




Tesseract OCR 安装及使用
一、工具介绍
Tesseract-OCR 是一款由HP实验室开发由Google维护的开源OCR(Optical Character Recognition , 光学字符识别)引擎。与Microsoft Office Document Imaging(MODI)相比,我们可以不断的训练的库,使图像转换文本的能力不断增强;如果团队深度需要,还可以以它为模板,开发出符合自身需求的OCR引擎。
语言包:https://github.com/tesseract-ocr/tessdata
直接下载地址:http://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-setup-4.00.00dev.exe
tesseract下载地址:https://digi.bib.uni-mannheim.de/tesseract/
二、配置环境变量
2.1 进入环境变量配置界面
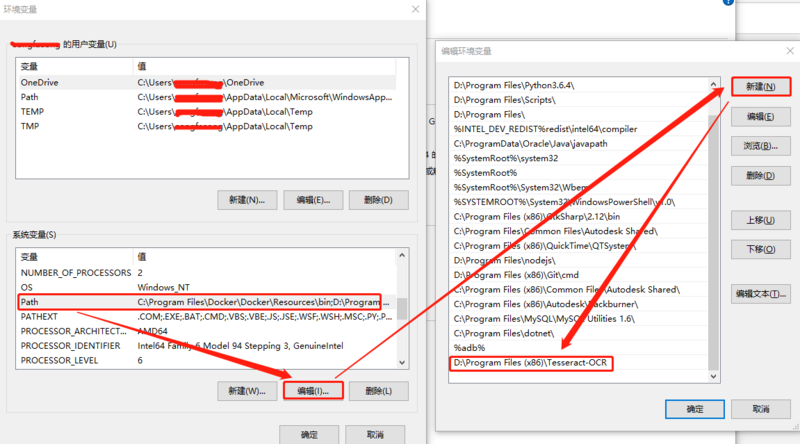
右键点击此电脑–属性–高级系统设置–环境变量–系统变量–Path
2.2 添加系统变量
找到系统变量的 Path ,将 Tesseract-OCR 的安装目录添加进去:
2.3 添加 tessdata 系统变量
如下图新建系统变量 :TESSDATA_PREFIX
变量值为 tessdata 文件夹的路径(在Tesseract-OCR的安装目录下):
三、使用 Tesseract-OCR
3.1 进入cmd 输入下面的命令查看版本,正常运行则安装成功:
tesseract --version

3.2 使用下面命令识别图片
tesseract 图片路径 输出文件

查看输出的 2.txt文件:
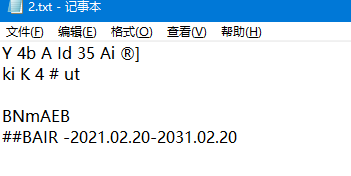

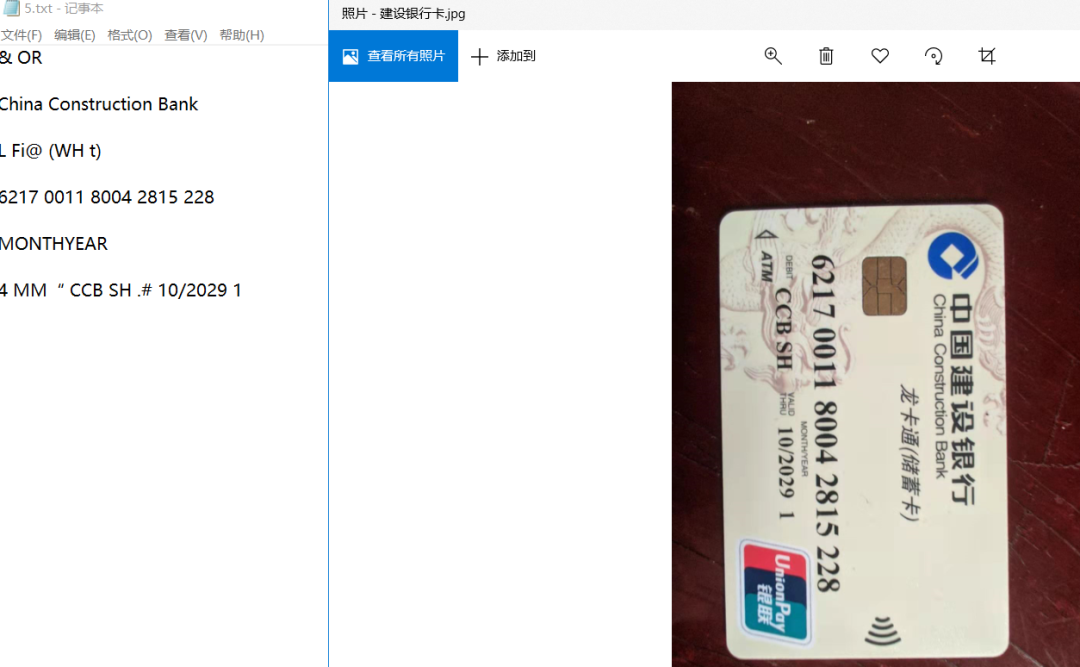
结果正确!
打开命令终端,输入:tesseract -v
,可以看到版本信息
用命令tesseract --list-langs
来查看Tesseract-OCR支持语言。

Tesseract OCR 语言包下载
esseract OCR语言包的下载地址
https://github.com/tesseract-ocr/tessdata

写的比较好的文章
Tesseract怎么识别中文_欧世乐-CSDN博客_tesseract 中文
Windows下的Tesseract的配置安装与使用_欧世乐-CSDN博客_windows安装tesseract
参考:1. https://blog.csdn.net/qq_37193537/article/details/81335165
2.https://blog.csdn.net/weixin_43656359/article/details/103401848
Tesseract-OCR识别中文与训练字库实例:
https://www.cnblogs.com/lcawen/articles/7040005.html

base64计算文件大小Topshelf
搭建 Windows 服务
C# 笛卡尔积 算法
.NET Core 下使用 Serilog 记录日志
C#中IOC容器-Autofac的使用
堆和栈(stack and heap)的基础知识
并发与并行的区别

