




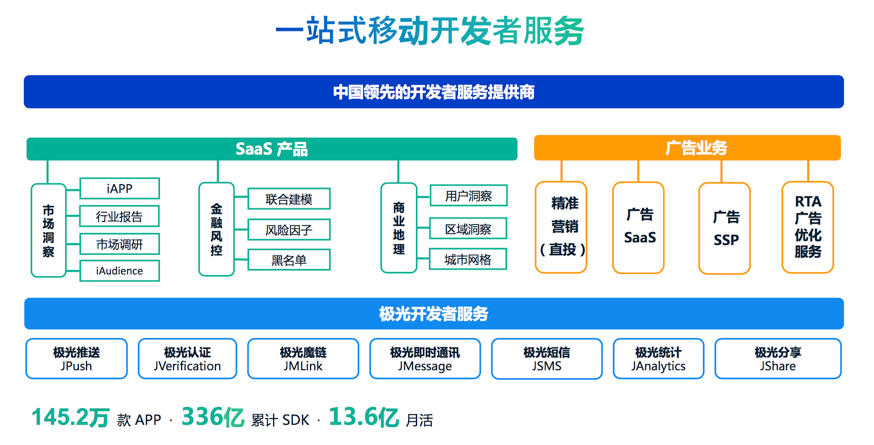
Kylin 在极光业务中的应用
极光多维分析面临的技术挑战
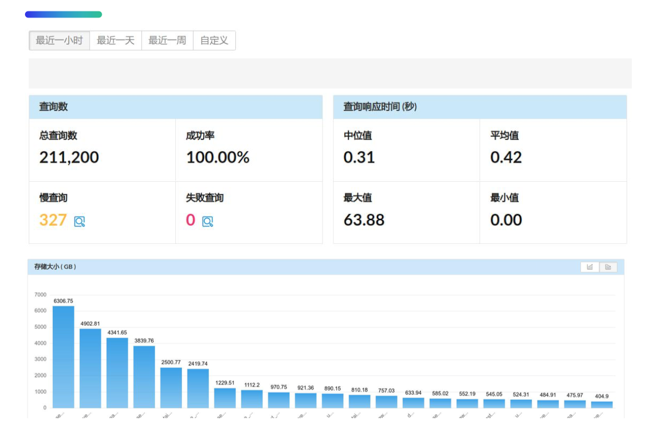
OLAP 工具选型对比

Kylin 是一个综合的系统,架构本身是可插拔的,比如说像 Build 构建或者查询都可以选用 Spark,当然 Build 也可以选用 Flink。针对后端的存储,社区版默认 Cube 存储是用 HBase,美团使用的后端是 Kylin on Druid,Kylin 商业版以及社区版下一个大版本采用的是 Kylin on Parquet,Kylin 开源版的 Cube 都是存储在 HBase上,但 HBase 的存储结构和coprocessor有限的扩展能力带来了诸多影响,例如做聚合查询需要把数据都扫出来,然后再到单台机器上去做聚合。
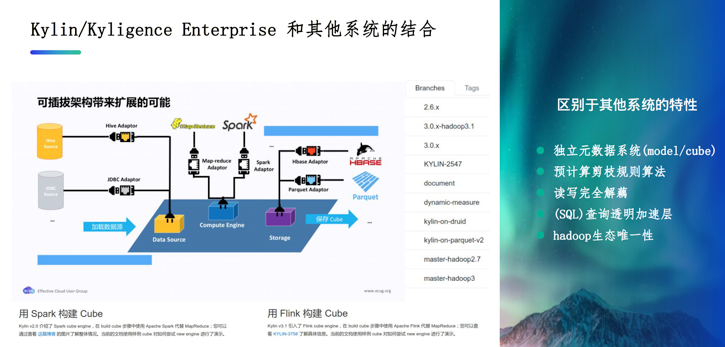
提供独立的元数据系统
提供成熟的预计算剪枝算法规则
实现读写的完全解耦,不需要企业自己去基于 Spark 或是基于 Flink 来实现
实际上可以把 Kylin 当做是 Hadoop 上 SQL 查询透明的加速层, 企业习惯使用 Hive 进行查询和数据分析的话, HQL(Hive SQL) 可以不加修改地放在 Kylin 或者企业版 Kyligence 上运行,只不过因为预计算的存在, 查询的速度会快几个量级
Kylin 还拥有在 Hadoop 生态系统中的唯一性. 目前 Hadoop 生态圈中成熟的MOLAP 解决方案基本只有 Kylin/Kyligence Enterprise 这一个选择
从 Kylin 升级到 Kyligence(Kylin 商业版)
升级背后的原因
HBase 运维繁琐
Cube 元数据不稳定,异常频繁
当 HBase 负载高了之后 Cube 重构修复代价非常高
常用的高基维的查询慢、TopN 性能在社区版较差
复合索引查询慢
业务优化 Cube 查询能力有限
直接面向外部用户,性能要求达不到客户需求
有 Kylin 相关技能的专业人员招聘困难
人才培养周期较长
异常定位慢,解决问题周期长,影响线上 SLA
Kylin vs Kyligence(Kylin 商业版)
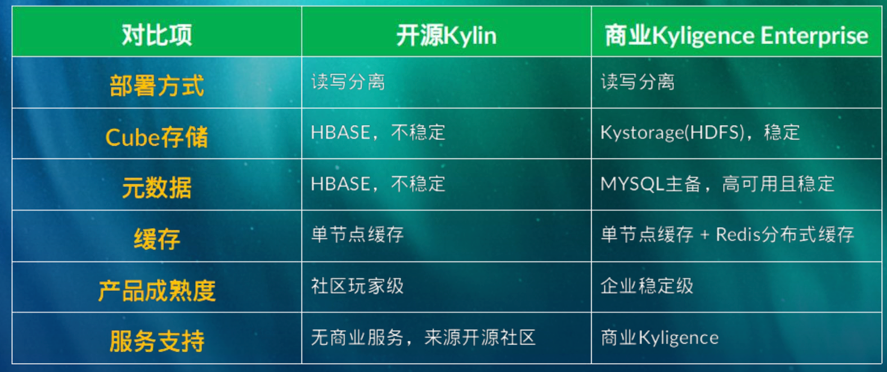
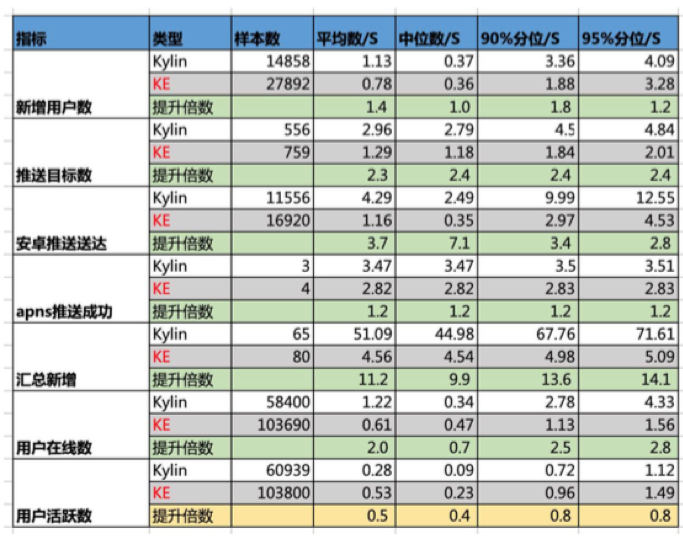
汇总新增:90%分位由原先的68秒提升至5秒以内
安卓推送送达:90%分位由10秒提升至3秒
推送目标数:95%分位由4.5秒提升至2秒内
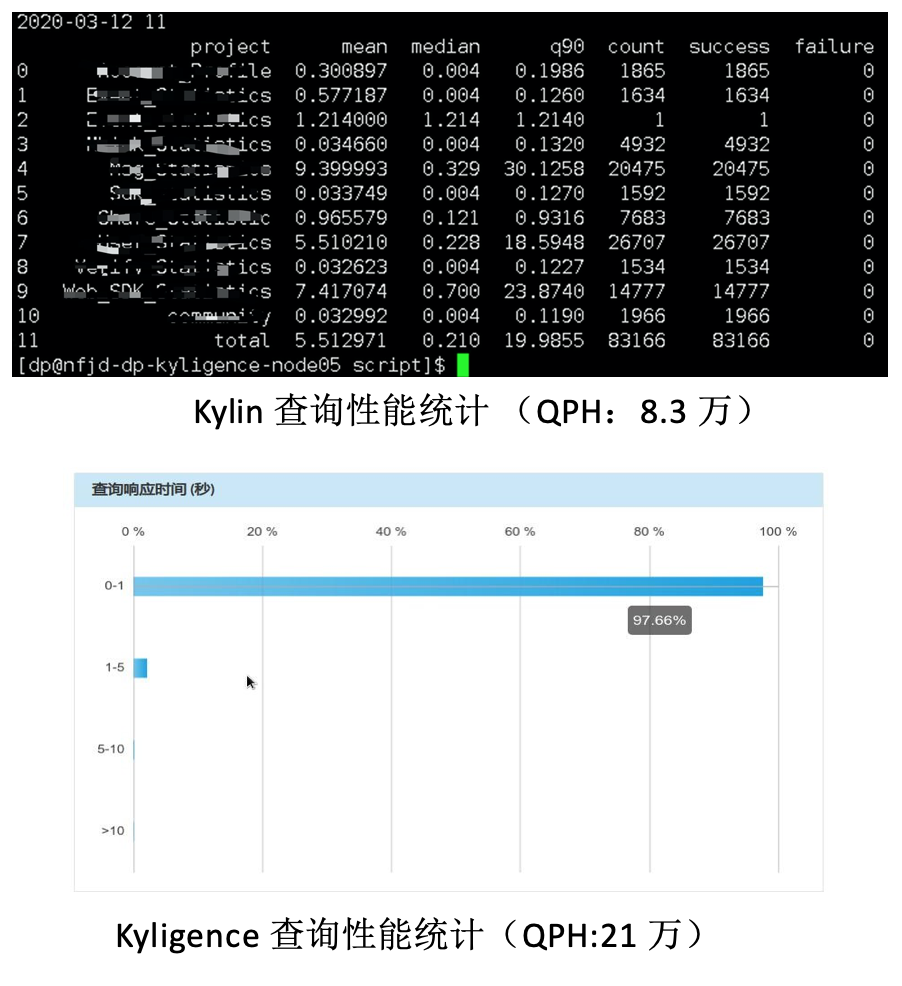
不停机平滑迁移方案
首先就是查询并发压力大,每天面对百万级查询请求,同时并发压力大,迁移过程中也要保证原有开源 Kylin 查询准确,不能中断业务
项目周期短,开源 Kylin 在使用过程中已经明显支撑不住查询压力,需要快速进行迁移,有 200+ 个Cube,14000+个 segment 待迁移,整个过程不能有停机的问题出现,Cube 存储架构改变后需要去反复确认源数据,确保两边的数据一致性。
同步优化慢查询,需要快速优化高基维、TopN Cube,循环统计慢查询进行优化。
异常定位回溯,Hive 历史会有数据回溯,但对数据校验要求较高,迁移过程中开源 Kylin 故障持续,源数据修复及人工刷新导致校对难度大。
前端迁移方案是基于 Nginx 转发,好处是对下游使用者或是业务方完全透明, 不需要配合做任何额外操作. 转发规则的控制全部在 Nginx 中控制,形成灰度的升级,业务人员的日常使用不受任何影响。
想要做好这一步,首先需要设置访问路由,如下图架构,就是把 Kylin 的 Query 查询和 Build 通过 Nginx 在上层完全分隔开,即做成两个 Nginx 分别映射,再通过 MySQL 集群 VIP 去访问,提供给下游访问的唯一的 VIP,下游只需要知道这个 IP 就行,前端不需要改任何东西。
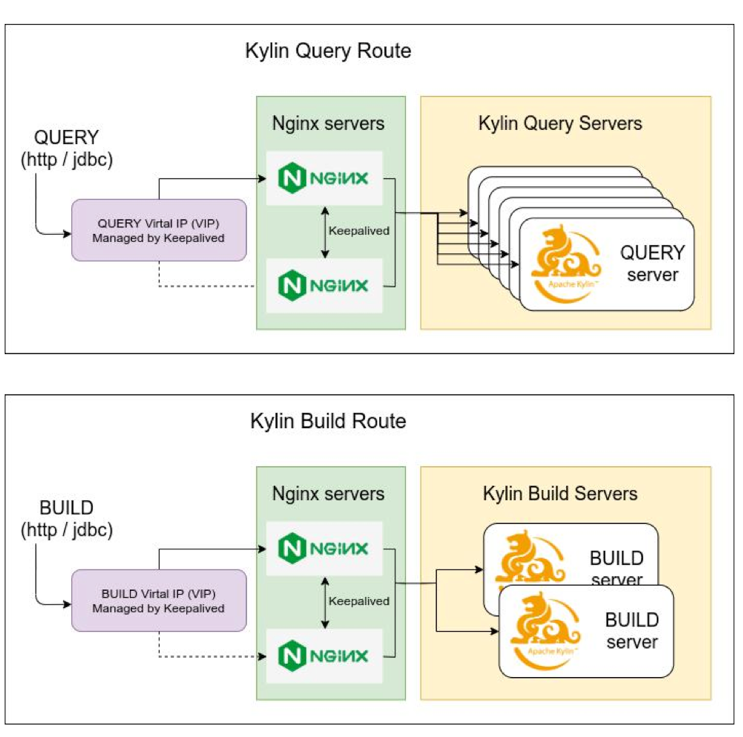
如上图,Query 的 http或者JDBC 请求都是通过同一个 VIP 访问Nginx集群,最终会通过 Nginx 轮询分发给 Kylin 各 Query 节点;nginx可以从API URL可以直接拿到cube名称, 虽然不能获取project名称但是可以通过加入cube/project字典查得所属project. nginx取得cube和project之后, 就可以按需求通过转发规则控制cube或者project粒度的转发, 从而实现查询的灰度上线.
Build 也类似(Build 请求上没有 JDBC,只有http),也是通过 VIP 访问 Nginx 集群,然后 Nginx 根据转发规则去转发给各 Build 节点。Nginx 对 Build 请求的处理略有不同, 从 build 的 request body data 能取得project名称, 但是 cube 名称需要从request body data 的 SQL 中解析. 我们通过 lua 代码从 SQL 中提取了 cube 名称, 从而实现通过转发规则控制 cube 或者 project 粒度的转发.
迁徙过程中有对 Build 构建业务和 Query 查询业务两个模块分开来灰度迁徙,build业务保持双跑, 保持新老集群数据一直方便出问题时随时回退切换. 两边数据核对无误之后按project粒度灰度切换Query业务, 全程下游无感知不停机. 具体细节如下:
(2)Query 模块迁徙也是类似的方法,通过 VIP 去访问, Nginx 完全控制查询应该转到哪一个集群的转发规则,下游业务对接不需要做任何修改,而且可以做 Cube 级别的切换,就是控制每一个 Cube 去访问每一个集群,而且整个过程是不需要停滞的,下游没有感知。
以上两部分区分开后,先把 Build 迁徙切换完成,然后通过 Nginx mirror 进行 Build 双跑,使两边 Segment 达到同步平衡。然后迁徙 Query 业务模块,Query 可以按照 Cube 或者按照 Project 在 Nginx 中配置进行增量迁移,让下游业务无感知的进行查询业务迁徙。

关于 Kyligence
Apache Kylin 在 PB 级别数据上带来了开创性的即时分析能力,并被全球超过1000多家企业所使用。由 Apache Kylin 核心团队创立的 Kyligence 公司的使命以自动化数据管理、发现、交互及洞察来为其客户提升生产效率。
Kyligence 获得了来自红点、思科、宽带资本、顺为资本、斯道资本(富达国际自有投资机构)及 Coatue Management 等投资机构的多轮投资,其全球客户包括欧莱雅、Xactly、招商银行及华为等。公司以双总部运营,中国总部位于上海,美国总部位于美国加利福尼亚硅谷圣何塞。
联系我们
网站:https://kyligence.io/
邮件:info@kyligence.io
电话: +86 21-61060928


点击“阅读原文”下载完整会议资料
