




测试一个接口,很重要的一个环节就是准备接口的请求参数,比较理想的一种方式是测试数据和测试方法解耦。
试想一下下面这种场景, 一个被测接口devide需要使用三套数据测试这个方法是否正确
def devide(x,y):return x/ydef test_divide_1():divide(1,0)def test_divide_2():divide(1,2)def test_divide_3():divide(4,3)
你可能需要实现3个test方法,分别用三套不同的测试数据运行三次,这会造成大量的冗余代码。
有没有什么更加优美的方式,可以完成这个test case的参数化工作,并执行多次。@pytest.mark.parametrize()这个装饰器就是来帮你完成这件事情的。
我们还是用一串问题去开始今天的学习。
1)如何用多套测试数据分别运行同一个testcase?
def devide_function(x, y):return x y@pytest.mark.parametrize("x,y,expected",[(4, 2, 2),(3, 1, 3),(2, 2, 4)])def test_eval(x, y, expected):assert devide_function(x, y) == expected
可以看到@pytest.mark.parametrize()这个注解提供了两个参数,第一个参数代表被注解的方法的入参名,第二个参数代表的是数据集合,集合里的每个元素是一个tuple,tuple里的每个值分别对应了被注解的方法的三个入参。
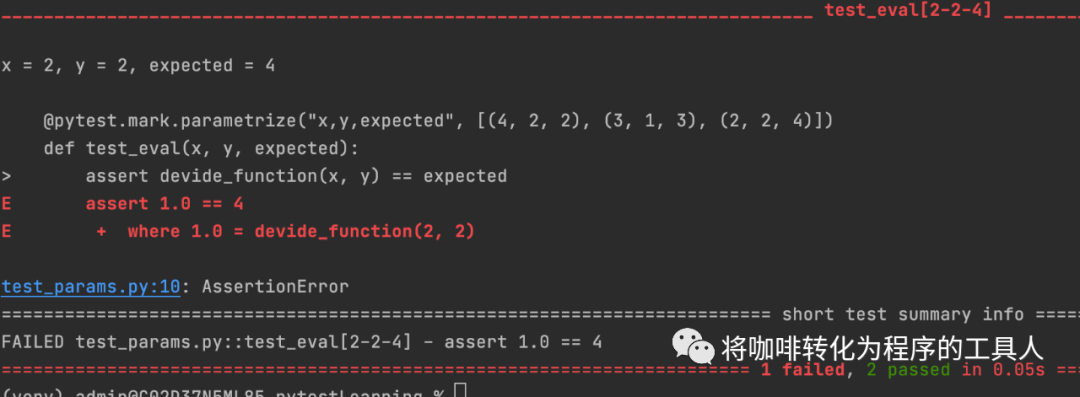
一共运行了3个case,有2个成功,1个失败了。
2)如何指定多套数据中某套参数的执行结果是失败的?
@pytest.mark.parametrize("x,y,expected",[(4, 2, 2),(3, 1, 3),pytest.param(2, 2, 4, marks=pytest.mark.xfail)])def test_divide(x, y, expected):assert devide_function(x, y) == expected
期望(2, 2, 4)的执行结果是失败的,则通过pytest.param(2, 2, 4, marks=pytest.mark.xfail)来实现。
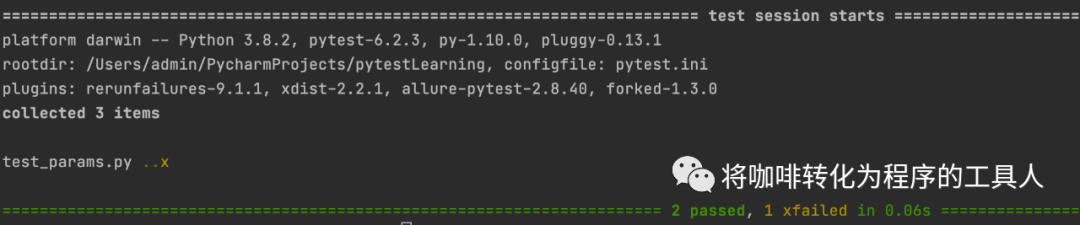
3)如何对多个参数之间进行组合?
例如:x=[2,3] y=[1,4] 则参数就有4种组合情况:(2,1) (2,4) (3,1) (3,4)
可以通过如下的方式:
import pytest@pytest.mark.parametrize("x", [0, 1])@pytest.mark.parametrize("y", [2, 3])def test_add(x, y):pass
则会执行4次test_add方法,入参分别是(2,1) (2,4) (3,1) (3,4)。
4)怎么通过命令行的方式给test_case传参?
可以在conftest.py中定义一个命令行参数--stringinput
def pytest_addoption(parser):parser.addoption("--stringinput",action="append",default=[],help="list of stringinputs to pass to test functions",)def pytest_generate_tests(metafunc):if "stringinput" in metafunc.fixturenames:metafunc.parametrize("stringinput", metafunc.config.getoption("stringinput"))
pytest_generate_tests()是一个钩子函数,pytest在测试用例参数化前就调用此钩子函数,根据测试配置或定义测试函数的类或模块中指定的参数值生成测试用例。通过钩子的metafunc的对象,你可以拿到当前这个test case方法的所有参数,如果参数里含有stringinput,则通过metafunc.parametrize()的方式,给这个test case方法动态地注入参数。
5)如何将测试数据按照测试场景做个分类?
例如,test_devide方法有三套测试数据,每套测试数据属于不同的场景,通过分类的方式,可以只执行其中的某套测试数据。
scenario1 = ("场景1", {"x": 4, "y": 2, "expected": 2})scenario2 = ("场景2", {"x": 3, "y": 1, "expected": 3})class TestWithScenarios:scenarios = [scenario1, scenario2]def test_divide(self, x, y, expected):assert divide_function(x, y) == expected
可以定义这个测试类的某个测试方法使用的是哪些场景的测试数据。如何在执行测试方法前,动态将测试场景的参数注入到测试方法中,可以通过
pytest_generate_tests()这个钩子函数和metafunc.parametrize()方法动态地给测试用例参数化。
#conftest.pydef pytest_generate_tests(metafunc):idlist = []argvalues = []for scenario in metafunc.cls.scenarios: #获取测试类的所有场景idlist.append(scenario[0]) #场景名items = scenario[1].items() #场景的测试数据argnames = [x[0] for x in items] #测试数据的keyargvalues.append([x[1] for x in items]) #测试数据的valuemetafunc.parametrize(argnames, argvalues, ids=idlist, scope="class")
6)如何对测试数据进行二次处理?例如:我们只想在测试用例的测试数据中,传入db代表数据库连接对象。如何把测试用例和环境数据之间进行解耦?
#test_db.pydef test_db_initialized(db):print(db.__class__.__name__)pass
在test_case中只传入一个db的对象,不需要关心任何db的连接信息。
#conftest.pydef pytest_generate_tests(metafunc):if "db" in metafunc.fixturenames:metafunc.parametrize("db", ["d1", "d2"], indirect=False)class DB1:"one database object"class DB2:"alternative database object"@pytest.fixturedef db(request):if request.param == "d1":return DB1()elif request.param == "d2":return DB2()else:raise ValueError("invalid internal test config")
在conftest.py中,实现pytest_generate_tests()这个钩子函数,对参数中有db的测试用例,进行参数化的操作。将[d1,d2]两个字符串对db进行参数化。indirect =True时,db会被当作一个方法,而d1, d2会 被传入fixture db方法去执行,返回的结果,会作为参数最终传给testcase。当indirect = False时,db会被当作一个普通参数,d1 和 d2 会被当作字符串传给testcase。
当 indirect = True时,执行结果:

当indirect = False时,执行结果:

今天的学习就到这里,如果这篇文章对你有帮助,请点赞和转发哦👍
