




一、首先从https://github.com/apache/hudi.git将hudi clone到自己本地idea,使用以下命令编译hudi
mvn clean install -DskipTests -DskipITs -Dcheckstyle.skip=true -Drat.skip=true -Dhadoop.version=3.0.0注意:目前hudi使用的是hadoop2.7.3版本,CDH6.3.0 环境使用的是hadoop3.0.0, 所以在打包的时候需要加上-Dhadoop.version=3.0.0参数
二、使用MR查询hudi-hive表任务所需配置
1、将hudi-hadoop-mr-0.6.0.jar 上传到/opt/cloudera/parcels/CDH-6.3.0/jars 2、之后软连接到此目录 opt/cloudera/parcels/CDH-6.3.0/lib/hive/lib 3、执行安装MR框架JAR
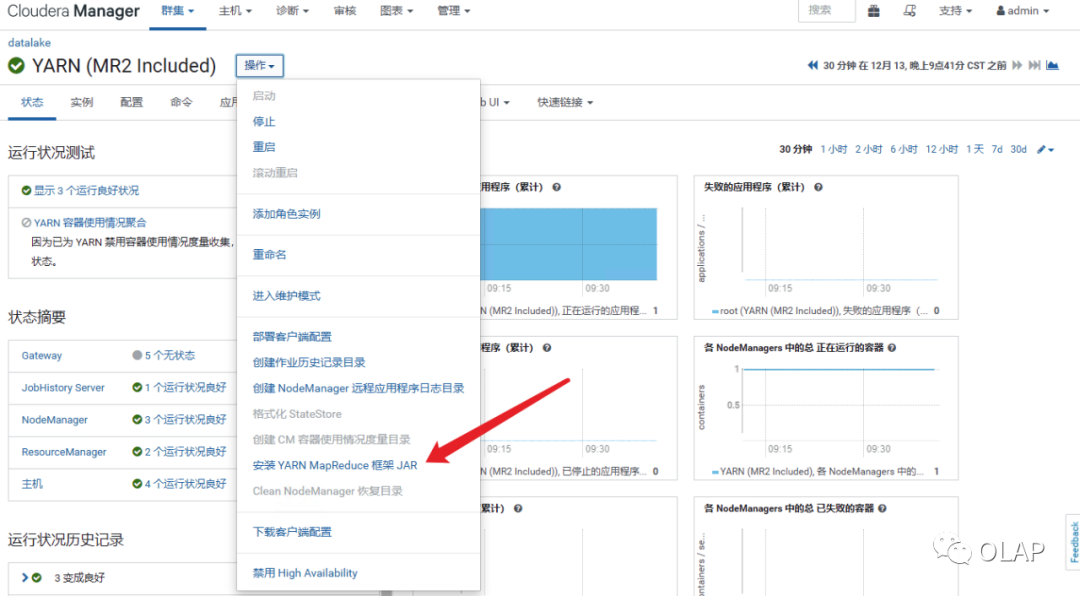
新建hive辅助路径 /data/hive/jars (根据你的需求命名)并且在CHD界面配置
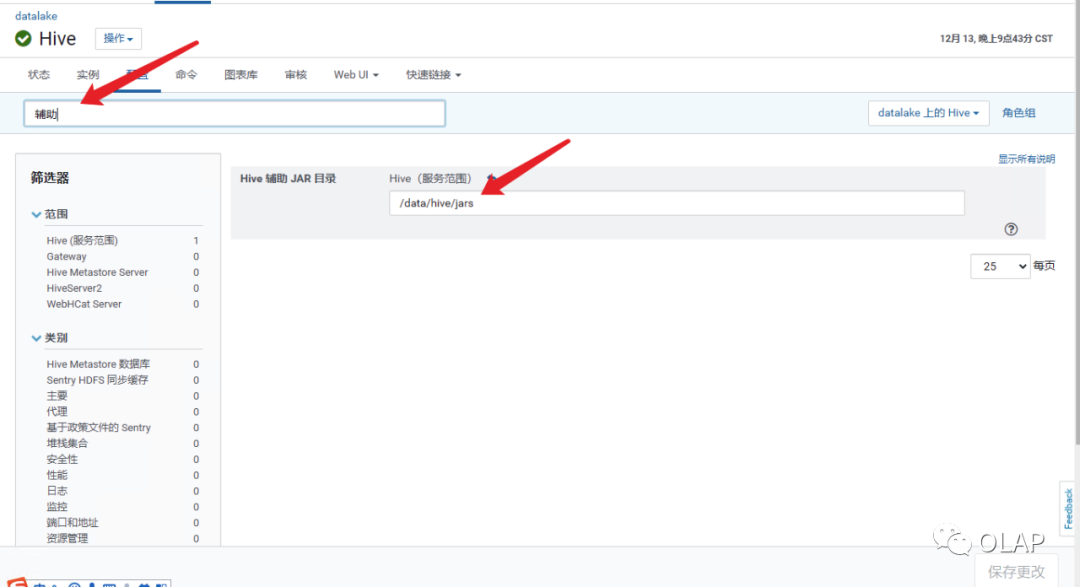
将以下jar包上传至辅助路径下
1、hudi-hadoop-mr-bundle-0.6.0.jar(如果数据存储在aliyunOSS则需要以下三个jar一并放置在hive辅助路径下)
2、aliyun-sdk-oss-3.8.1.jar
3、 hadoop-aliyun-3.2.1.jar
4、jdom-1.1.jar
三、运行使用hive用户执行赋权命令
GRANT all on uri 'oss://data-lake/xxxxx' to role xxxx;运行一个delastreamer-hudi任务
spark-submit --name xxxx \ --driver-memory 2G \ --num-executors 4 \ --executor-memory 4G \ --executor-cores 1 \ --deploy-mode cluster \ --conf spark.executor.userClassPathFirst=true \ --jars hdfs://nameservice1/data_lake/jars/hive-jdbc-2.1.1.jar,hdfs://nameservice1/data_lake/jars/hive-service-2.1.1.jar,hdfs://nameservice1/data_lake/jars/jdom-1.1.jar,hdfs://nameservice1/data_lake/jars/hadoop-aliyun-3.2.1.jar,hdfs://nameservice1/data_lake/jars/aliyun-sdk-oss-3.8.1.jar \ --class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer hdfs://nameservice1/data_lake/jars/data_lake_1.jar \ --op INSERT \ --source-class org.apache.hudi.utilities.sources.JsonKafkaSource \ --schemaprovider-class org.apache.hudi.utilities.schema.FilebasedSchemaProvider \ --target-table t3_ts_iov_event_push_detail \ --table-type COPY_ON_WRITE \ --source-ordering-field updateTime \ --continuous \ --source-limit 100000 \ --target-base-path oss://data-lake/xxxxxx \ --enable-hive-sync \ --transformer-class org.apache.hudi.utilities.transform.AddStringDateColumnTransform \ --props hdfs://nameservice1/data_lake/xxxxxx/kafka-source.properties
