




#导入数据,这里是通过选择文件file.choose()导入csv格式的数据文件。mydata <- read.csv(file.choose())

#查看数据前6行head(mydata)

#查看全部数据print(mydata)

#查看数据结构str(mydata)

# 重命名9、10、11列的列名colnames(mydata)[9:11] <- c("CCAG","COG","MAG")

# 删除第3列,可以看到pattern列没有了mydata[,-3]

# 删除第3行数据mydata[-3,]

# 提取第3行mydata[3,]

# 提取第3列mydata[,3]
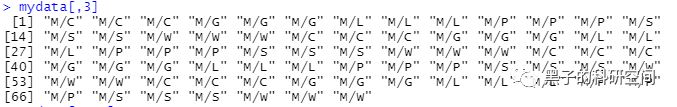
# 提取1到3行的数据mydata[1:3,]

# 提取1到3列的数据mydata[,1:3]

# 创建新的列New <- c(1:72)# 创建新的数据框mydata2mydata2 <- data.frame(mydata,New)

# 创建行rowrow <- c(1:12)# 添加row到mydata,形成新的数据框mydata3mydata3 <- rbind(mydata,row)

# 增加1列,列名为New,新增的列是LER列和MO列的和transform(mydata,New=LER+MO)

# 调用dplyr包library(dplyr)# 选择mydata数据集中nitrogen=120的数据mydata %>% filter(nitrogen==120)

# 将列LER提取出来select(mydata,LER)

# 选择1到5列select(mydata,1:5)

#选择列名中有字母"O"的列select(mydata,contains("O"))

#选择列名中以字母“M”开头的列select(mydata,starts_with("M"))

#以列pattern进行排序arrange(mydata,pattern)

#按年份以降序排列arrange(mydata,desc(year))

文章转载自ZJH的学习笔记,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
