




简述时序数据库Influxdb工作原理.
我这里主要针对Influxdb2.0做一些分享.
🔖 一、基本概念.
一些时序数据库中的基本概念。
1.1 基本概念.
时序数据库的概念.
什么是时序数据库:时序数据库就是随着时间不短产生的一系列数据,简单点来说就是带时间戳的数据。也可以这样理解,时间序列是一连串基于时间的数据点,他们主要以时间为索引,描述了某个被测量主题在每个时间点被测量的值.
时序数据的主要特点就是数据量大,写多读少、几乎不进行更新和删除操作.
时序数据的特点:数据量大、写多读少、几乎不进行更新和删除操作.
Influxdb 和 MySQL 之间的对比.
性能分析.
和其他时序数据库性能对比.
和传统数据库之间的对比.
influxdb
优点:独立部署.
TSM存储引擎,高写、数据压缩.
灵活支持TAG写入.
Tag索引.
灵活的数据保留.RP.
基本概念:
influxdb 中的基本概念.
Influxdb SQL Bucket database measurement table point row tag 有索引的列 field 没有索引的列 series 数据结构:表示的含义是:相同measurement 和 tags 的都属于同一个series. 同一个Block里面一定都是同一个Series,但是一个Series,并不仅仅存在一个Block里面. 下文经常出现的:SeriesKey=measurement+tags,这里应该是tagk=tagv,否则是没有意义的. 因为Tag是用来给数据进行打标的。
type Series struct {
mu sync.RWMutex
Key string // series key
Tags map[string]string // tags
id uint64 // id
measurement *Measurement // measurement
}
1.2 适用场景分析.
什么场景下需要使用时序数据库:一切数据和时间序列有关系的都可以使用influxdb来进行存储。下面具体分析分析.
数据监控:后台程序数据收集、分析.
服务器监控:服务器CPU、内存监控.
事件跟踪:跟踪事件的状态. 一个事件的状态随时间相关的,比如START扫码买会员.
日志监控:日志也是和时间序列相关的,所以也可以使用influxdb来进行存储和展示.
用户行为:跟踪用户的行为. 用户在打开START之后,其所有的行为是在时间线上的.
DevOps:IT基础设施和应用的运维系统,采集、分析、设备运行和应用服务运行监控指标。DevOps 是一系列整合软件开发和软件运维活动的实践。目标是缩短软件开发周期并使用持续交付提供高质量的软件.
1.3 使用方法.
2.0 之前可以使用
InfluxQL
来进行操作,和SQL类似.show databases;
show measurements;
insert measurement,tagk1=tagv1,tagk2=tagv2 field1=value1,field2=value22.0版本需要使用
Flux
来进行操作.下面含义表示:查询
bucket
为mzx
中的数据,查询的是距离当前时间1天之内的数据。根据measurement
进行过滤.from(bucket: "mzx")
|> range(start: -1d)
|> filter(fn: (r) => r["_measurement"] == "student")
|> sort()
|> yield(name: "sort")可以通过下面的方式快速构建
Flux
查询语句.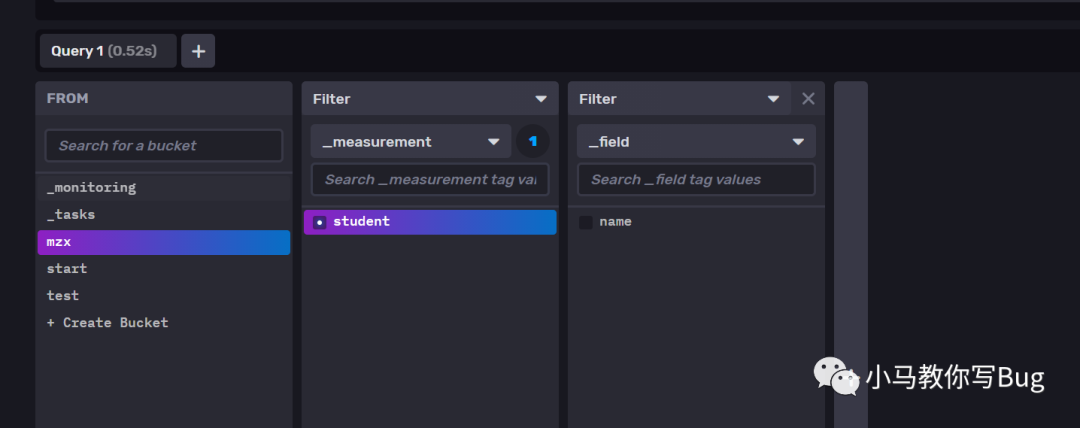
image-20210805160629687
2.3 客户端使用方法.
目前支持如下客户端:使用方法也很简单.

🔖 三、TSM 引擎. (技术选型)
Influxdb 引擎的技术选型也是很有意思的.
存储引擎 · InfluxDB中文文档 (gitbooks.io)
首先,我们先了解下问什么Influxdb选择自研TSM存储引擎:Influxdb 早期也就是0.8版本中允许多个存储引擎,包括LevelDB
、RocksDB
、LMDB
、HyperLevelDB
,而Influxdb0.9版本使用BoltDB
作为存储引擎,而0.11+版本支持的TSM存储引擎在0.9.5版本中发布. 其最终实现结果是:比B+Tree实现高达45倍的磁盘空间使用量的减少,甚至比使用LevelDB及其变体有更高的写入吞吐量和压缩率。
当我们首先使用LevelDB
(基于LSM树),LevelDB 带来的两大优势是写入吞吐量高、内置压缩,然而如果使用LevelDB,那么就会遇到下面的问题:LevelDB 不支持热备份,如果要对数据库进行安全备份,则必须将其关闭,然后将其复制。
RocksDB
和HyperLevelDB
解决了这个问题,但是还有一个更为紧迫的问题:那就是用户自动管理数据保留的方法,这意味着我们需要大量的删除,在LSM树中,删除(LSM
树删除其实也是通过向WAL写入特殊删除来进行删除,其并不会立即删除)与写入同样昂贵,为了避免删除操作,我们将数据分割成Shrad
数据,这些数据是连续的时间块,Shard 通常会持有一天或者7天内的数据,每个Shard 映射到底层的LevelDB,同样这个意味着我们需要关闭数据库来删除底层文件到达删除一天的数据的目的。
为了解决上面出现的问题,RockesDB
的用户提出一个ColumnFamilies
的功能:将时间序列数据放入Rocks时,通常将时间块分成列族,然后在时间到达时删除他们,但是新的问题又来了:当InfluxDB中有大量数据时,LevelDB将数据分解成许多小文件,最终造成了一个问题就是:有一年的数据的用户将用尽文件句柄,将任何数据库推演到极致都会遇到这个问题。
为了解决文件句柄用尽的问题,Influxdb 决定将引擎转移到BoltDB
(0.9.0-0.9.2),BoltDB 是一个纯粹的Golang数据库,它具有与LevelDB相同的API语言:keyspace
有序的存储. BoltDB对我们来说最大的好处就是使用单个文件作为数据库,这解决了RocksDB
文件句柄过多的问题. 但是在运行一段时间之后,发现,在数据库超过几GB之后,IOPS开始成为影响Influxdb的性能瓶颈. 在 0.9.3-0.9.4
版本的发布,我们在写之前加一个WAL,这样可以减少随机插入的keyspace
的数量. 但是这,高IOPS
仍然是一个问题。
于是TSM就出现了.

3.1 存储引擎TSM Tree.
InfluxDB详解之TSM存储引擎解析(一) (fatedier.com)
每一个Shard中都包含一个TSM引擎.
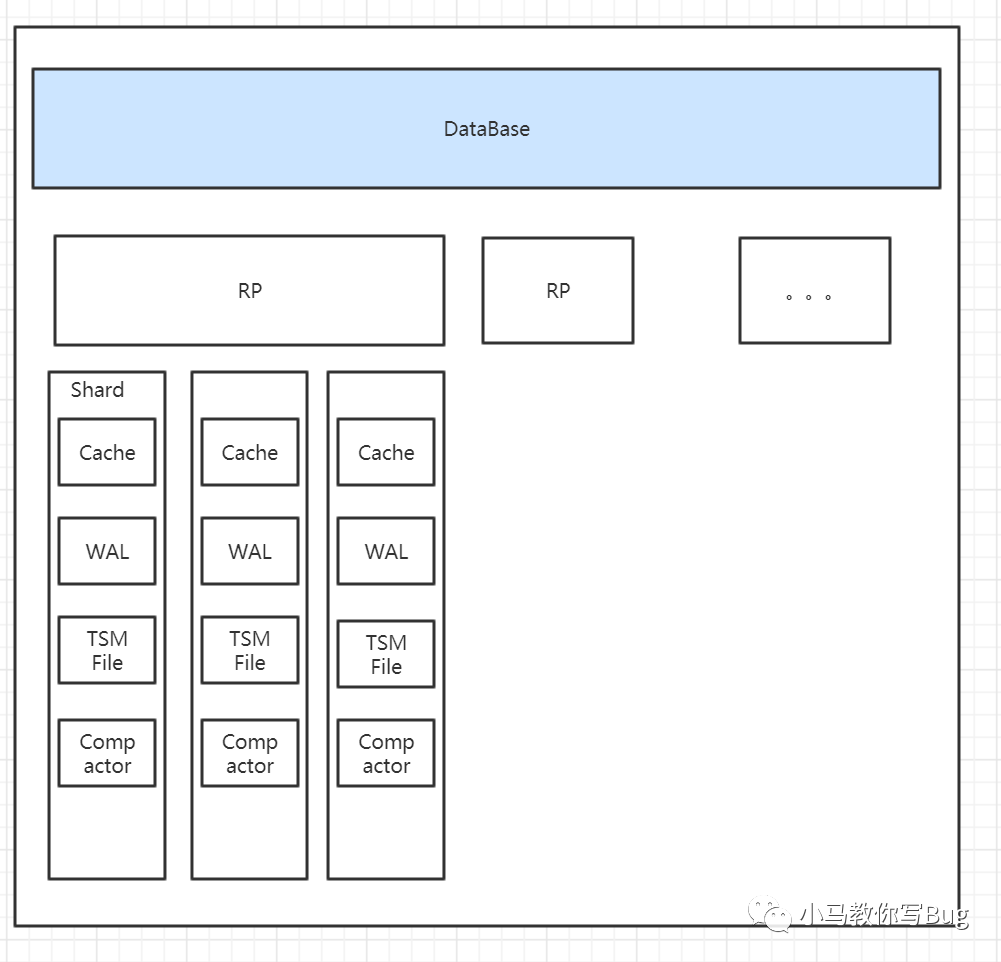
了解各个组件:
Cache
:相当于是LSM Tree中的 MemTable,在内存中一个简单的map
结构,这里的key为serieskey
(measurement+所有tags的序列化字符串.) +分隔符
+filedName
,map的Value
是一个数组.可以理解Cache为当前WAL在内存中的数据,因为写入数据时,会先向WAL中写入数据,之后会在想Cache中写入数据.Cache中的数据并不是无限增长的,有一个
maxSize
(默认是25M
)参数用于控制当前Cache中的阈值,当到达阈值后,会将当前的Cache进行一次快照,之后会清空当前的Cache中的内容,再创建一个新的WAL文件用于进行新的写入,剩下的WAL文件会被清除,快照中的数据经过时间排序之后写入新的TSM文件中.WAL
:WAL 中的内容与Cache
中的内容是相同,其作用为了持久化当前在内存Cache中的数据,当系统崩溃之后可以通过WAL文件恢复还没有写入到TSM文件中的数据. 这里要说明一下:数据是顺序追加到WAL文件末尾的, 所以其写入效率非常高.WAL 文件结构:
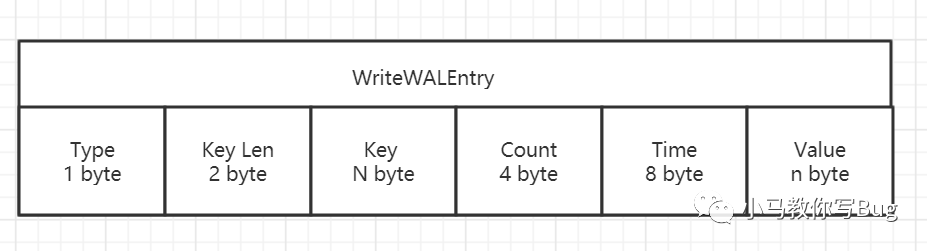
image-20210804203921520 Type:该项目中的Value类型.
Key Len:指明Key的长度.
Key:key的值:measument + tags + fieldName
Count:同一个Key下数据的个数.(从时间戳、Series中考虑)
Time:单个Value的时间戳.
Value:存储Value的具体内容.
TSM File
:TSM File 使用了自己设计的格式,对查询性能以及压缩方面进行了很多优化,具体如下;┌────────┬────────────────────────────────────┬
│ Header │ Blocks │ Index │ Footer │
│5 bytes │ N bytes │ N bytes │ 4 bytes │
└────────┴────────────────────────────────────┴重点说一下
Blocks
和Index每个block内存储的是某个TimeSeries的一段时间范围内的值,即某个时间段下某个measurement的某组tag set 对应的某个field的所有值,block内部会根据field不同的值类型采取不同的压缩策略。
块是成对的CRC32校验和和数据序列,CRC32用于块级错误检测,块的长度存储在索引中.
┌────────────────────────────────────────
│ Blocks │
├───────────────────┬───────────────────┬
│ Block 1 │ Block 2 │ Block N │
├─────────┬─────────┼─────────┬─────────┼
│ CRC │ Data │ CRC │ Data │ CRC │ Data │
│ 4 bytes │ N bytes │ 4 bytes │ N bytes │ 4 bytes │ N bytes │
└─────────┴─────────┴─────────┴─────────┴下面是Index部分:文件内的索引信息保存了 每个TimeSeries下所有的数据Block的位置信息,索引数据按照TimeSeries的Key(measurement-tagsets-timestamp)的字典序进行排列,在内存中不会把完整的index数据加载进去(内存中加载的索引应该是一个类似倒排索引的索引结构-间接索引),这样会很大,而只是对部分key做索引,称之为
indirectindex
。该indirectindex会保存一些索引的辅助信息,而仅仅通过一个索引就可以知道该Blocks中是否存在本次要进行索引的信息。若想要定位某个TimeSeries的Index数据,会先根据内存中的部分Key信息找到与其最相近的Index Offset,之后从该起点开始顺序扫描内存Index
,再精确定位到该Key在TSM文件中Index数据位置.┌──────────────────────────────────────────────────────
│ Index │
├─────────┬─────────┬──────┬───────┬─────────┬─────────
│ Key Len │ Key │ Type │ Count │Min Time │Max Time │ Offset │ Size │...│
│ 2 bytes │ N bytes │1 byte│2 bytes│ 8 bytes │ 8 bytes │8 bytes │4 bytes │ │
└─────────┴─────────┴──────┴───────┴─────────┴─────────
这里介绍一下Index中每一项的含义.
Compactor:
快照 - 缓存和 WAL 中的值必须转换为 TSM 文件以释放 WAL 段使用的内存和磁盘空间。这些压缩基于缓存内存和时间阈值发生。
级别压缩 - 级别压缩(级别 1-4)随着 TSM 文件的增长而发生。TSM 文件从快照压缩为 1 级文件。多个 1 级文件被压缩以生成 2 级文件。该过程一直持续到文件达到级别 4 和 TSM 文件的最大大小。
除非需要运行删除、索引优化压缩或完全压缩,否则它们不会被进一步压缩。较低级别的压缩使用避免 CPU 密集型活动(如解压缩和组合块)的策略。更高级别(因此频率更低)的压缩将重新组合块以完全压缩它们并提高压缩率。索引优化 - 当许多 4 级 TSM 文件累积时,内部索引变得更大且访问成本更高。索引优化压缩将
Series
和索引拆分到一组新的 TSM 文件中,将给定Series
的所有点排序到一个 TSM 文件中。在索引优化之前,每个 TSM 文件都包含大多数或所有Series
的点,因此每个都包含相同的系列索引。索引优化后,每个 TSM 文件都包含来自最小Series
的点,并且文件之间的Series
重叠很少。因此,每个 TSM 文件都有一个较小的唯一系列索引,而不是完整Series
列表的副本。此外,来自特定Series
的所有点在 TSM 文件中都是连续
的,而不是分布在多个 TSM 文件中。
🔖 四、索引.
TSM 是存储数据的一种结构,所以为了提高查询效率需要建立索引,Influxdb中的索引也被称之为间接索引.
LSM Tree 通过将大量的随机写转换为顺序写,从而极大提升了数据写入的性能,与此同时牺牲了部分读的能力,TSM 存储引擎基于LSM开发,所以情况类似,通常设计数据库时会采用索引文件的方式,TSM采用的是类倒排索引方式.
索引数据结构:插入数据时会更新DatabaseIndex结构中的数据.
先根据DatabaseIndex
过滤掉一些SeriesKey
,然后根据TimeStamp
从TSM File 保留在内存中的索引进行过滤一次.
type DatabaseIndex struct {
measurements map[string]*Measurement // 该数据库下所有 Measurement 对象
series map[string]*Series // 所有 Series 对象,SeriesKey = measurement + tags
name string // 数据库名
}
Influxdb 在启动时会对DatabaseIndex
进行初始化,从所有的Shard下的TSM File中加载Index数据,但是这里加载并不是全部加载,而只是加载Block
下面的最大时间和最小时间来进行索引,在进行查找的时候只需要根据时间戳就可以知道该数据位于那个Block
中.
我们再来看下面的数据结构:
type Measurement struct {
Name string `json:"name,omitempty"`
fieldNames map[string]struct{} // 此 measurement 中的所有 filedNames
// 内存中的索引信息
// id 以及其对应的 series 信息,主要是为了在 seriesByTagKeyValue 中存储Id节约内存
seriesByID map[uint64]*Series
// 根据 tagk 和 tagv 的双重索引,保存排好序的 SeriesID 数组
// 这个 map 用于在查询操作时,可以根据 tags 来快速过滤出要查询的所有 SeriesID,之后根据 SeriesKey 以及时间范围从文件中读取相应内容
seriesByTagKeyValue map[string]map[string]SeriesIDs // map from tag key to value to sorted set of series ids
// 此 measurement 中所有 series 的 id,按照 id 排序
seriesIDs SeriesIDs // sorted list of series IDs in this measurement
}
type Series struct {
Key string // series key
Tags map[string]string // tags
id uint64 // id
measurement *Measurement // 所属 measurement
// 在哪些 shard 中存在
shardIDs map[uint64]bool // shards that have this series defined
}
对于查询我们首先通过DatabaseIndex.measurements.seriesByTagKeyValue["tagK"]["tagV"]
获取到所有匹配的series
的ID值,然后通过Measurement.seriesByID
获取到指定的Series
,然后通过Series
结构体来发现该Series
在那些Shard
中存在. 至此我们在O(1)
的时间复杂度内获取到了所有符合要求的Series Key
然后我们就需要创建数据迭代器从不同的Shard中获取每一个SeriesKey中指定的数据通过时间,这里就需要使用到 TSM File
索引了,
TSM File内存索引:在内存中,TSM 为每一个TSM File维护了一个内存索引,但是其并不是将所有TSM File中Index部分的数据加载到内存中,而仅仅只是加载每一个Block
中保持的数据的最大时间和最下时间,每次通过Series定位到某一个Shard时,只需要根据时间就可以定位到本次要查询的Key的内容位于那个Block中。然后去访问TSM File中的详细索引,通过详细索引,我们可以知道其在TSM File中的偏移量.
定位到具体的Shard之后,仅仅只需要根据TSM FIle在内存中维护的索引的时间范围来进行比较即可知道当前的Key是否存在当前的Block
中.
🔖 五、增加.
图形化解释过程.
5.1 增加数据过程.
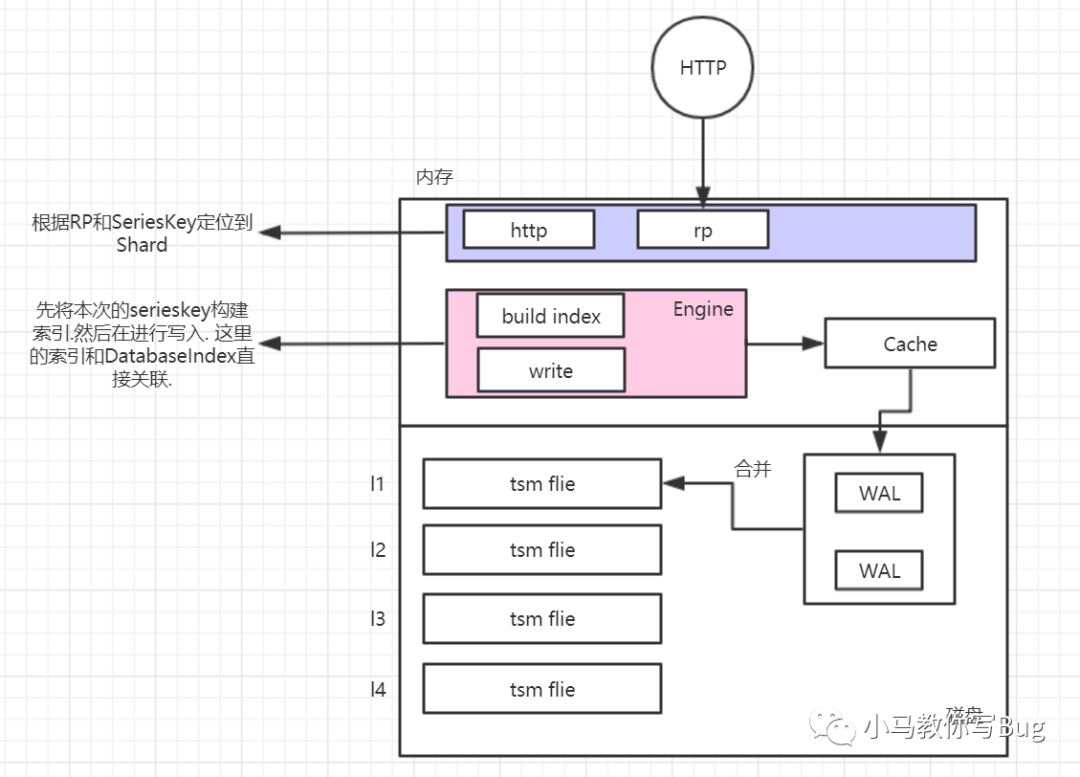
过程说明:
当influxdb接收到HTTP请求要增加数据的时候,influxdb会通过HTTP模块(解析SeriesKey)和RP模块来定位到其所在的ShardGroup.
然后在根据RP来定位到本次SeriesKey属于那个Shard. 当找到其属于那个Shard的Series之后,就需要进行写入了. 写入之前需要先构建索引,构建之后在进行写入缓存和WAL中. 当WAL超过25M则会进行写入L1中的tsm file中,其中最重要的就是将本次Sereis保存在seriesByTagKeyValue
map中。这里的map有点倒排索引的意思,通过倒排索引来快速定位到具体的Series. 进而可以快速的进行插入和查询.
🔖 六、高可用:以结果导向来进行分析.
如何实现高可用?InfluxDB集群方案在海量网络时序数据存储场景的应用 - 网管系统 - KM平台 (woa.com)
哈希一致性代理 + 缓存 + 多节点.
6.1 总体架构图.
如果要实现influxdb
的高可用,那么就必须搭建集群,但是可惜的是influxdb
的集群版本是商业闭源的。那么应该怎么实现呢?
参考KM文章,通过proxy
来进行实现. 架构图如下:
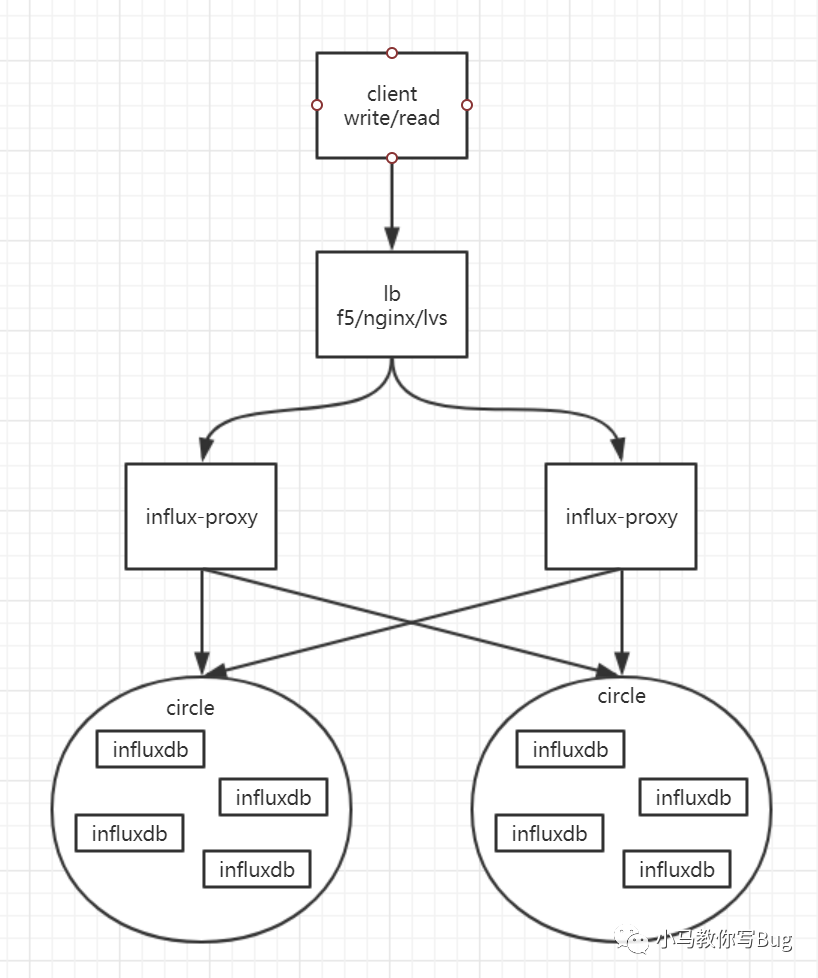
client:各种语言的influxdb的客户端.
lb:负载均衡,将客户端的请求均衡的发布到各个proxy地址.
influx-proxy:代理实例,
基于database+measurement
作为key使用一致性hash算法将读写请求分发到对应的`influxdb`实例中,同时具有全局配置中心管理、数据缓存、故障恢复等集群功能.circle:一致性哈希环,一个circle包含了若干个
influxdb
实例,共同存储了一份全量的数据,即每个circle全都是全量数据的一个副本,各个circle的数据互相备份.influxdb:influxdb单节点的实例,通过url来进行区分,一个实例只存储了一份全量数据的一部分数据.
6.2 集群高可用.
在集群高可用上,架构上可以部署多个proxy分摊压力,proxy之间无状态,一个挂掉不影响另外一个。如果在写入数据时有Influxdb实例出现故障,proxy会缓存失败的数据,直到Influxdb实例重新运行后,恢复重写。
性能测试对比:测试结果来自[KM文章](InfluxDB集群方案在海量网络时序数据存储场景的应用 - 网管系统 - KM平台 (woa.com))
压测条件:

压测结果:

