




今天,工具人要给大家讲述一个备胎上位的故事。
2019年,公司APP需要提供一些重要的行情市场指标,而这个毫无头绪的任务指派给了工具人。这种无条件的信任,让工具人感受到犹如唐僧对孙悟空的托付:悟空,为师就拜托你了。
在经过几个月的大小战役,工具人终于开荒成功,但是在上线前,公司又花了大价钱采购了"X智慧"的成熟产品。原来,工具人只是那个叫猪八戒的备胎,那种突然降临的失落感,让工具人瞬间理解了那些传说:曾经的勇士,为何明知要背负骂名,也要与旧爱同归于尽,删库跑路了。还好,工具人十年饮冰,热血难凉,安慰自己,是金子总有发光的一刻。
果其不然,供应商有智慧没质量,频频拉垮。而备胎工具人,默默守护,爱的供养。终于在某天从备胎转正,成功替代了X智慧,一步上位。而这一切,都得归功于Flink的容错机制。
由于行情指标的计算往往依赖于一些中间状态,当程序出现异常情况后,我们需要回放部分行情,重新计算出正确的指标,而这个前提是这些中间状态的正确恢复。
Flink的容错机制是基于一致性检查点(checkPoint)之上的,每个checkPoint中都会保留这些不同算子,在同一时刻中的状态。这些同一时刻的状态会被最终写入到HDFS中(上期内容可以参考:「Flink」工具人之行情分时线与状态管理)。如下图所示:
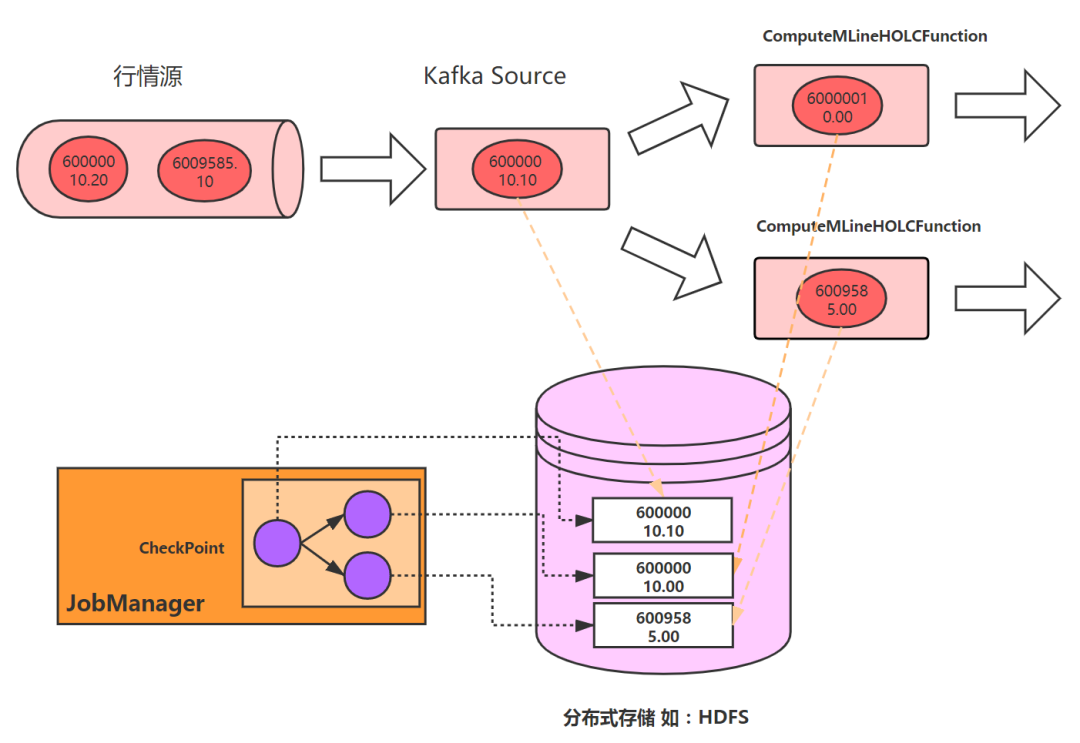
那么Flink是如何保证分布在不同算子中的状态在同一时刻保存的呢?注意,这里的“同一时刻”,并不是指在同一个时间点触发保存的动作,而是指:保存的数据属于同一个时刻。Flink使用了基于Chandy-Lamport的分布式快照算法,将检查点的保存和数据处理分开,从而使得检查点保存不会暂定这个应用的流式处理。这种算法的核心思想是:由JobManager发起,将一种叫检查点屏障(checkpoint barrier)的特殊数据,插入到一条实时流中,当每个算子接受到该屏障时,即保存为同一时刻的数据快照,保存成功后,通知JobManager,然后继续处理下一份数据。所以该屏障到来之前的所有数据引起状态变更,都会被保留在该检查点中,而该屏障到来之后的数据引起的状态变更,则会被保留在下一个检查点中。当JobManager收齐所有的保存成功后的快照后,该检查点(checkpoint)完成。
假设我们有两个数据源:上海交易所和深圳交易所;4个不同颜色的圆圈代表4个不同的股票,我们在分时计算算子中计算他们的最高价,并且算子的并发度为2。下图的时刻,两个行情源的状态中分别保存了当前的KAFKA的Offset;子任务1的状态中保存了两只股票的最高价5.9和4.2;子任务2中保存了一只股票的最高价5.3,并且最高价的计算结果正被传送到Sink节点。
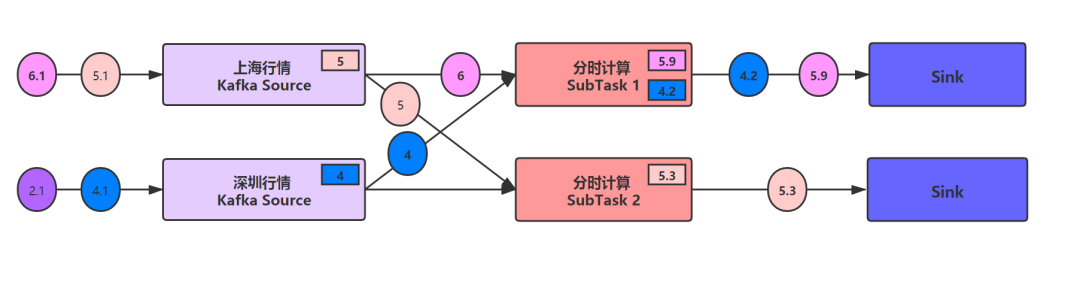
此时,JobManager启动了检查点快照,它会向每一个source发送一个带有ID的消息,如下图绿色小三角,此时,整个流计算是不受干扰的正常运行着(粉色5.9的计算结果已经流入到Sink中)
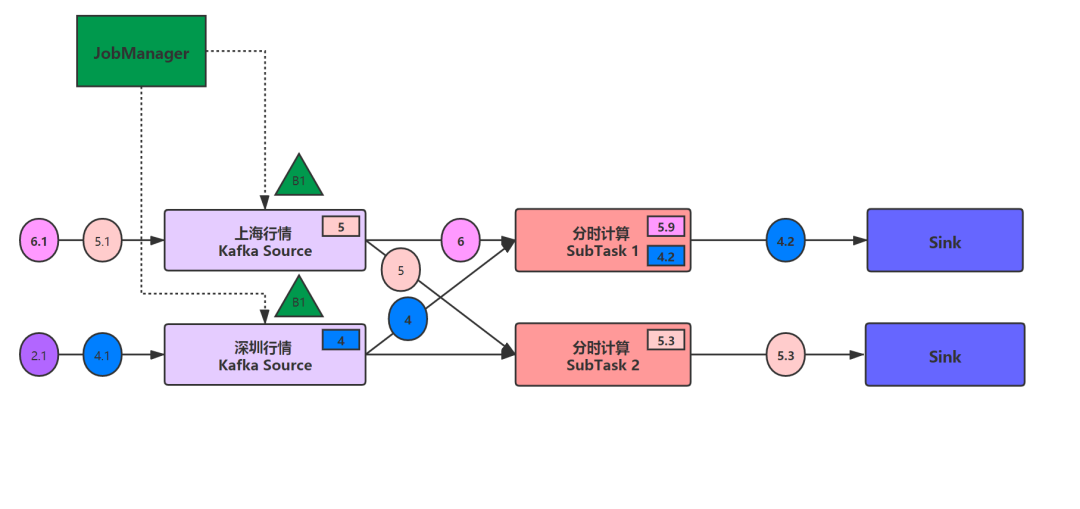
当Kafka Source收到了检查点消息时,会将检查点屏障对每个Edge向后传递。同时将本地的状态写入检查点,在状态后端确认写入成功后,则会通知source任务,source任务向JobManager确认检查点写入完成。
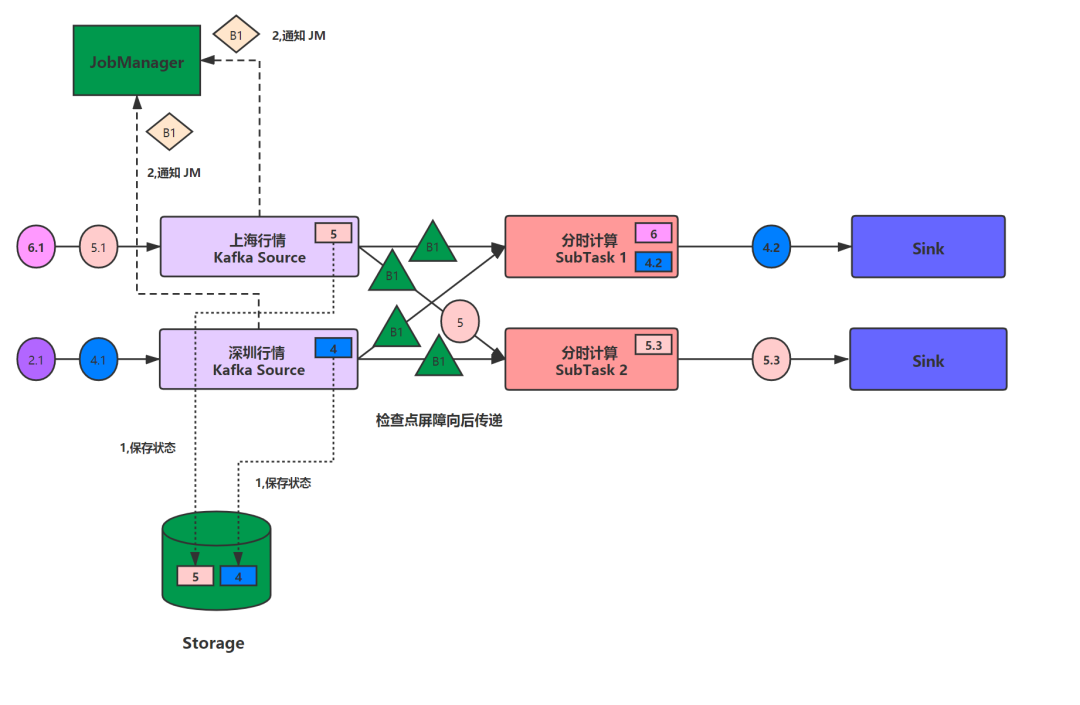
由于下游的分时计算的每个子任务,有多条输入,所以每个子任务会等待所有的检查点屏障到期后,再将数据同步到状态后端。当检查点屏障未到齐时,已经到达的检查屏障的分区,其后的数据将会被缓存,这个就是Flink中的检查点对齐概念。如下图所示:当SubTask2收到了一个检查点屏障,之后紫色的股票数据都会被缓存,直到另一个绿色的屏障到达,做完检查点快照,缓存数据才会被向后发送。而SubTask1已经收齐了2个检查点屏障,所以符合向状态后端同步检查点快照数据的条件。
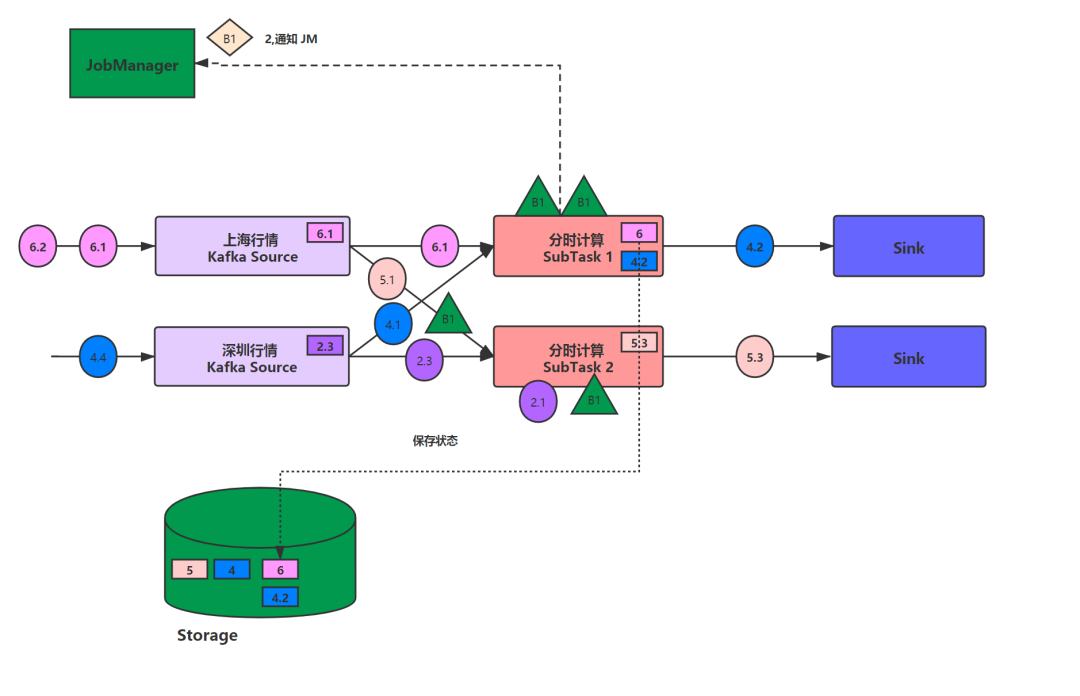
当SubTask1完成了检查点落地并通知JobManager后,就会向Sink传递检查点屏障。而当SubTask2将检查点对齐后,也同样会像SubTask1一样,向Sink传递检查点屏障。Sink算子收到检查点屏障后,也会完成相同的步骤。
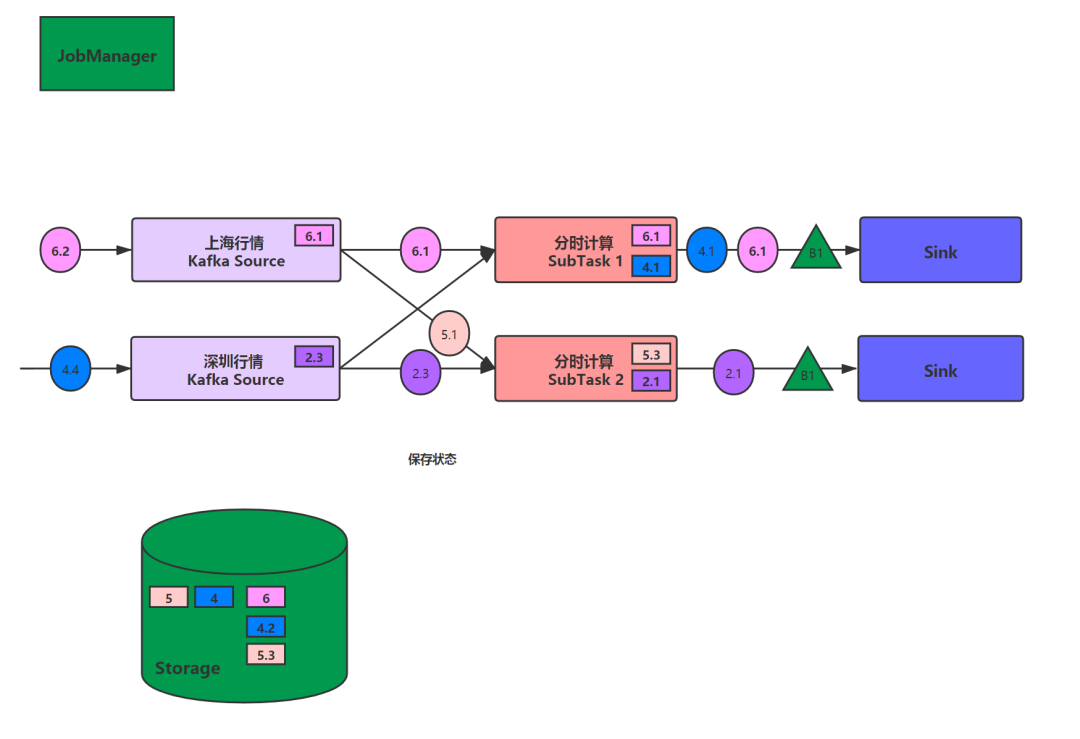
由于行情计算的特殊性,各个计算功能也会有互相依赖,比如个股资金流输出到Kafka的结果,会是板块资金流的输入依赖。所以我们不仅仅要保证的是Flink中计算的精确一次(Exactly-Once),对外部使用者也有一定的要求。所以kafka生产者需要开启事务,消费者需要设置隔离级别为read_committed。
所以,这个故事告诉我们:花钱买来的感情也许一时新鲜,但永远不如青梅竹马来的真挚;花钱买来的系统,可能一时亮眼,但永远不如自主研发来的可靠。也许,采购买办能在短期带来奖项,带来荣誉;但产品的远期发展,还是需要兢兢业业的工具人们,默默地积累和辛勤地付出。最后,为不断奋战在第一线的工具人们打CALL。
