




事件背景
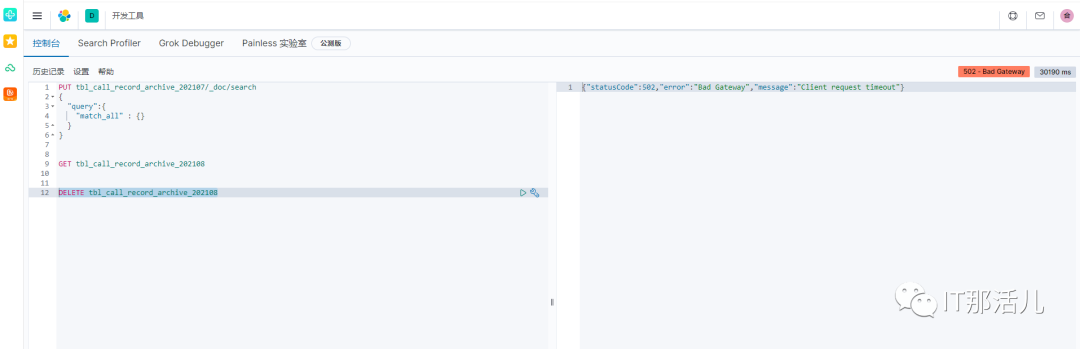
某日接业务侧反应elasticsearch查询速度很慢,偶尔出结果但是多数会超时,报错{"statusCode":502,"error":"Bad Gateway","message":"Client request timeout"}
分析过程
第一时间检查手机短信,因为es集群节点服务挂掉会有告警产生的,检查后发现并无告警发出。于是登录服务器进一步分析;
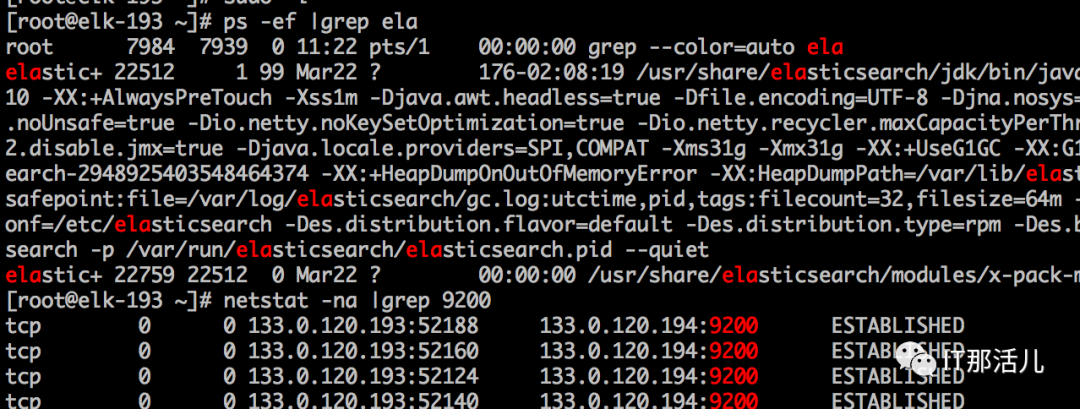
此es集群共计5个节点,逐一登录服务器查看进程和端口,发现所有进程都在,9200端口也正常,也都有正常的连接.
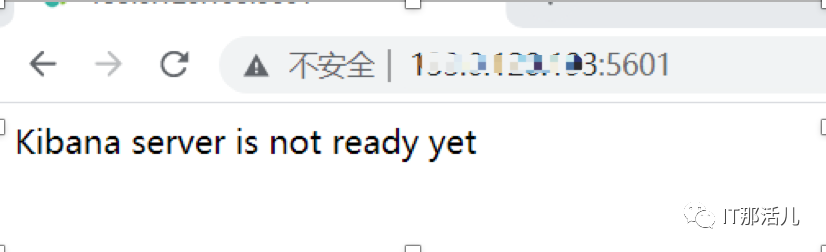
于是模拟业务反应的命令,使用kibana进行查询,发现确实timeout,此时查看kibana日志,并无明显异常出现。

因近期集群内新加入的业务较多,es集群为多个业务合用,于是第一反应是kibana的内存不够,于是修改了kibana的jvm配置,并重启kibana。此时发现启动kibana无法连接es集群。报错"warning","savedobjects-service"],"pid":26191,"message":"Unable to connect to Elasticsearch. Error: Request Timeout after 30000ms"}而且kibana的5601端口也打不开。
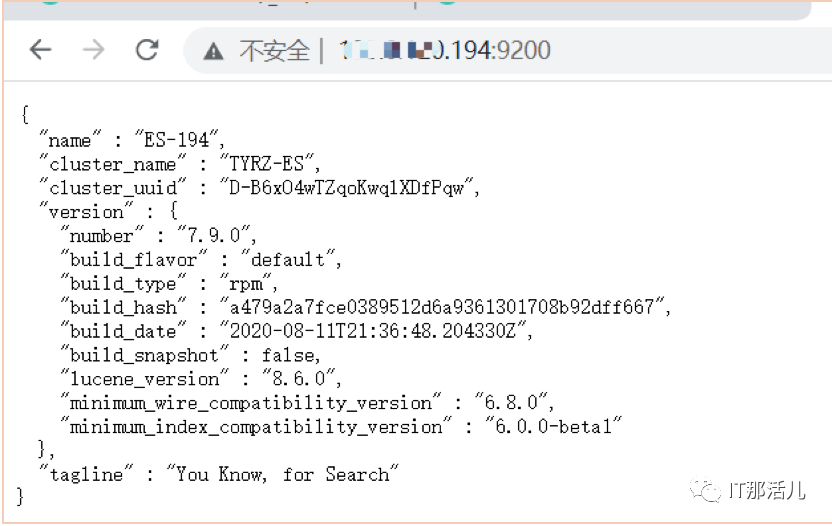
尝试修改timeout参数由30000ms至60000ms,再次重启报错依旧。于是怀疑es问题,再次使用9200端口逐个检查es,发现所有节点的9200都正常(包括最好定位问题的194节点)。
此时使用_cat/nodes命令检查,发现从其他节点看不到194节点。
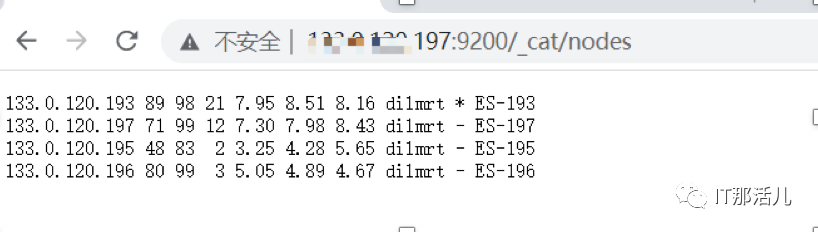
于是怀疑问题出现在194节点,再次进去194机器检查,发现es的数据盘有一块损坏,目录/data10

因es集群有副本的机制,损坏一块盘其实不影响数据的整体性的,但是这块损坏的盘似乎导致了194节点的es服务hang死,被集群其他节点踢出,但是进程和端口却又依旧存在,导致了告警的失效。
为了尽快恢复服务,我们修改了194节点的es配置,将path.data:内容注释了data10这个损坏的路径,然后重启了194节点的es服务。
再次检查_cat/nodes,发现已成功加入集群,登录kibana也成功进入。
通知业务查询,已经能够跑出结果了。

此时的集群状态为yellow,主要是损坏的盘中丢了副本,需要等待集群进行数据的同步完成。
最终es集群同步完成,集群恢复为 green状态。

总结结论
elasticsearch的数据目录故障会导致集群状态异常,即使故障节点的服务和端口正常,甚至9200端口信息都正常;
单纯的进程和端口告警已无法满足监控es集群的状态了;
定位问题后再回头查看194的日志,其实能找到/data10的报错的,但排查问题时因节点数过多没有仔细查看每个es服务日志的上下文

后续考虑对磁盘报错也进行监控,从而避免这种因硬件故障导致的服务异常出现。

更多精彩干货分享
点击下方名片关注
IT那活儿

