





这是Bella酱的第 151 期分享
你好呀,我是Bella酱~
一个主要写Java和SQL的妹子,这周工作中呢,我想要做一个功能(嗯,做什么功能自己定),这个功能呢,主要是对某些数据指标稽核,以监测这些指标的值是否正确,即监控数据质量。
背景
这些指标是我在MaxCompute中写SQL生成的(嗯,我监控我自己),而且这些指标是以JSON的形式全部存放在了一个字段中。为什么不是一个指标一列来存放数据,而是所有指标全部放在一个字段中呢?一是因为指标种类太多了,几十种;二是因为指标的种类不是固定的,是可以根据配置动态生成的,即有哪些指标,是不固定的,如果以列的形式存放的话,要能够动态生成列才行。接触过MongoDB的同学都知道,它是以document的结构来存放数据的,用document来存放数据的一个很重要的优势就是列不固定,你往document中扔什么,它就存放什么,相比固定列来说,更灵活。所以考虑到我的数据指标的特性,我当初就把我动态生成的所有指标全部都扔在了一个字段中,考虑到Java读取指标的便捷性,我又把所有指标以及它的值序列化成了JSON的格式。
所有指标以JSON的形式放在一个字段中(假设这个字段叫index_value),爽!确实很爽!
但是对于今日的我来说,不太爽,而且是太不爽了,为什么呢?因为我要把这些指标反序列,然后再对它们进行各种数学运算。
方案确定
好了,了解完背景,我们回到数据指标稽核这个功能上,考虑这个功能实现细节时的我,第一反应是写一个UDF,让MaxCompute SQL调用UDF。UDF的入参设置为index_value(即存放所有指标的那个字段),出参设置为反序列化后,经过各种数学运算的结果值。嗯,想到这个方案时,我的嘴角不自觉上扬,这个实现嘛,很简单,就是Java的反序列化和普通的逻辑计算,这个谁还不会嘛。但是,很快,脑海中出现了一个小人,她告诉我,“为什么不看看SQL能不能解决这个问题呢?为什么又要SQL中调用UDF呢,为什么不搞点新东西呢?跳出舒适区吧。”
听从了小人儿的想法,我开始了SQL反序列化Json字符串的探索之旅。果然,功夫不负有心人,I get it!现在呢,我的功能已经实现并且发布好啦,我们来一起看看MaxCompute SQL如何操作JSON字符串吧!
生成JSON数据
我们先来看下如何生成JSON数据,包含利用MaxCompute官方提供的函数和UDF 2种方式。
MaxCompute官方提供了 TO_JSON 函数来生成JSON格式的字符串,但是这个函数可以支持的场景非常有限。我们先来看下它的命令格式:
to_json(expr)
其中expr为必填项,且仅支持3种格式:MAP、ARRAY、STRUCT类型。
我们来看几个例子。
map类型
1.要求key-value对必须同时存在,否则运行时将报错
2.生成的JSON数据中的key和map中的key完全一样,不会自动转换大小写
3.value为null值的key-value对,仍然会正常输出
SELECT to_json(map('Bella酱_map',100,'MySQL',100,'Java',99,'Redis',98,'geography',60, 'Flink', CAST(NULL AS STRING )));

STRUCT类型
1.要求key-value对必须同时存在,否则运行时将报错
2.生成的JSON数据中的key全部为小写
3.value为null值的key-value对,不会输出,自动过滤掉了
SELECT to_json(NAMED_STRUCT('Bella酱_named_struct', 100, 'ES', 99, 'HBase', 98, 'Java', CAST(null AS STRING)));

array类型
1.生成JSON Array格式的数据
SELECT to_json(ARRAY(map('Bella酱_array_map_1', 100, 'ES', 90, 'Java', 60), map('Bella酱_array_map_2', 90, 'C', 80)));

UDF
除了上述3种方式,MaxCompute也提供了UDF的方式来生成JSON,我就是采用这种方式生成的,因为我要多行转一列,然后这一列的数据格式为JSON。
-- 1.建表
DROP TABLE IF EXISTS student_score ;
CREATE TABLE IF NOT EXISTS student_score
(
id BIGINT COMMENT 'id,逻辑主键'
,student_no BIGINT COMMENT '学号'
,student_name STRING COMMENT '姓名'
,suject STRING COMMENT '科目'
,score BIGINT COMMENT '成绩'
)
;
-- 2.插入数据
INSERT OVERWRITE TABLE student_score VALUES
(1, 2021073101, 'Bella酱', 'MySQL', 100),
(2, 2021073101, 'Bella酱', 'Java', 99),
(3, 2021073101, 'Bella酱', 'Redis', 98),
(4, 2021073101, 'Bella酱', 'HBase', 97),
(5, 2021073101, 'Bella酱', 'geography', 60),
(6, 2021073102, '特拉法尔加·罗', 'MySQL', 100),
(7, 2021073102, '特拉法尔加·罗', 'Java', 100),
(8, 2021073102, '特拉法尔加·罗', 'Redis', 100),
(9, 2021073102, '特拉法尔加·罗', 'HBase', 100),
(10, 2021073102, '特拉法尔加·罗', 'geography', 100),
(11, 2021073103, '索隆', 'MySQL', 95),
(12, 2021073103, '索隆', 'Java', 94),
(13, 2021073103, '索隆', 'Redis', 93),
(14, 2021073103, '索隆', 'HBase', 98),
(15, 2021073103, '索隆', 'geography', 20) ;
-- 3.按学生维度来存放数据,所有科目的成绩以json的形式存放在一个字段中
DROP TABLE IF EXISTS student_score_json;
CREATE TABLE IF NOT EXISTS student_score_json AS
SELECT MAX(id) AS id
,student_no
,MAX(student_name) AS student_name
,GENERATEJSONSTRING(
WM_CONCAT(',',suject_score)
,','
,'='
) AS suject_score
FROM (
SELECT id
,student_no
,student_name
,suject
,score
,CONCAT_WS('=', suject, score) AS suject_score
FROM student_score
) a
GROUP BY student_no
;
其中UDF代码如下:
import com.aliyun.odps.udf.UDF;
import com.google.gson.Gson;
import org.apache.commons.lang3.StringUtils;
import java.util.HashMap;
import java.util.Map;
import java.util.Objects;
/**
* 生成JSON格式字符串
*
* @author Bella酱
* @date 2021/08/01
*/
public class GenerateJsonString extends UDF {
public String evaluate(String source, String delimiter, String joiner) {
Map<String, String> map = transferStr2Map(source, delimiter, joiner);
return new Gson().toJson(map);
}
/**
* @param source 数据源
* @param delimiter 分隔符
* @param joiner 连接符
* @return
*/
private static Map<String, String> transferStr2Map(String source, String delimiter, String joiner) {
Map<String, String> map = new HashMap<>(128);
if (StringUtils.isBlank(source)) {
return map;
}
String[] sourceArray = source.split(delimiter);
for (String item : sourceArray) {
String[] itemArray = item.split(joiner);
if (Objects.isNull(itemArray) || itemArray.length == 0) {
break;
}
map.put(itemArray[0], itemArray[1]);
}
return map;
}
}
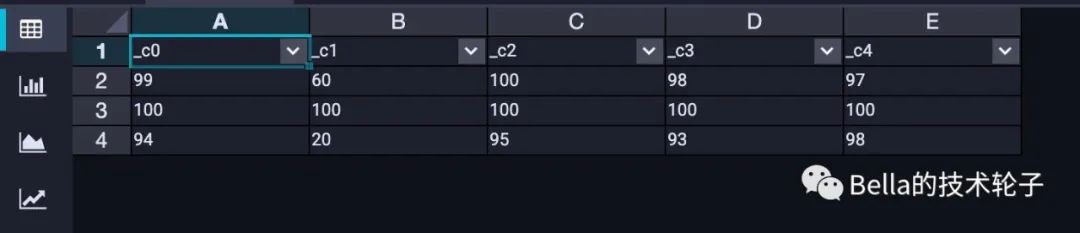
最终生成的 student_score_json 表中数据如下:

可以看到subject_score字段即JSON格式数据。
好了,了解完MaxCompute SQL生成JSON格式数据的4种方式后,接下来呢,我们将以 student_score_json 表为例,来讲解MaxCompute SQL如何解析JSON格式数据。
解析JSON数据生成多列
MaxCompute SQL提供了2种解析JSON字符串的函数,分别是GET_JSON_OBJECT和JSON_TUPLE。
GET_JSON_OBJECT
我们先来看下GET_JSON_OBJECT,命令格式如下:
string get_json_object(string json, string path)
从命令格式可以看出,我们每一次调用get_json_object函数只能从JSON字符串中提取出一个字段,若JSON串中有N个字段,那我们则要调用N次get_json_object,同样,读取了JSON字符串N次。在海量数据的情况下(MaxCompute又偏偏是处理海量数据的),这种行为是非常糟糕的,会将整个数据处理放大N倍,是可能会影响到性能的。
这里需要注意一点,path要以$
开头,表示根节点,.
表示子节点,读取suject_core中的Java字段的值则应该写为$.Java
。
代码和执行效果如下,当某个path对应的值不存在时,get_json_object函数返回值为null。
SELECT id
,student_no
,student_name
,GET_JSON_OBJECT(s.suject_core, "$.Java") AS Java
,GET_JSON_OBJECT(s.suject_core, "$.geography") AS geography
,GET_JSON_OBJECT(s.suject_core, "$.MySQL") AS MySQL
,GET_JSON_OBJECT(s.suject_core, "$.Redis") AS Redis
,GET_JSON_OBJECT(s.suject_core, "$.HBase") AS HBase
FROM student_score_json s
;

如果要读取JSON Array数组呢?当然也是可以的啦。
1.数据key[*]
即可读取数组中所有数据
2.数组key[数组下标]
即可读取数组相应下标中存放的JSON字符串,若要进一步读取JSON字符串中的值,数组key[数组下标].字段key
即可。
我们一起来看个栗子吧。首先是数据准备。
DROP TABLE IF EXISTS tmp_score_array_demo ;
CREATE TABLE IF NOT EXISTS tmp_score_array_demo
(
score_array STRING COMMENT '成绩json数组'
)
;
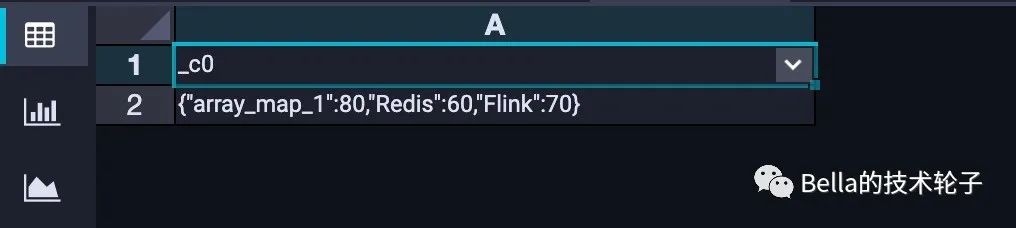
INSERT OVERWRITE TABLE tmp_score_array_demo
VALUES (to_json(MAP('scores', ARRAY(MAP('array_map_1', 80, 'Flink', 70, 'Redis', 60),
MAP('array_map_2', 90, 'ES', 70, 'Redis', 60))))) ;
上述脚本准备好的数据是这个样子的。

1)读取scores数组的值。
SELECT GET_JSON_OBJECT(tmp_score_array_demo.score_array, '$.scores[*]')
FROM tmp_score_array_demo
;

读取scores数组中第一个元素的值。
SELECT GET_JSON_OBJECT(tmp_score_array_demo.score_array, '$.scores[0]')
FROM tmp_score_array_demo
;

读取scores数组中第一个元素中key为Flink的值
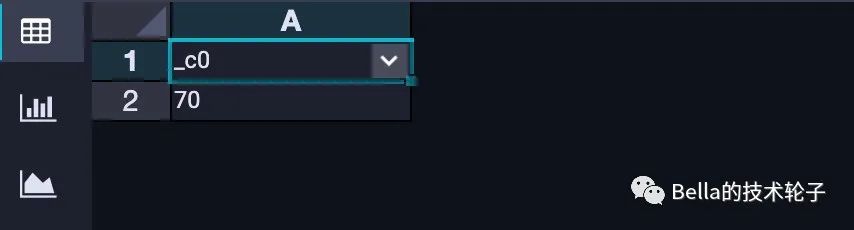
SELECT GET_JSON_OBJECT(tmp_score_array_demo.score_array, '$.scores[0].Flink')
FROM tmp_score_array_demo
;
JSON_TUPLE
我们再来看下JSON_TUPLE,命令格式如下:
string json_tuple(string json, string key1, string key2, string key3...)
从命令格式可以看出,即使我们要读取JSON中多个key的值,也只需要读取一次JSON数据就好了。这,不就是我一直在寻找的吗,激动的我赶快试了下。
SELECT JSON_TUPLE(
student_score_json.suject_score
,"Java"
,"geography"
,"MySQL"
,"Redis"
,"HBase"
)
FROM student_score_json
;
好用,确实是非常好用,但是有2个问题。
1.只有成绩,没有学生信息,我无法知道2者的对应关系。
2.列名都丢失了,无法知道每一列是哪个科目的成绩。
莫慌~MaxCompute还提供了LATERAL VIEW的功能,我们可以配合LATERAL VIEW一起食用,完美解决了上述2个问题。
SELECT s.id AS id
,s.student_no AS student_no
,s.student_name AS student_name
,a.Java AS Java
,a.geography AS geography
,a.MySQL AS MySQL
,a.Redis AS Redis
,a.HBase AS HBase
FROM student_score_json s
LATERAL VIEW JSON_TUPLE(s.suject_score, "Java","geography","MySQL","Redis","HBase") a AS Java, geography, MySQL, Redis, HBase
;

至此,我想要的效果出来啦!
再配合nvl函数,将上述的a.Java
之类的都改为nvl(a.Java, 0)
(如果json中不存在key对应的值,则取默认值0),后面就可以随心所欲的对这些列进行数据运算了。
如果要读取JSON Array数组呢?当然也是可以的啦。我们还以上文中的tmp_score_array_demo表为例。表中数据如下:
1. 读取scores数组的值
SELECT json_tuple(tmp_score_array_demo.score_array, "scores[*]") FROM tmp_score_array_demo;

读取scores数组中第一个元素的值
SELECT json_tuple(tmp_score_array_demo.score_array, "scores[0]") FROM tmp_score_array_demo;
读取scores数组中第一个元素中key为Flink的值
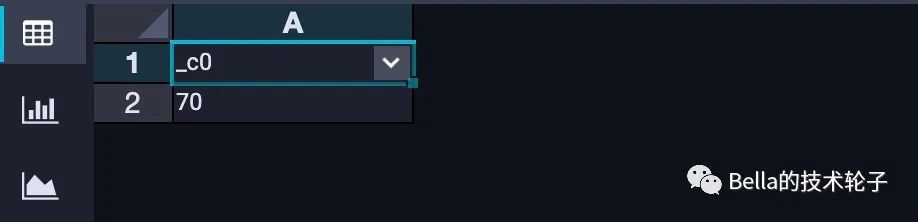
SELECT json_tuple(tmp_score_array_demo.score_array, "scores[0].Flink")
FROM tmp_score_array_demo
;
好啦,通过上述13个实验,我们已经把如何生成JSON数据,如何解析JSON数据、JSON Array数据等讲解完了。
我们今天的文章就到这里啦,下期见~
-END-
更多精彩文章
1.业务团队如何在日常工作中做稳定性?涵盖事前、事中、事后的方方面面 | 原创
2.花97分钟开导了在京东迷茫的学弟,你经历过这种迷茫吗?| 原创
5. 漫说数据湖——如何建湖?如何做数据ETL?为什么大数据需要数据湖?
更多系列文章请查看公众号底部菜单栏【系列文章】,快捷获取Java后端、计算机基础、系统架构、大数据、面试等系列文章~
如果你喜欢本文
请长按二维码,关注 Bella的技术轮子

转发至 朋友圈,是对我最大的支持
喜欢就点个在看吧
