




当提到“实时分析”,大家脑海里首先浮现的是大屏上不断跳跃闪烁的数字和波动的曲线,让人有种纵观全局的掌控感。类似这样的场景多出现在资源监控或是领导驾驶舱大屏展示中,这些都属于“实时分析”中比较简单的应用场景,用于及时了解数据变化。
(酷炫的实时监控大屏)
对于企业来说,不仅要及时观察核心指标的变化,更重要的是了解其变化背后原因。通过对数据展开探索式的分析,获得对业务较为全面的洞察理解,从而为后续的运营决策、营销决策、风控决策等等提供信息支撑。在电商节的促销活动中,电商平台和商家们都密切关注着活动期间实时的交易数据流量。通过实时的分析这些活动流量数据,比如用户活跃率,转化率等关键指标信息,可帮助平台和商家们及时调整相关活动计划策略,从而提升整个活动的营销收入与效益。
批流一体架构面临的挑战
传统架构
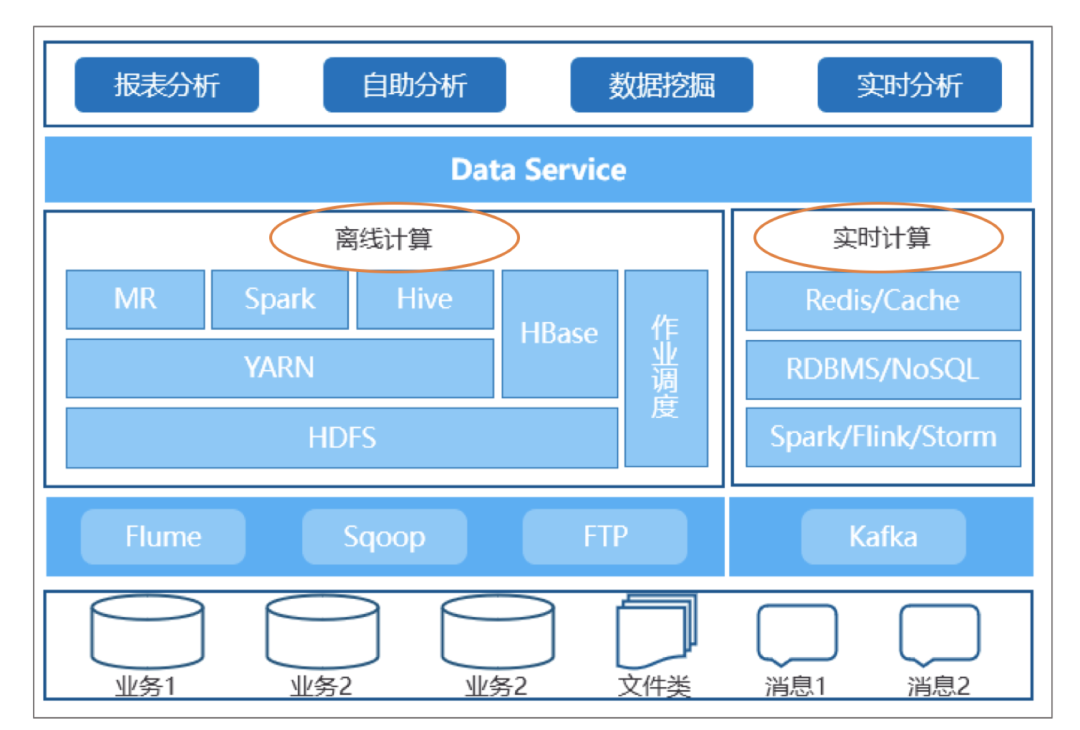
分别维护实时分析与离线分析两套不同架构的服务,对于系统运行的稳定性,后续应用升级,故障处理等都会比较复杂和繁琐;
分别设计、管理实时分析与离线分析两套不同的数据模型,离线分析可以通过关联获取更加丰富的数据,而实时分析为了保障数据时效性能只能是简单的宽表形式进行处理,而且开发流程较繁琐;
因实时数据与离线数据存储介质的割裂,最终导致两者数据在存储时就相互隔离,更无法对两者进行统一的数据周期管理;
在数据服务层中需要根据应用层进行定制化的开发,为不同的应用提供不同的数据服务,同时也使得这个查询服务层的维护成本增加不少。
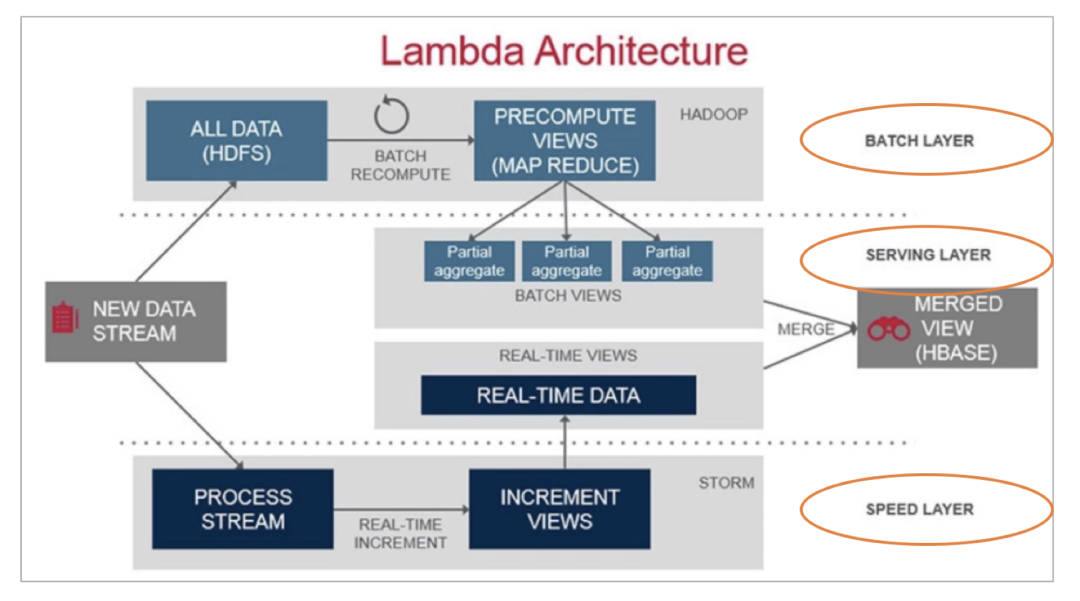
Lambda架构
Speed Layer 负责实时处理数据,计算逻辑直接对接流数据,尽量缩短数据处理的延迟,但由于流数据天生的数据质量不可控,尽管缩短了数据处理时间,但可能牺牲数据的正确性和完整性;
Batch Layer 负责批量规模性处理数据,可以保证数据的正确性和处理规模
Serving Layer 负责融合 Speed 和 Batch 两个部分的数据能力,对外提供简单一致的数据访问视图。
Kappa 架构
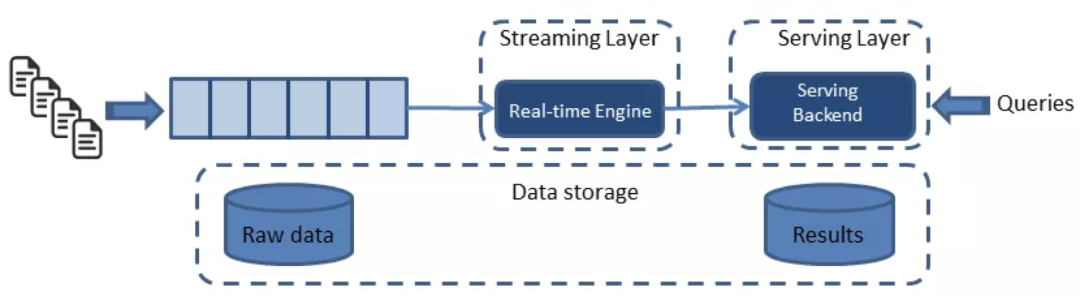
基于上述对传统方案、Lambda、Kappa 这些数据架构的讨论,以及企业应用的实际需求,我们认为在数据架构的灵活性、加工逻辑的便捷性、数据模型治理等角度还有更优解。接下来,我们将从批流一体架构这关键部分:数据模型、数据生命周期以及查询服务,进行探讨,为正在进行批流一体选型企业提供一些参考。
基于Kyligence的批流一体大数据分析架构探索
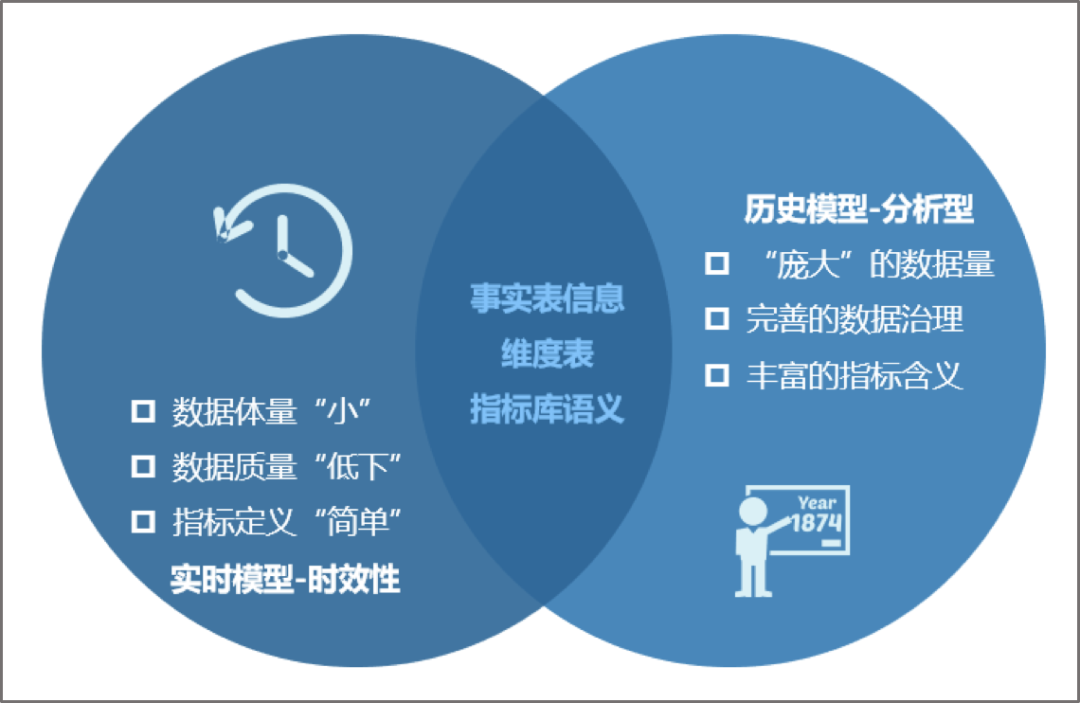
数据模型
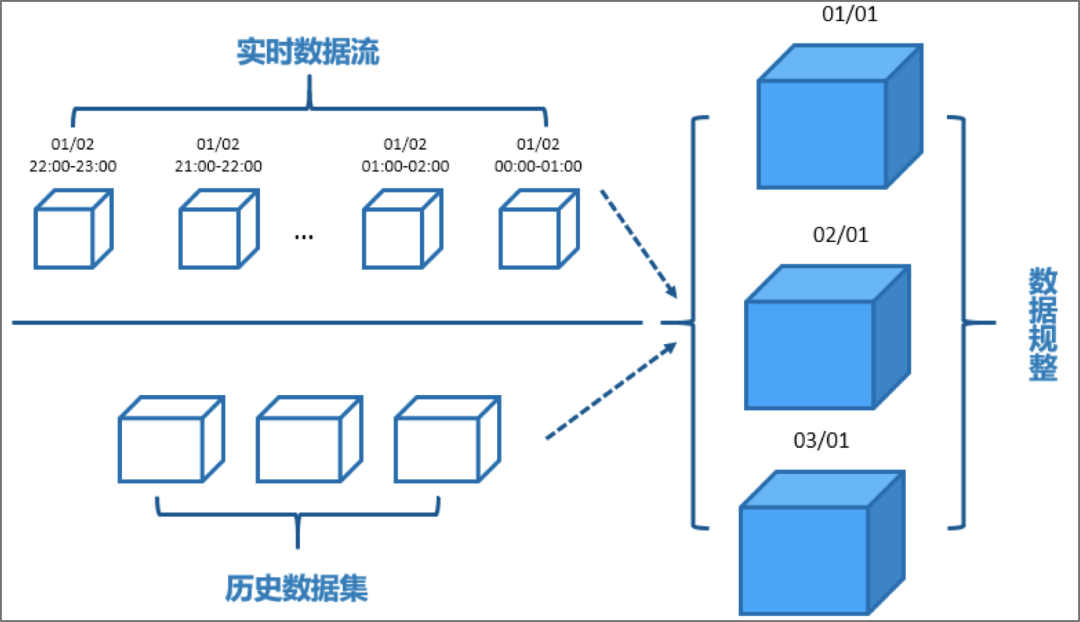
数据生命周期
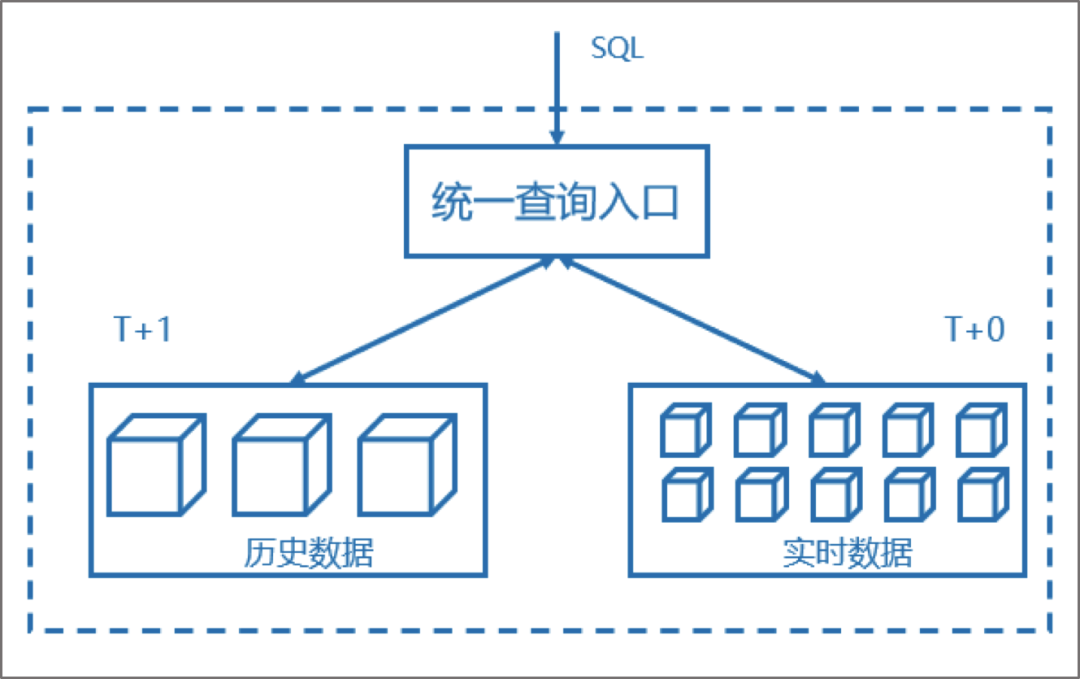
查询服务
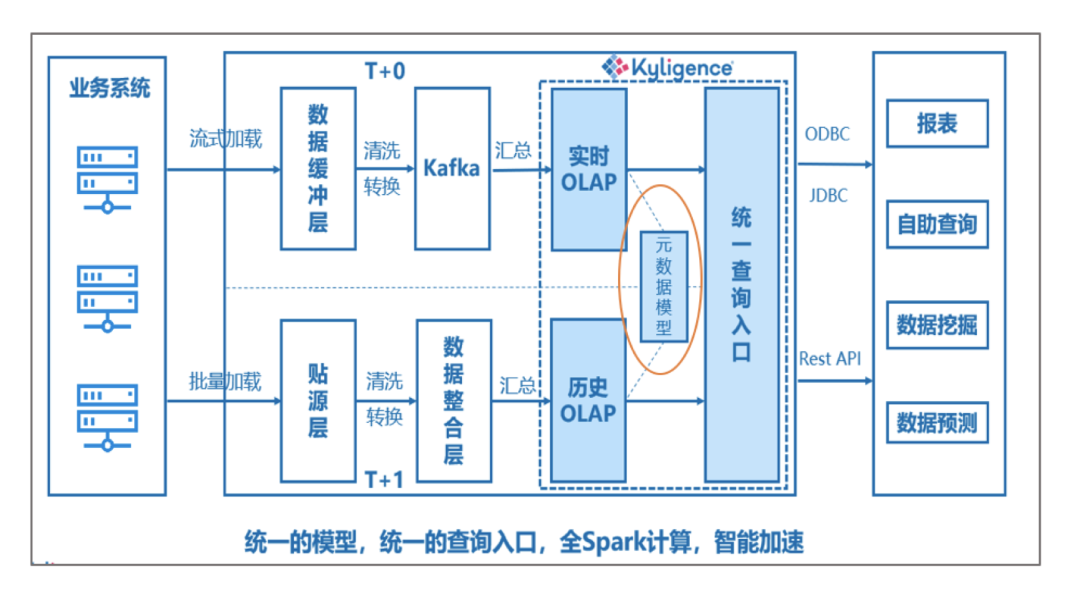
方案优势
模型统一管理方面:改进实时数据模型过去只能支持单一Kafka Topic数据的宽表主题,让其也能和历史模型一样,并共享相同的维度表数据,可实现标准星型和雪花模型设计,从而也实现了对模型的统一设计管理;
数据生命周期方面:借助于Lambda架构优势,将实时与历史数据处理分开并行进行处理,这样的设计不仅很好的保护已有的历史数据资产不做变更或以较小的代价改动,而且能够使用历史数据对实时不满足的地方进行修正并覆盖,对于监控类或其他“低数据质量”要求的场景也可以直接将实时数据沉淀为“历史”数据。为不同的应用场景提供更加灵活的数据生命周期管理;
统一查询服务方面:开发智能的查询路由作为查询服务统一查询入口,支持标准的ANSI SQL语法,通过对元数据模型的识别,可分别对实时数据集与历史数据集进行探测并解析,返回查询请求所预期的数据结果,同时以超快的响应速度支持。
在整个“实时”业务支持与实现过程中,对比其它架构中企业需要运维底层复杂的基础架构,以及在实现流程上繁琐的代码开发工作来说,企业现在只需要其上面进行模型设计与管理,以及数据生命周期定义的操作,极大地提升了工作效率,同时减轻了运维工作负担和成本投入。
小结


这里“阅读原文”,下载【批流一体解决方案】
