




工具美眉在介绍那么多性能指标之前,先带大家看张图:

这张图的横坐标是并发用户数,纵坐标分别是三个指标:(Utilization)资源利用率、(Throughput)吞吐量、(Response Time)响应时间。
响应时间——用户从发出请求到得到响应之间的总耗时,它由网络传输耗时、服务处理耗时等多个部分组成。
拿web浏览器的服务对响应时间进行说明:
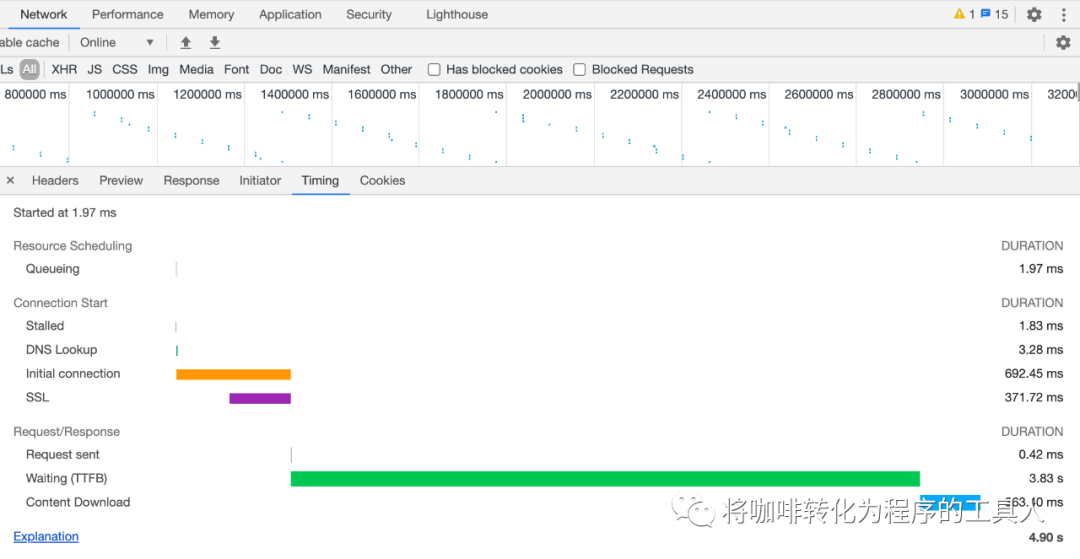
从这张图上看到一个由web发出的请求的响应时间由三部分组成:
Resource Scheduling
浏览器的资源调度,是否有更高优先级的请求,浏览器安排的排队时间
Connection Start
客户端与服务器之间建立连接的时间,包含了DNS域名解析时间、TCP握手时间、SSL认证时间
Request/Response
浏览器发出请求的时间+TTFB(浏览器收到首字节的时间)+整个response接受完的时间
吞吐量——单位时间内系统处理的客户请求数量,吞吐量的常用量化指标有QPS、TPS等。
并发用户数——同一时刻与服务器有交互的在线用户数。
图中三条曲线分别代表了随着并发用户数增加,资源利用率、吞吐量和响应时间的情况,分别分割成了三部分:(Light Load)轻负载区,(Heavy Load)重负载区和(Buckie Zone)塌陷区。
图中1标志的位置,代表了资源利用率接近饱和;2标志的位置,代表了吞吐量开始下降;3标志的位置,代表了响应时间变慢,开始影响用户体验。
从上图中三个区域的分割线,我们也能大致得出最优并发用户数和最大并发用户数,所谓最优并发用户数指的是资源利用充足没有资源的空闲或浪费,而响应时间又很快,不影响用户体验,但是当系统的负载达到最大并发用户数后,响应时间就超过了用户可以忍受的最大限度了。
这是性能测试中一个比较经典的图,只能用来作为参考,现实中的情况并不一定如上图那样,响应时间也并不一定是在塌陷区突然上升,有可能在重负载区已经开始增加。吞吐量和响应时间随着并发用户数的增加,也一定会此消彼长。所谓的性能,其实是负载、吞吐量、可接受的响应时间和资源利用率之间的一种平衡。
我们常说的性能指标,通常可以分为两类:技术指标+业务指标。
例如:
业务指标:系统要支持同时1000万人在线。
技术指标:系统能够支持1万TPS。
技术指标又可以分为:时间指标+容量指标+资源指标。
时间指标简单来说可以是平均响应时间或百分位响应时间。
容量指标指的是单接口的容量。
资源利用率指标指的是
操作系统相关的资源:CPU、IO、Mem、Disk、Network等
JVM相关的资源:Load Average 、GC、FGC次数等
可以看到有非常多种类的技术指标,而所有的技术指标都是通过业务指标换算而来的,换句话说,如何将系统要支持同时1000万人在线的业务指标,转化成系统能够支持1万TPS的技术指标。
首先我们先要搞清楚的是什么是TPS,也就是每秒事务数,它反映了一个系统的处理能力。我们会根据不同的场景来定义TPS的粒度,例如单个接口的性能测试,这个T可以认为是接口级的,而对于整个业务的性能测试,T可以认为是整个完整的业务流,例如:落单、支付都可以看作两个单个接口,而网购可以看作一个完整的业务流,TPS可以看作是每秒处理的业务数,或者每秒处理的某个接口或交易数。
我们假定用二八法则,计算一下刚才的那个例子,假设1000万用户下午1点到3点间会同时在线进行操作,而且按照80%的业务量在20%的时间里完成,按照一定的业务统计发现,这个业务的并发度控制在5%-1%之间。
业务量=1000万个,并发度是5%,时间=2x60x60=7200秒TPS=并发数/响应时间TPS=(5%*业务量*80%)/(20%*时间)=0.05*1000万*0.8/(0.2*7200)=278TPS
二八原则计算的结果并非在线并发用户数,而是系统要达到的处理能力(吞吐量),而且现实中大都数情况并不是例子中的二八原则,需要具体问题具体分析。
如果这整个业务流的响应时间是100ms,那并发线程数是 278TPS/(1000ms/100ms) = 28 个(并发线程)
通常来说,因为引入了缓存队列等机制,一个系统的最大用户数应该远大于并发用户数。
从上述的计算中可以看到,如果想提高系统整体的tps可以从两方面入手:
1)增加并发数
比如增加tomcat并发的线程数
增加数据库的连接数,预建立合适数量的TCP连接数
后端服务支持横向扩容,加机器满足更大流量要求
调用链路上的各个系统和服务尽量不要单点,要从头到尾都是能力对等的,不能让其中某一点成为瓶颈。
RPC调用的尽量使用线程池,预先建立合适的连接数
2)减少响应时间
引入缓存,缩短响应时间
流量消峰,提前返回错误
减少调用链
优化数据库,建立索引
今天的学习就到这里,如果这篇文章对你有所帮助,请点赞和转发哦👍
