名、密码都必须使用双引号,否则还是报错。
"postgres" "123456"
"postgres" "md5a3556571e93b0d20722ba62be61e8c2d"
postgres=# \o userlist.txtpostgres=# SELECT rolname,rolpassword from pg_authid where rolname = 'postgres';postgres=# \opostgres=# \q
5. 参数修改
如果修改了ini文件中相关参数,需要通过命令告知bouncer重新读取配置内容:
pgbouncer=# reload;

更多精彩干货分享
点击下方名片关注
IT那活儿

