




2014年ThoughtWorks首席科学家Martin Fowler与James Lewis共同提出微服务概念到现在已经7年时间了,正是工具美眉大学毕业后的这几年,也是赶上了互联网及互联网+发展的这趟高速列车🚄。
随着互联网业务的快速发展,我们的系统架构也经过一次又一次的架构演进,最终把单一的系统拆分成了一个个更加灵活、有业务边界上下文、松散耦合、可独立部署的微服务,而随着服务数量的越来越多,我们也面临了一系列微服务带来的挑战,电商的一个通用微服务架构模板大概长这样:
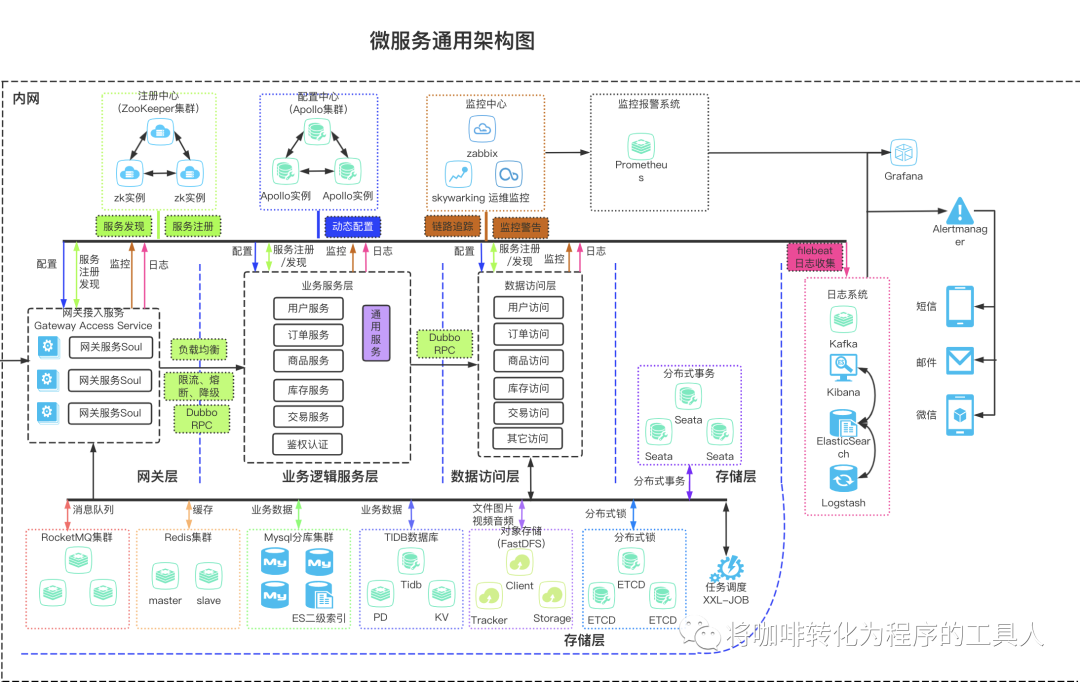
面对复杂的分布式系统,如何来保证系统质量呢?如何保证数据一致性?怎么设计容错?限流如何设计等等一系列问题。
在此弱弱地问一句,我们平时都是怎么去测试的?
一直以来,测试金字塔是敏捷项目中的一个重要的测试守则,我们测试每天日常的工作就是API接口测试,end2end集成测试,UI测试,等等,但是我们测试群体中大部分人还是在做着基于业务逻辑维度的测试。
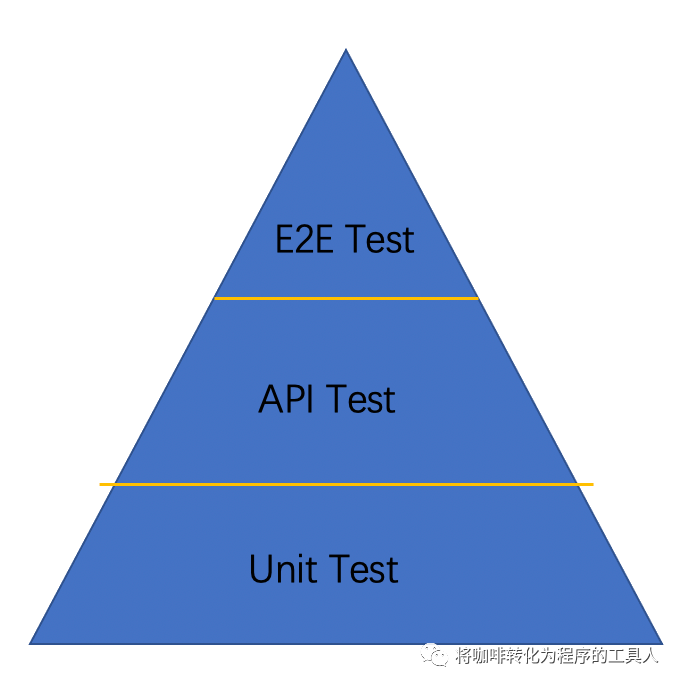
但是我们所测试的微服务,它拥有一系列的特性:负载均衡、容错保护、API服务网关、分布式链路跟踪等等,我们的测试能覆盖到这些特性吗??除此以外,还有面临着真实世界里的一些客观存在的挑战,例如网络延迟、CPU满载、请求异常、依赖故障、硬件故障等场景的模拟。
然鹅,我们只基于业务维度完成测试的系统,只能说是符合业务要求的,但它们其实是并不具备任何容错能力的脆弱系统,我们对投入生产的复杂系统又有多少信心??
一帆风顺的情况下没什么,一旦发生某些不可预知的故障,有可能会引发蝴蝶效应,甚至可以用灾难来形容。现实生活中这样的例子还真不少,某系统短时的流量激增,导致数据库瘫痪,整个服务不可用。某系统消息中间件故障,导致消息堆积,程序漏洞引发千万级别资损。某航空公司由于系统故障,导致千万航班取消等等。每当看到这些故障的案例,如何保证质量让工具美眉这样的测试同学们真心感觉亚历山大,我们还有非常多的事情可以做去避免这种灾难的发生。
一种很好的办法就是“探索系统故障边界,验证系统灾难恢复能力”。微服务架构解决了单点故障的问题,但是引入了更多复杂的问题,我们需要可靠性,弹性更强的系统。我们不妨对我们的系统引入一些随机的破坏,这种破坏是有计划有策略的,通过让系统感染这种破坏,从而发现系统潜在的脆弱,然后改进提高系统对此类破坏的免疫力。
“混沌工程”应运而生。我们可以通过混沌工程的一系列实验,来挖掘系统的弱点。
混沌工程的五大原则
1)建立一个围绕稳定状态行为的假说
你得明确实验前的稳定状态是怎样的,且注入了破坏后,系统的反应应当是怎样的?
稳定的状态主要可以分为:
系统指标(如CPU 负载、内存使用情况、网络 I/O等)
业务指标(用户量,交易量,TPS,QPS等)
2)多样化真实世界的事件
莫非定律告诉我们,越是不想发生的就越会发生,各种系统故障也是,因此,我们需要模拟各种异常,常见的可以分为以下几类:
硬件故障
功能缺陷
状态转换异常(例如发送方和接收方的状态不一致)
网络延迟或隔离
上行或下行输入的大幅波动以及重试风暴
资源耗尽
服务之间的不正常的或者预料之外的组合调用
拜占庭故障
资源竞争条件
下游依赖故障
3)在生产环境中运行实验
为了排除更多的不确定性,即便你不能在生产环境中执行实验,你也要尽可能的在离生产环境最接近的环境中运行。
4)持续自动化运行实验
自动化的方式去运行这些实验是个小目标。
5)最小化爆炸半径
将伤亡控制在最小范围,别选在高峰期进行你的破坏实验,同时选择影响一小部分用户,如果因为这个破坏引发了连锁反应,应当及时终止。
了解了混沌工程的五个原则之后,来简单介绍一款阿里巴巴的混沌测试工具
ChaosBlade。
ChaosBlade,从字面翻译就是混沌之刃,是一款好用的开源的测试工具。
下载chaosblade工具到实验的机器上:
wget https://github.com/chaosblade-io/chaosblade/releases/download/v0.0.3/chaosblade-0.0.3.linux-amd64.tar.gz
解压chaosblade-0.0.3.linux-amd64.tar.gz
tar -xvzf chaosblade-0.0.3.linux-amd64.tar.gz
cli 命令提示使执行混沌实验更加简单。
目前支持的演练场景有操作系统类的 CPU、磁盘、进程、网络,Java 应用类的 Dubbo、MySQL、Servlet 和自定义类方法延迟或抛异常等以及杀容器、杀 Pod,具体可执行 blade create -h 查看:
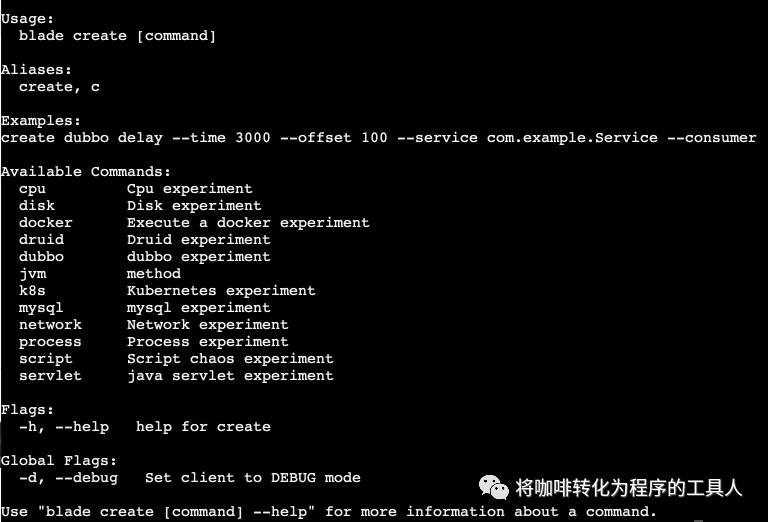
执行blade -h查看:

Cli 包含 create、destroy、status、prepare、revoke、version 6 个命令。
相关混沌实验数据使用 SQLite 存储在本地(chaosblade 目录下)。
Create 和 destroy 命令调用相关的混沌实验执行器创建或者销毁混沌实验。
Prepare 和 revoke 命令调用混沌实验准备执行器准备或者恢复实验环境。
混沌实验和混沌实验环境准备记录都可以通过 status 命令查询。
| 场景 | 原理 | |
| cpu | cpu fullload | 模拟cpu满载,实际调用了/bin/burn_cpu,大量的计算使cpu一直处于繁忙状态。 |
| 内存 | RAM | 存储正在使用的程序和数据,不断使用代码申请内存。 |
| Cache | 高速存储组件,CPU读取RAM前,先读取Cache,通过使用dd命令挂载tmpfs。 | |
| disk | Disk Burn | 使用dd命令实现文件拷贝,通过调整读写的块大小提升 io 负载。 读会固定占用 600M 的空间,因为读操作会先创建一个 600M 的固定大小文件。 |
| network | 网络延迟 | 通过tc netem delay 命令实现 |
| 网络数据包丢失 | 通过tc netem loss 命令实现 | |
| 网络数据包乱序 | 通过tc netem reorder命令实现 | |
| 网络数据包重复 | 通过tc netem duplicate命令实现 | |
| process | 进程杀死 | 通过kill命令实现 |
| 进程假死 | 通过kill -STOP PIDS的命令实现 | |
| 数据库 | 数据库异常 | 基于Jvm-SandBox |
| 数据库无响应 | 通过iptalbes命令实现,可以简单理解为linux下的防火墙,控制网络访问。 | |
| 数据库延迟 | 基于Jvm-SandBox 实现 | |
| Java应用程序 | rpc异常 | 基于Jvm-SandBox实现,是阿里的一种非侵入式运行期 AOP 解决方案,对某些代码进行注入后,编译得到新的class文件,重新加载到jvm方法区。其中,修改字节码和重定义类都要经过 sandbox的Instrument对象 |
| rpc调用超时 | ||
| method超时 | ||
| method异常 | ||
| 指定method返回值 |
实验的过程可以分为四个步骤:
1)环境准备
2)故障注入
3)测试验证
4)环境恢复
我们一起来动手实践一下吧,我们需要在一个查询接口的某个方法模拟抛出指定的异常。
1)环境准备:
./blade prepare jvm --process java
返回一串信息:{"code":200,"success":true,"result":"002f7948c31c7b89”} result是代表这个实验环境的id,后续作实验环境销毁时需要用到。
2)故障注入,在class的某个method注入java exception
./blade create jvm throwCustomException--classname=com.learning.demo.QueryServiceImpl--methodname=queryById--exception java.lang.Exception
返回一串信息:{"code":200,"success":true,"result":"43b9331560a33a98”}
result是代表这个特定故障的id,后续可以根据id指定销毁某一个特定的故障。
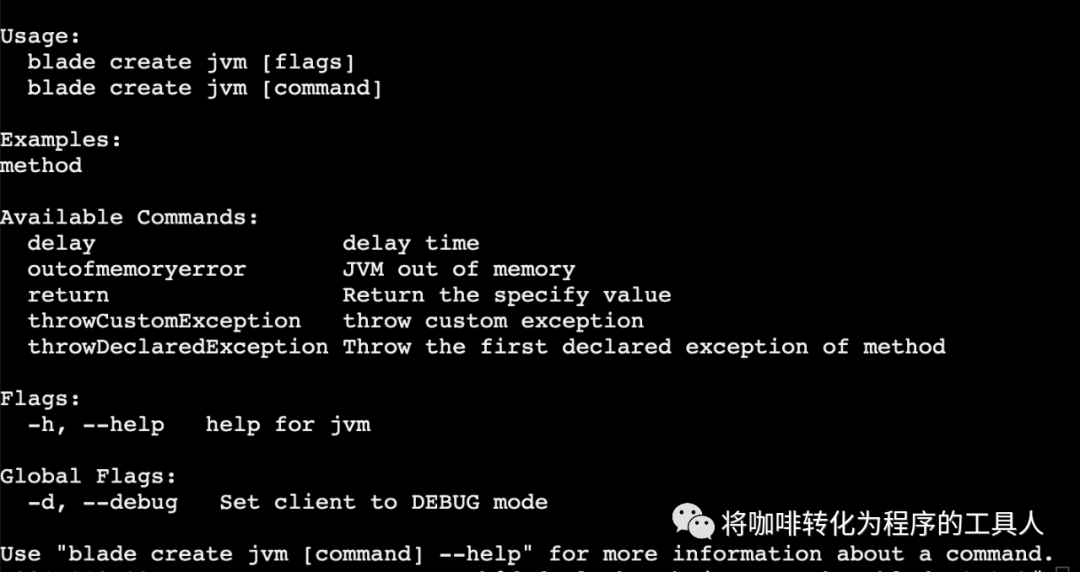
3)测试验证
调用这个query接口,查看日志,程序中不出所料,抛出了一个java.lang.exception chaosblade-mock-exception

4)环境恢复
销毁整个实验环境:./blade revoke 002f7948c31c7b89
销毁单个故障模拟:./blade destroy 43b9331560a33a98
测试完成某个故障就要及时还原,以免影响了其他人。
这是一个非常简单的混沌工程实验的例子,现实中,我们需要模拟非常复杂的一些实验。
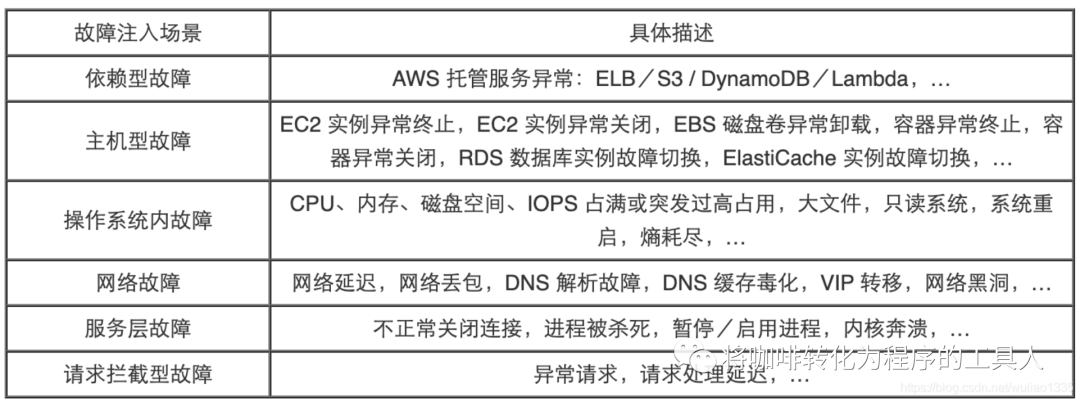
我们可以从以下几个方面探索一下自己所测试的系统:
业务系统的高可用水平如何
例如:CPU耗尽后系统能否自动恢复,我们的系统自动恢复的时长,如果不能自动恢复的话,手工恢复后系统能否正常工作?
例如:系统在遭受一些破坏的情况下,是否有补偿和降级的逻辑,是否会对弱依赖的一些服务,采取FailFast 措施来缓解系统的负载
监控和告警的有效性如何
例如:模拟我们系统中的异常监控是否真正能够有效发现问题,例如一些调用超时的告警,CPU告警,内存,数据库告警等等
异常情况下人工介入时机是否正确
例如:当单节点出现异常时,不管是自动还是手工的方式,系统是否会隔离或下线出问题的服务实例,防止请求路由到此实例,所有 QPS 会有短暂的下跌,是否会很快会恢复
故障定位和故障恢复时间是否达标
模拟演练故障,检测故障是否可以及时发现,定位,对故障恢复的时间进行考核等等
今天的学习就到这里,如果这篇文章对你有帮助,请记得点赞和转发哦👍
