




摘要
客户简介

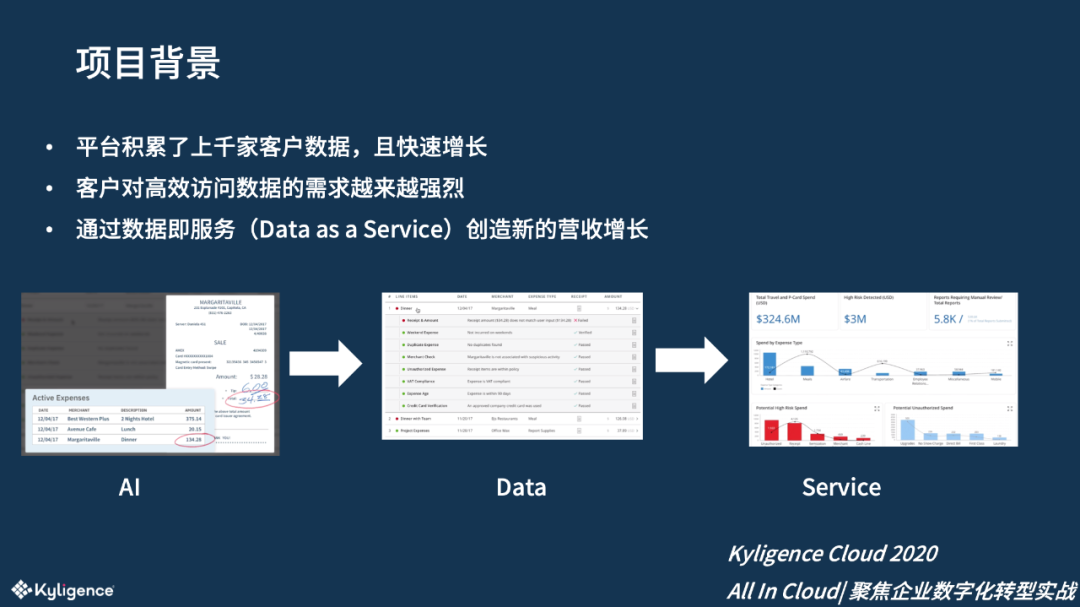
项目背景
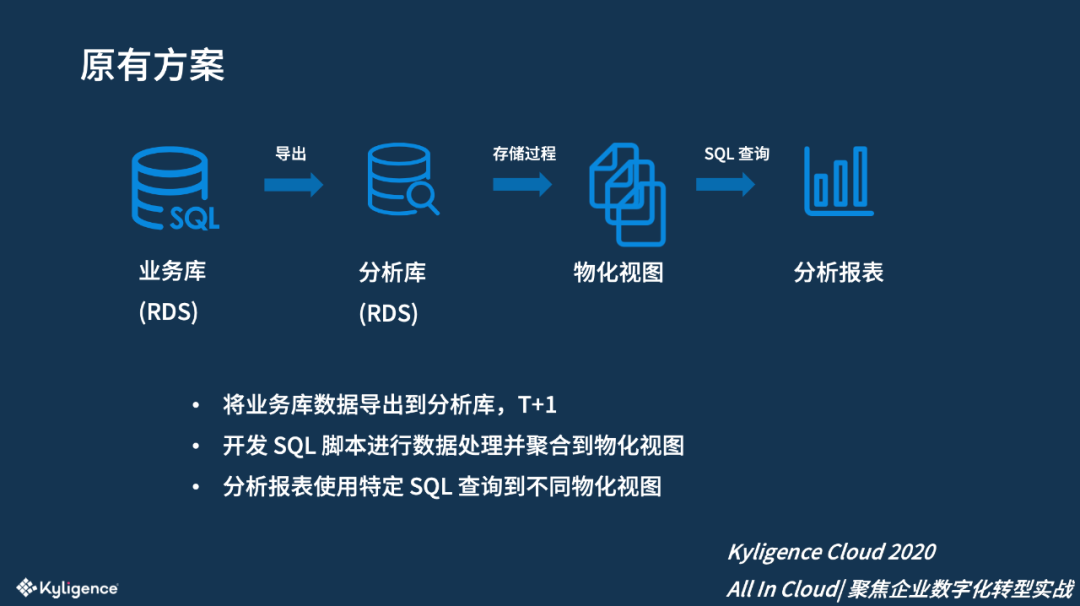
原有方案
面临的挑战
使用传统 RDBMS,不能水平伸缩。
聚合查询通常超过 5 秒,并且难以同时运行多个查询。
新需求需要前后端一起开发,周期长,投入大。
无法提供灵活分析。
T+1 重刷物化视图,刷新平均需10小时以上。
仅能存放近半年历史数据,不能存放全量。
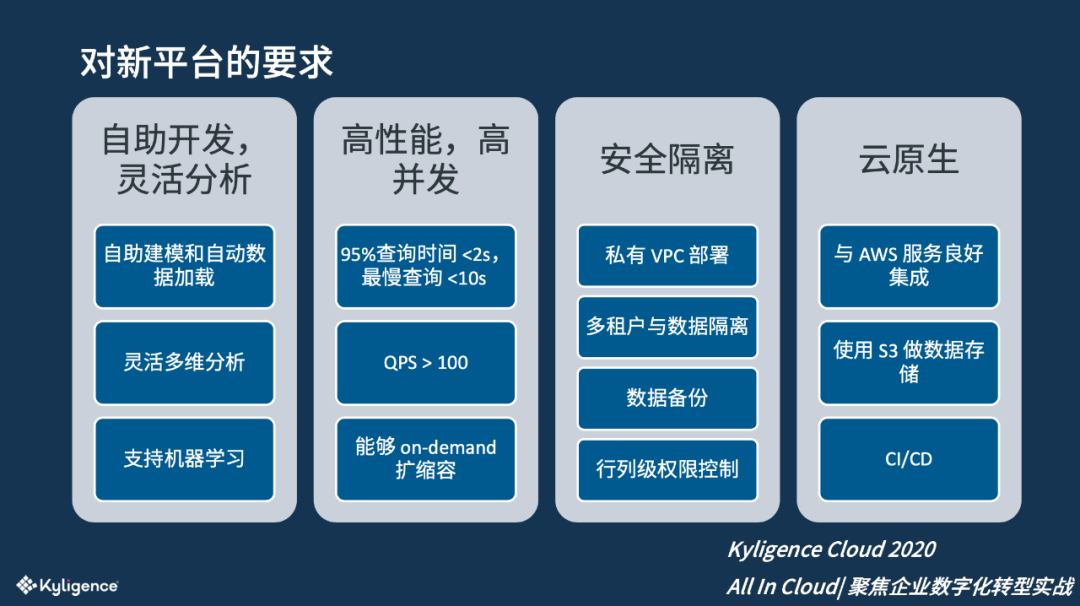
对新平台的要求
解决方案:Kyligence Cloud
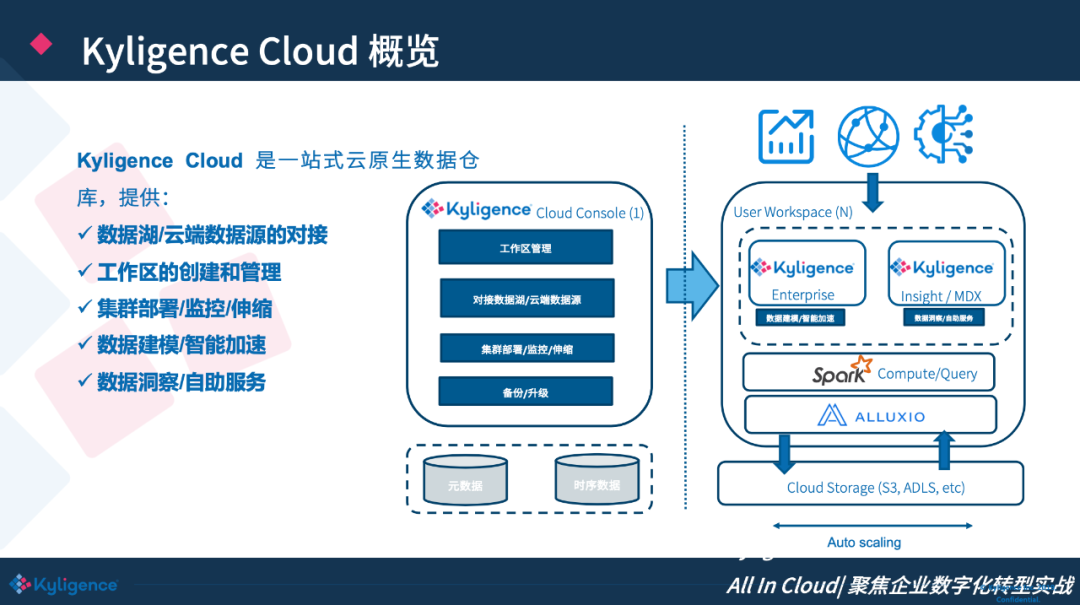
数据湖/云端数据源的对接。支持直接对接云上的数据源,比如说S3、 RDS。
工作区的创建和管理。可以满足多租户的需求。
集群部署/监控/伸缩。部署时间不超过5分钟。
数据建模/智能加速。Kyligence Cloud 具有AI增强的分析模式,用户不仅可以便捷地创建业务分析模型,而且能对不同的查询做智能加速。
数据洞察/自助服务。包括Kyligence Insight、MDX、SQL 接口,可以连接到客户的不同分析系统。
Kyligence Cloud DaaS 方案介绍
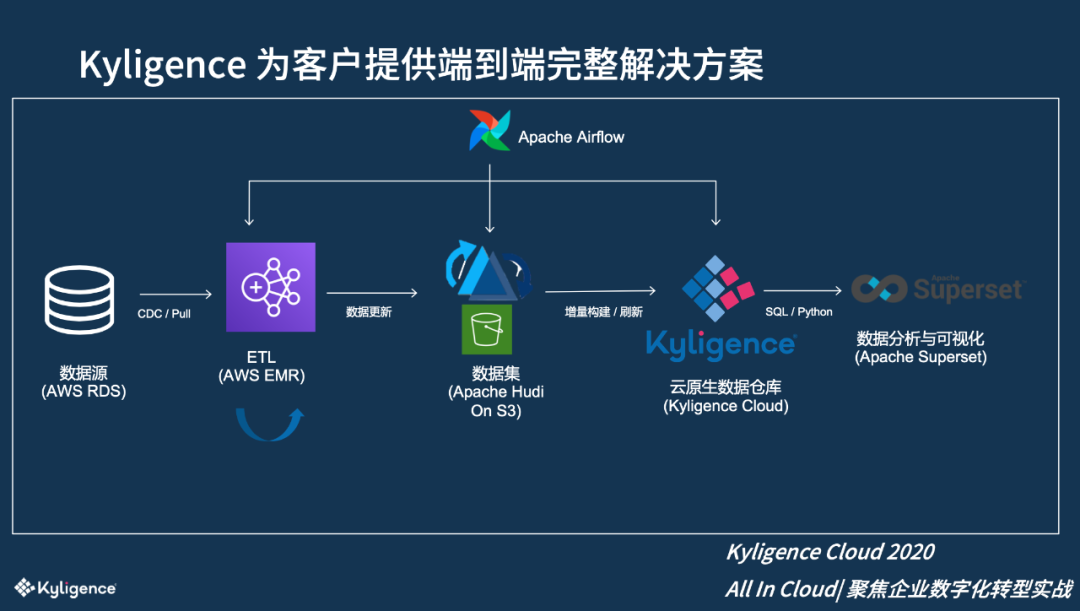
Kyligence Cloud DaaS 方案亮点
引入新技术 Apache Hudi。这个项目开始的时候, Hudi还在Apache孵化器,它帮助在海量数据上进行代价比较小的Upsert,同时可以保证每一批数据修改的原子性。在此之前,在大数据集上做增量更新有时候会失败,导致数据不一致,需要管理员的手动介入,成本非常高。在今年初的时候,AWS EMR官方宣布集成了Hudi并提供技术支持,进一步证明这个方案是可行的,为我们带来了信心。
集成 Alluxio 分布式缓存,解决性能和并发的问题。Alluxio可以透明地把热数据Cache在内存或者本地磁盘中,把冷数据存储在S3中。一方面提高了查询访问的性能,另一方面减少对S3 API的调用,减少网络带宽使用,从而进一步帮助节省成本。
读写分离。Kyligence Cloud采用两个Spark集群,一个集群用于数据加工计算,另外一个集群用于线上查询,以此确保数据负载的分离,保证查询的高稳定。计算数据的集群可以自动按需启动,而且根据数据量大小,自动向AWS请求合适的计算资源。这可以大幅度节省资源,因为在云上CPU是非常昂贵的。
Airflow 全自动的调度。我们为客户基于 Airflow 开发了端到端的数据加工链路,实现了全流程的自动化调度、自动告警、自动重试等;最终做到端到端的增量数据更新延迟小于1小时。
数据不出VPC,所有计算都在客户的 VPC 内,只能通过 VPN 接入,从而保证了高安全性。
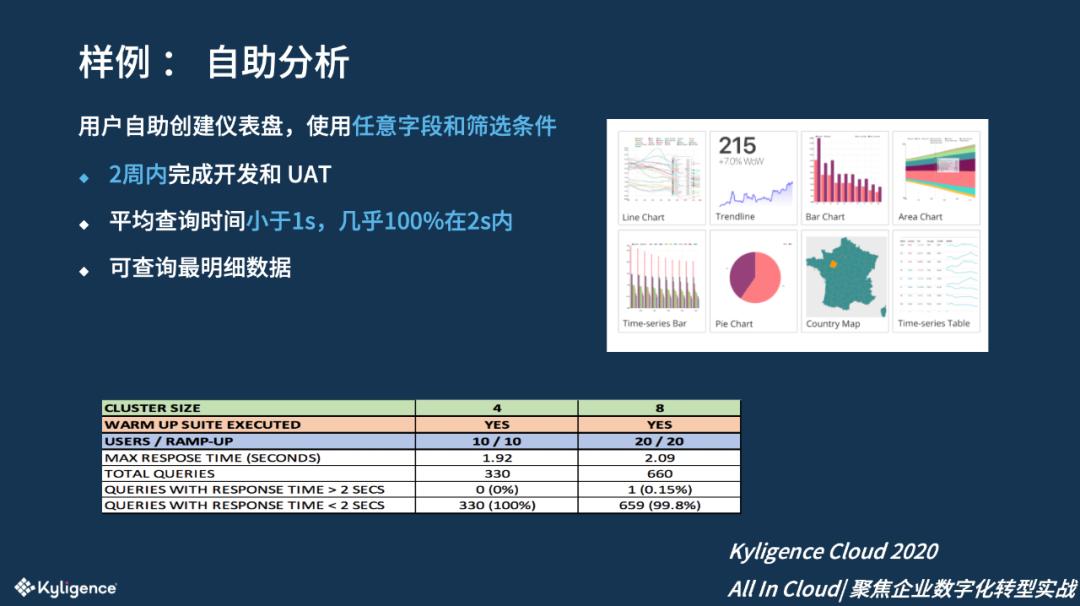
自助分析
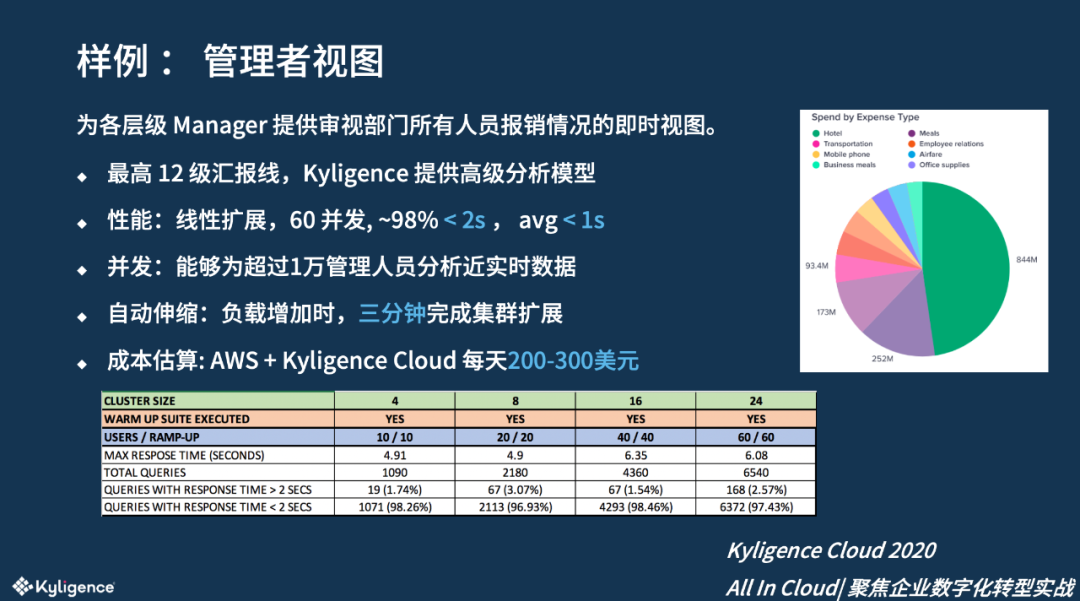
管理者视图



点击“阅读原文”下载 PPT
