




1.介绍
BTREE ----> InnoDBRTREE ----> MongoDBHASH ----> RedisFULLTEXT ----> ES
二分法 ---> 二叉树 ---> 红黑树 ---> Balance Ttree(平衡多叉树,简称为BTREE)
B-TREE : 普通 BTREEB+TREE : 叶子节点双向指针B*TREE : 枝节点的双向指针
Each InnoDB
table has a special index called the clustered index that stores row data. Typically, the clustered index is synonymous with the primary key. To get the best performance from queries, inserts, and other database operations, it is important to understand how InnoDB
uses the clustered index to optimize the common lookup and DML operations.
When you define a
PRIMARY KEY
on a table,InnoDB
uses it as the clustered index. A primary key should be defined for each table. If there is no logical unique and non-null column or set of columns to use a the primary key, add an auto-increment column. Auto-increment column values are unique and are added automatically as new rows are inserted.If you do not define a
PRIMARY KEY
for a table,InnoDB
uses the firstUNIQUE
index with all key columns defined asNOT NULL
as the clustered index.If a table has no
PRIMARY KEY
or suitableUNIQUE
index,InnoDB
generates a hidden clustered index namedGEN_CLUST_INDEX
on a synthetic column that contains row ID values. The rows are ordered by the row ID thatInnoDB
assigns. The row ID is a 6-byte field that increases monotonically as new rows are inserted. Thus, the rows ordered by the row ID are physically in order of insertion.
也就是说,InnoDB表中一定是有聚簇索引。
附录:MySQL 聚簇索引生成说明官档
https://dev.mysql.com/doc/refman/8.0/en/innodb-index-types.html
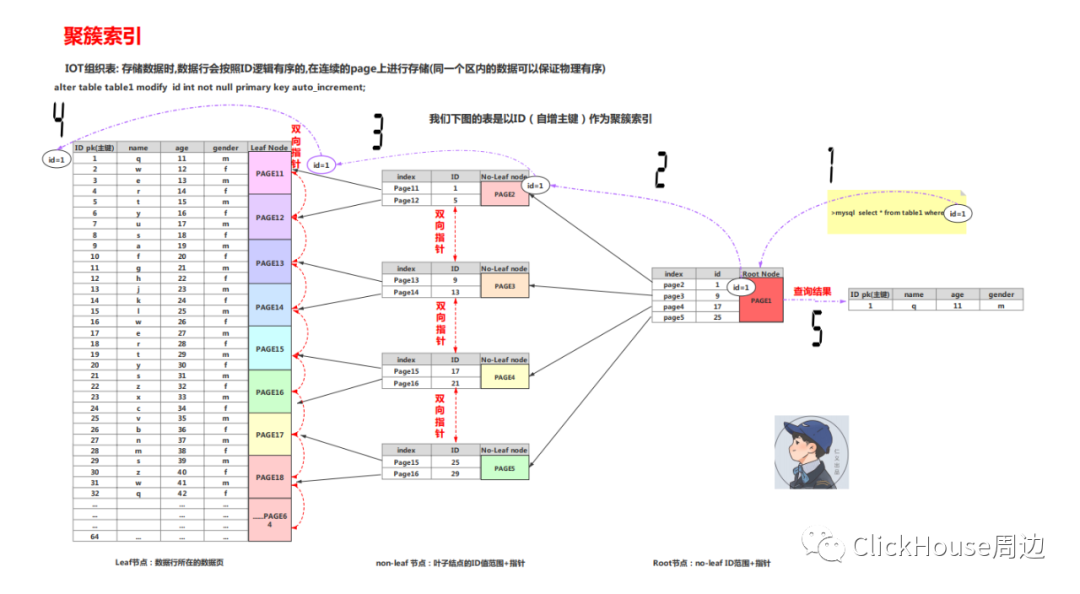
InnoDB, each record in a secondary index contains the primary key columns for the row, as well as the columns specified for the secondary index.
InnoDBuses this primary key value to search for the row in the clustered index.
附录:MySQL 二级索引生成说明官档
https://dev.mysql.com/doc/refman/8.0/en/innodb-index-types.html
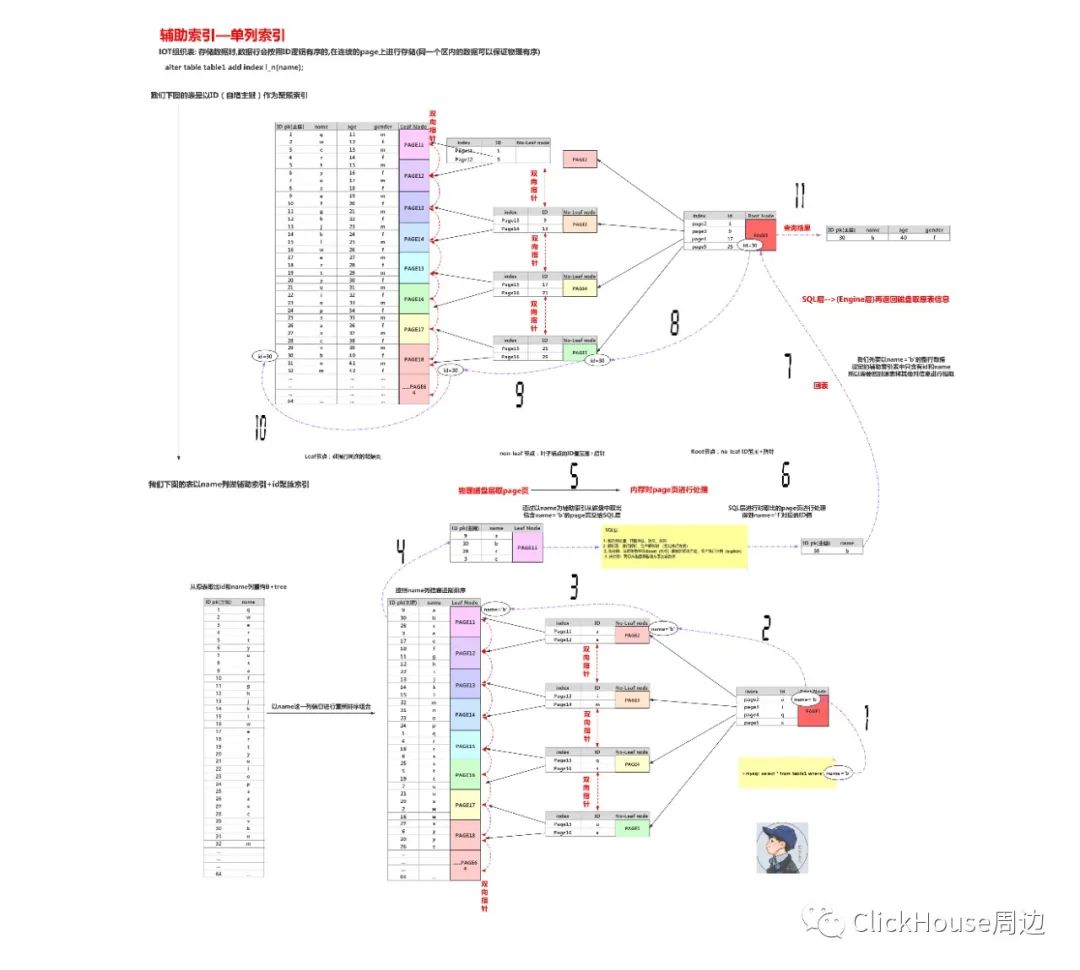
⭐ 怎么减少回表?
1. 辅助索引不能够完全覆盖查询结果,可以使用联合索引;
2. 尽量让查询条件精细化,尽量使用唯一值多的列作为查询条件;
3. 优化器:MRR(Multi-Range-Read),ICP(index condition pushdown) ,锦上添花的功能。
mysql> select @@optimizer_switch;mysql> set global optimizer_switch='mrr=on';
可以采用分区表。一个实例里管理。 按照数据特点,进行归档表(pt-archiver) 分布式架构(针对海量数据、高并发业务主流方案)
