




下面这张图是一个社交网络场景,每个用户可以发微博、分享微博或评论他人的微博。这些都是最基本的增删改查,也是大多数研发人员对数据库做的常见操作。
而在研发人员的日常工作中除了要把用户的基本信息录入数据库外,还需找到与该用户相关联的信息,方便去对单个的用户进行下一步的分析,比如说:我们发现张三的账户里有很多关于 AI 和音乐的内容,那么我们可以据此推测出他可能是一名程序员,从而推送他可能感兴趣的内容。
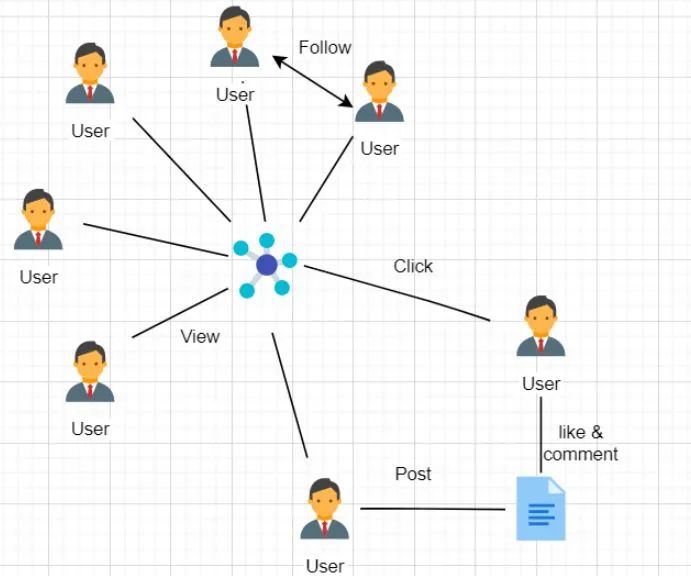
这些数据分析每时每刻都会发生,但有时候,一个简单的数据工作流在实现的时候可能会变得相当复杂,此外数据库性能也会随着数据量的增加而锐减。
比如说获取某管理者下属三级汇报关系的员工,这种统计查询在现在的数据分析中是一种常见的操作,而这种操作往往会因为数据库选型导致性能产生巨大差异。
1. 传统数据库的解决思路
传统解决上述问题最简单的方法就是建立一个关系模型,我们可以把每个员工的信息录入表中,存在诸如 MySQL 之类的关系数据库,下图是最基本的关系模型:
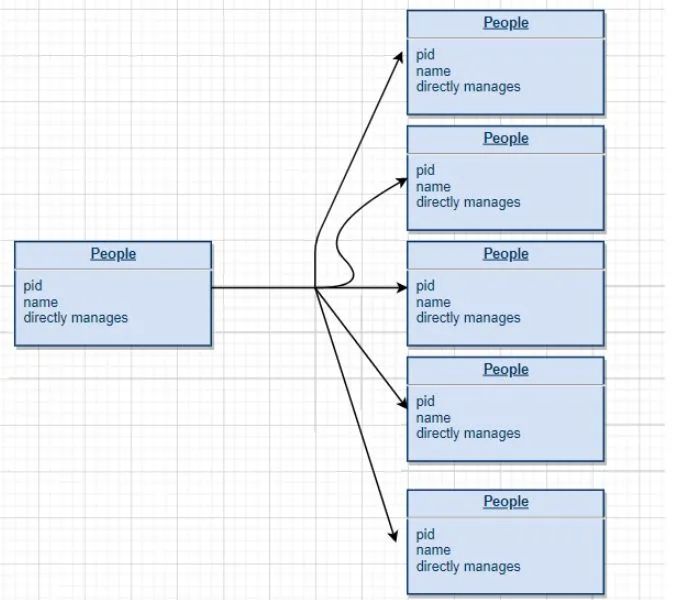
但是基于上述的关系模型,要实现我们的需求,就不可避免地涉及到很多关系数据库JOIN
操作,同时实现出来的查询语句也会变得相当长(有时达到上百行):

这样的代码,不仅可读性很差,而且一个人写完,别人想接手,那基本不可能,可维护性也很差。对维护人员和开发者来说就是一场灾难,没有人想写或者去调试这种代码。
同时,效率也很低。上万条的记录查询会在10秒左右。
在数据量这么大的场景中,使用传统 SQL 会产生很大的性能问题,原因主要有两个:
大量 JOIN 操作带来的开销:之前的查询语句使用了大量的 JOIN 操作来找到需要的结果。而大量的 JOIN 操作在数据量很大时会有巨大的性能损失,因为数据本身是被存放在指定的地方,查询本身只需要用到部分数据,但是 JOIN 操作本身会遍历整个数据库,这样就会导致查询效率低到让人无法接受。
反向查询带来的开销:查询单个经理的下属不需要多少开销,但是如果我们要去反向查询一个员工的老板,使用表结构,开销就会变得非常大。表结构设计得不合理,会对后续的分析、推荐系统产生性能上的影响。比如,当关系从_老板 -> 员工 _变成 用户 -> 产品,如果不支持反向查询,推荐系统的实时性就会大打折扣,进而带来经济损失。
上述关系型数据库建模失败的主要原因在于数据间缺乏内在的关联性,针对这类问题,更好的建模方式是使用图结构。假如数据本身就是表格的结构,关系数据库就可以解决问题,但如果你要展示的是数据与数据间的关系,关系数据库反而不能解决问题了,这主要是在查询的过程中不可避免的大量 JOIN 操作导致的,而每次 JOIN 操作却只用到部分数据,既然反复 JOIN 操作本身会导致大量的性能损失,如何建模才能更好的解决问题呢?答案在点和点之间的关系上。
2. 使用图结构建模
请务必改变思路:节点和关系先定义是图数据库和别的数据库的核心区别。
在我们之前的讨论中,传统数据库虽然运用 JOIN 操作把不同的表链接了起来,从而隐式地表达了数据之间的关系,但是当我们要通过 A 管理 B,B 管理 A 的方式查询结果时,表结构并不能直接告诉我们结果。
如果我们想在做查询前就知道对应的查询结果,我们必须先定义节点和关系。
打个比方,我们可以把经理、员工表示成不同的节点,并用一条边来代表他们之前存在的管理关系,或者把用户和商品看作节点,用购买关系建模等等。而当我们需要新的节点和关系时,只需进行几次更新就好,而不用去改变表的结构或者去迁移数据。
根据节点和关联关系,之前的数据可以根据下图所示建模:
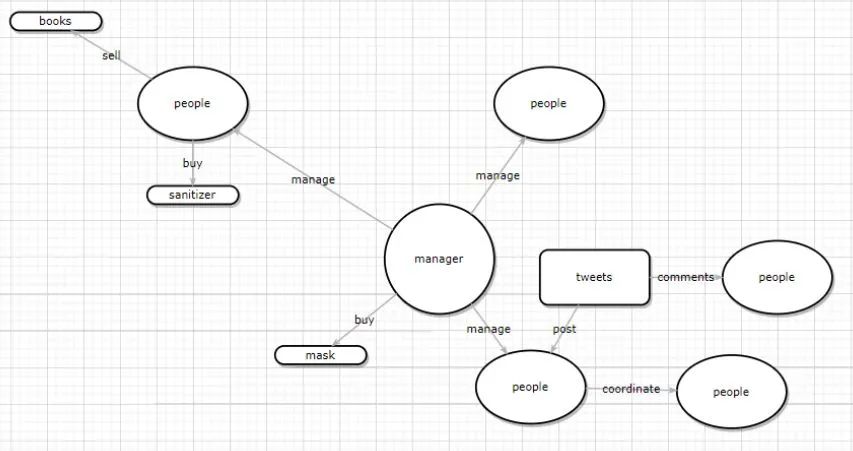
建模后,通过图查询语言(以neo4j为例:)
MATCH (boss)-[:MANAGES*0..3]->(sub), (sub)-[:MANAGES*1..3]->(personid) WHERE boss.name = “Jeff” RETURN sub.name AS list, count(personid) AS Total
很简单的就可以实现,同时效率提升几百倍。
这就是图数据的应用场景:一切以关系去考虑,去拓展的业务场景,都可以用图来实现,实现业务的革命。
