




最近,有位刚出道的年轻人问了工具人一个很残酷的问题:工具人们的未来在哪里?生锈了之后,是去滴滴拉黄包车,还是去美团做小黄哥?
对于这个问题工具人有上中下三策:
下策:买点东方红基金,有了睡后收入,可以温饱无忧。
风险在于,工具人工资太低,买不了多少份额。
中策:找个有“家文化”的公司,发挥发挥余热。
风险在于,在这种公司里,容易遇到钻石不粘锅,还抹了油。
上策:努力提升自己,做好长远的职业规划。
风险在于,也许职业规划,一不小心就成了傀儡养成计划。
于是,为了避免年轻人走弯路,所以工具人分享了自己的职业规划,如有误人子弟,请各位看官不吝赐教~
工具人很幸运,身在一个重视人才储备的公司,为了区区二三十人的开发团队,不计代价,汇聚了一批万中无一的顶级产品经理,并正在招募一堆千里挑一的王者BA,产品+BA与开发人数比近乎达到1:1,作为百无一用的工具人,非常惭愧,自觉还有很长的路要走,才能跟得上这些优秀同伴的脚步。
嘴炮不如实干,空想不如行动!有了职业规划,也得有执行计划,今天我们就从Flink执行计划开始,一步一步向理想进发。
假如我们有如下一段程序:
public class WordCount {public static void main(String[] args) throws Exception {定义socket的端口号int port;try{ParameterTool parameterTool = ParameterTool.fromArgs(args);port = parameterTool.getInt("port");}catch (Exception e){System.err.println("没有指定port参数,使用默认值9090");port = 9090;}获取运行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();连接socket获取输入的数据DataStreamSource<String> text = env.socketTextStream("127.0.0.1", port, "\n");计算数据DataStream<WordWithCount> windowCount = text.flatMap(new FlatMapFunction<String, WordWithCount>() {public void flatMap(String value, Collector<WordWithCount> out) throws Exception {String[] splits = value.split("\\s");for (String word:splits) {out.collect(new WordWithCount(word,1L));}}})//打平操作,把每行的单词转为<word,count>类型的数据.keyBy("word")//针对相同的word数据进行分组.timeWindow(Time.seconds(2),Time.seconds(1))//指定计算数据的窗口大小和滑动窗口大小.sum("count");把数据打印到控制台windowCount.print().setParallelism(1);//使用一个并行度注意:因为flink是懒加载的,所以必须调用execute方法,上面的代码才会执行;}*** 主要为了存储单词以及单词出现的次数*/public static class WordWithCount{public String word;public long count;........}}
然后我们将程序打包,上传至flink
那么问题来了:flink程序是怎么跑起来的?
1,谁执行了程序的main函数?
2,分布式计算调度的最小单元是什么?
带着这两个问题,我们先来了解下flink集群中的几个重要角色:
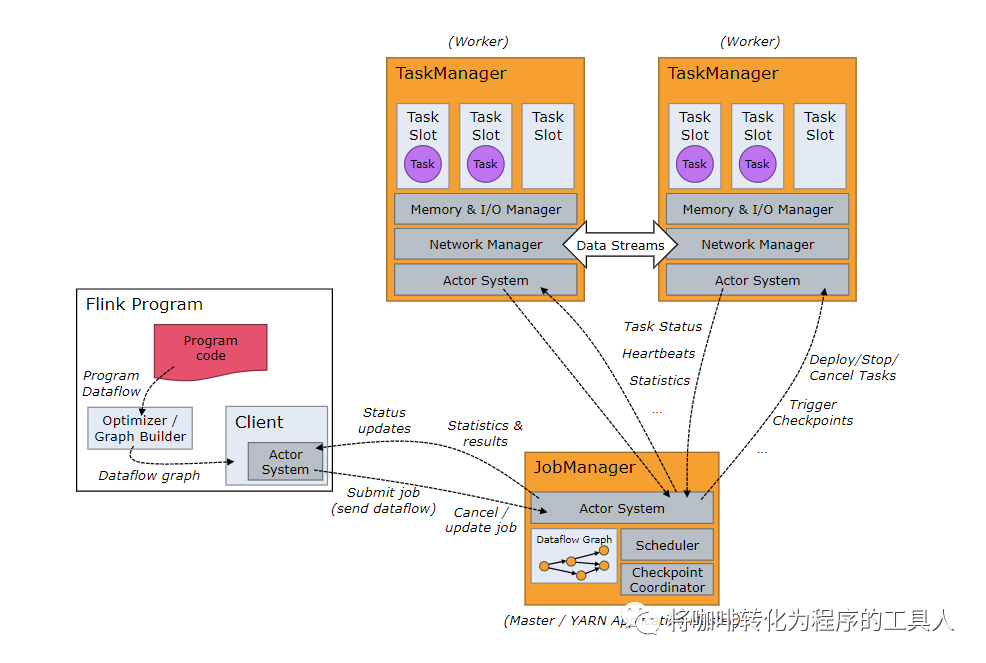
官网的这张图比较老了,不过不影响我们理解这几个重要的角色的职责。图左下角的是JobClient,实际上就是main函数执行者,也是我们本次讨论的重点。他主要负责这几个任务:1,生成执行计划。2,优化执行单元。3,将JobGraph发送到JobManager。图的右下角是JobManager,他是Flink的大脑,即调度中心。图的上方TaskManager,程序逻辑的运行者,也是实际的运行资源。
对于流计算来说,JobClient 在执行时,首先会解析我们的程序,其过程分为如下几步:
一,算子转换
flink程序开始都会创建一个运行环境StreamExecutionEnvironment:
//创建运行时StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
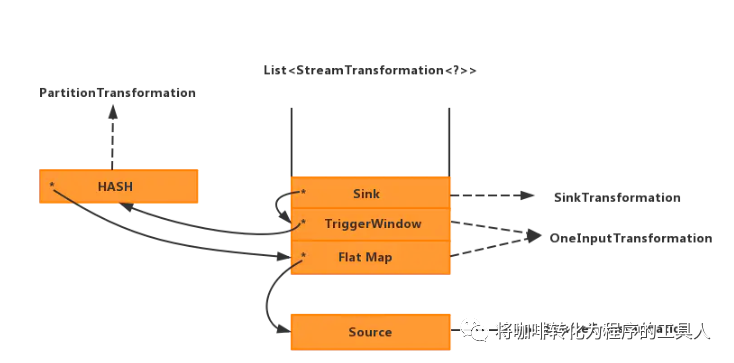
在StreamExecutionEnvironment中有个成员变量transformations,在这里记录了我们所有的算子信息(这里看似是个列表,实际上每个元素都带有父子信息,整体可以理解为一个树)。
protected final List<StreamTransformation<?>> transformations = new ArrayList<>();
对于每一个算子,在加入到transformations列表的过程中,都会做一系列转化,将不同的算子转换为不同的transformation对象,并最终生成算子树。如刚才程序中的flatMap:
text.flatMap(new FlatMapFunction<String, WordWithCount>() {public void flatMap(String value, Collector<WordWithCount> out) throws Exception {String[] splits = value.split("\\s");for (String word:splits) {out.collect(new WordWithCount(word,1L));}}
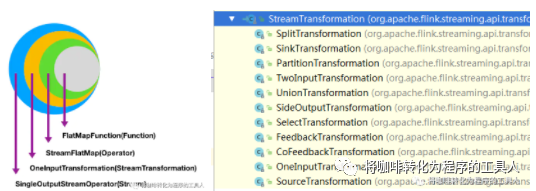
以Flatmap为例,首先,flink会构造Function → Operator的转化,同时初始化chainingStragy,chainingStrategy 类型分为 ALWAYS,HEAD,NEVER,表示该算子是否能被其他算子串连,一般默认是可以串连的(ALWAYS),只有source算子为HEAD,或者手工在程序中强制指定为不可传来(NEVER)
然后,构造当前算子的OneInputTransformation 对象 初始化slot的共享组(slotSharingGroup),算子的并行度(parallelism),以及把当前的transformation作为新的OneInputTransformation 的输入保存(input),以此记录算子的上下游关系。
以OneInputTransformation为例:
private String slotSharingGroup; //表示slot的共享组private int parallelism; //该算子的并行度private final StreamTransformation<IN> input;private final OneInputStreamOperator<IN, OUT> operator;
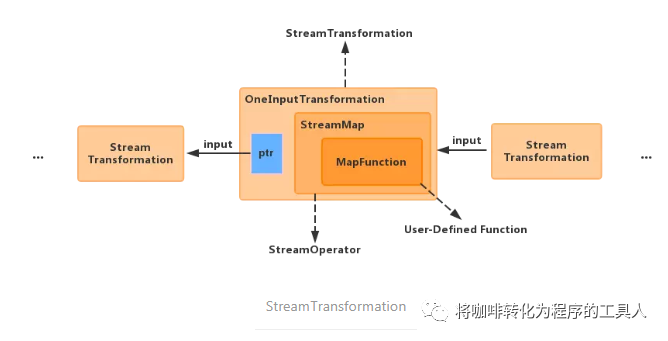
最后,将该transformation加入到transformations队列中。并返回新的stream对象(根据算子进行stream转换)。
最终我们的程序会生成如下的的transforation树,记录了我们所有的算子的连接关系。
二,生成StreamGraph
程序最后的调用:env.execute();Jobclient会遍历env的transformations列表中的所有transformation对象,递归构建DAG(为什么是递归呢?为了保证是从后向前构建的,递归的退出条件是遇到了SourceTransformation)最后构造出StreamGraph对象。

其中,node的概念比较容易理解,一一对应了我们的算子方法。而边的性质代表数据如何下发,不同的算子类型以及并发度,决定了不同的分发策略,比如:当上下游并发度相同时,则为forward,如果不同则为rebalance,特殊算子还有特殊的分发方式,如broadcast。在识别并构造完这些数据结构后,将交给下一步生成JobGraph时,优化执行计划。
三,生成JobGraph
JobGraph是唯一被Flink的数据流引擎所识别的表述作业的数据结构,也正是这一共同的抽象体现了流处理和批处理在运行时的统一。
在建立jobGraph的一开始,会设置jobGraph的ScheduledMode,ScheduledMode分为eager和lazy,流式计算的ScheduledMode被固定设置为了eager。其中,Eager表示所有计算节点将会在开始时立即启动。而Lazy表示上游计算节点计算完成后下游节点再启动。
其核心过程在于递归建立计算节点链,当满足特定条件node会被合并,创建为一个JobVertx,缓存vertx两头的StreamEdge,接着创建JobEdge(分发策略ALL_TO_ALL,还是POINTWISE:一对多Or一对一)与上下游的JobVertx相连,同时创建设置IntermediateDataSet,用来记录输出是否需要背压控制,输出是否需要缓冲区限制。
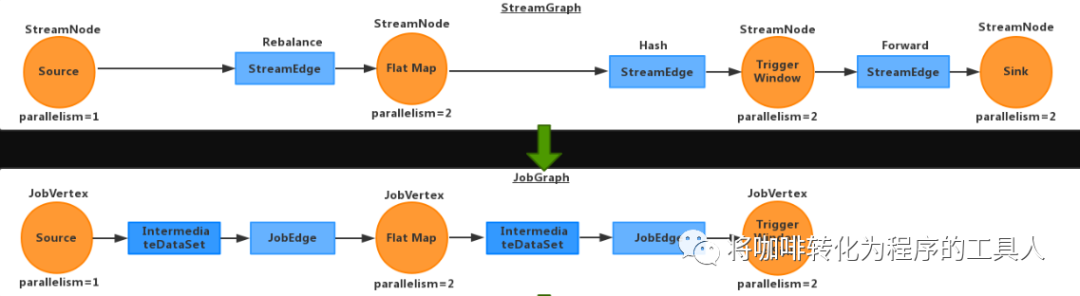
如上图,为什么streamGraph的最后两个节点,能够被合并成了一个JobVertex,而其他节点不行呢?
因为被合并需要满足以下几个重要条件
1.下游的输入边只有一条
2.下游操作operator不为空
3.上游操作operator不为空
4.上游必须有相同的solt组
5.下游chain策略为always
6.上游chain策略为head或上游chain策略为always
7.边的类型为forwardpartition
8.上下游并行度相同
9.用户代码设置的operator是否可以chain
合并之后有什么用处呢?很明显,可以节省flink的计算资源,让合并后的任务可以在同一个节点,同一个线程中执行,减少了io和线程切换等额外开销。
四,上传JobGraph
JobGraph生成完后,会被序列化,并通过HTTP协议发送到JobManager存储起来,JobManager会根据JobGraph生成最终的执行计划ExecutionGraph。关于ExecutionGraph的生成,我们下次再学习。
工具人相信,在这样一群优秀的产品经理和BA的带领下,公司APP产品一定能在短时间内碾压同草顺,小聪明,东方赤贫等各大龙头。
如果工具人们迟钝的意识,
无法体会那些产品,
精简的需求背后多样的场景;
如果工具人们浅薄的学识,
无法领悟那些产品,
抽象的草图背后神秘的哲学;
如果工具人们残破的躯壳,
无法容纳那些产品,
矛盾的设计背后隐忍的自洽;
请大家包容,给工具人们一些时间,学习、提升,努力不成为后腿,不辜负大家的期望!
