




Redis版本:5.0.2
机器两台:2核8G aws m5.large
部署日期:2019-08-16
老项目一直在使用AWS的ElastiCache的Redis集群服务,为什么突然要自己部署集群呢。理由只有一个,贵了。对的,使用AWS的Redis集群服务,每个月要300$以上的费用,这成本是高了些,并且现在这个平台的并发量不高,缓存的数据量也只有1G多,确实贵了。
你可能会想,自己部署一个集群需要机器吧,要保证服务可用,至少两台机器吧,避免单点故障。那两台机器的价格是多少,会比使用AWS的Redis集群服务便宜吗。因为Redis的单线程特点,我在机器的配置选择上,会选择缓存型的EC2。同时还需要考虑到网络性能,虽然缓存的数据不多,但读写非常频繁,特别是并发高的服务,所以选择了两台2核8G的m5.large的机器。
来算一下价格对比:
首先是使用AWS的Redis集群服务
配置表,当然选择的配置是cache.r4.large
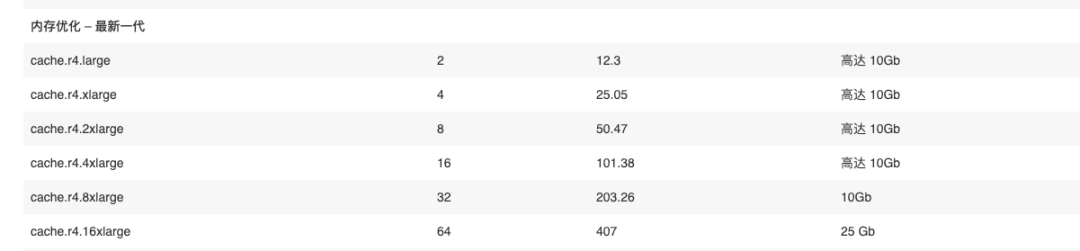
对应价格表,主从共两个节点,每个月328美元。

再来算下自己搭建集群选择两台机器的费用(预留实例)。大概124美元。
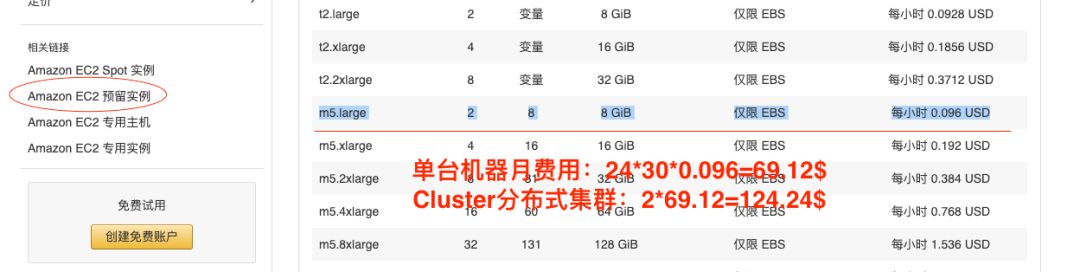
是的,算下来省了差不多2/3的费用。其实AWS的Redis集群服务也有预留实例类型的,价格大约每月96$,比自己搭建更省,但这其中还有种种原因,就不说了。
这个项目有别的公司也在使用我们的代码,所以就有了不同平台的概念。这个集群就是为别的平台搭建的,并不是每个平台都需要这样搞,而且每个平台的服务并发量也不同,比如我们公司自己的平台每分钟有几万并发请求,而今天说的这个平台,每分钟只有几千并发量。
最多只能选择两台机器,而且项目缓存的数据量也没到需要分布式集群的量级,为何不搭建一主一从加哨兵模式的集群,跟购买的Redis服务一样,这就不需要修改任务代码了。
只是考虑到后期添加节点的问题,突然哪天数据量就上去了,并发了量也上去了,这也说不定。Cluster分布式集群模式动态添加节点相比其它方案还是简单的,再者,Cluster可以分solt(槽),这有什么好处?我记得去年写过一篇关于单机为何还要部署伪集群的文章,只是后来某些原因我删除了。
来回顾一下,这也是我在面试中喜欢问面试者的一个问题。单机部署伪集群可以利用多核CPU的优势,因为Redis的单线程特性。同时因为Cluster模式支持分Solt,不同的key可能落到不同的Solt,即不同的Redis主从节点(一个小集群),这样就可以提升并发的访问性能。
Redis一共有16384个Solt,最大支持拥有16384个主节点的小集群,但官方的介绍是最大支持1000个主节点的集群,超过这个数量的Redis集群在性能就发挥不出它的优势了。
Redis Cluster
将所有数据划分为 16384 的 slots(槽位),每个主节点负责其中一部分槽位。槽位的信息存储于每个主节点中。当Redis Cluster的客户端来连接集群时,它也会得到一份集群的槽位配置信息并将其缓存在客户端本地,Jedis封装了这部分的实现。当客户端查找某个 key 时,可以直接定位到目标节点。同时,因为槽位的信息可能会存在客户端与服务器不一致的情况,还需要纠正机制来实现槽位信息的校验调整。
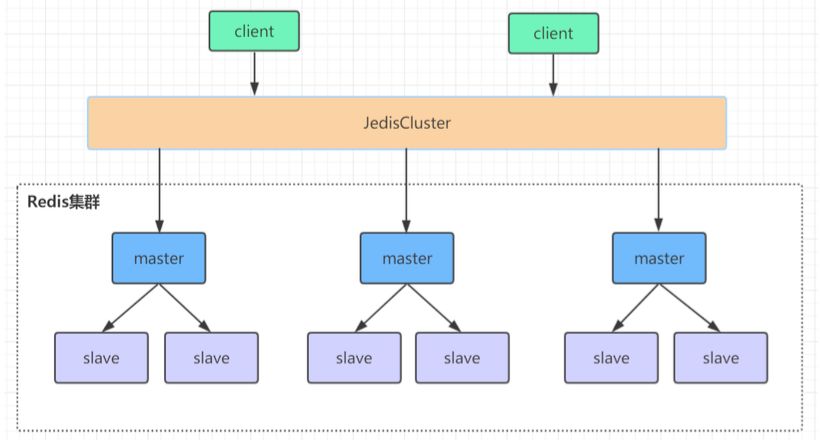
槽位定位算法
Cluster默认会对 key值使用CRC16算法进行hash得到一个整数值,然后用这个整数值对16384进行取模来得到具体槽位,这是在客户端实现的,也就是Jedis实现的。定位到具体的小集群。
HASH_SLOT = CRC16(key) mod 16384
跳转重定位
当客户端向一个错误的节点发出了指令,该节点会发现指令的 key 所在的槽位并不归自己管理(意味着服务端也会算一次key的solt值),这时它会向客户端发送一个特殊的跳转指令携带目标操作的节点地址,告诉客户端去连这个节点去获取数据。
只有两台机器,所以我的部署方案是这样的,每台机器部署三个节点。假设我的机器内网ip是172.24.11.11、172.24.12.24。使用端口6379、6380、6381。则集群如下
| IP | 端口 | 主/从 |
| 172.24.11.11 | 6379 | 主 |
| 172.24.12.24 | 6380 | 从 |
| 172.24.11.11 | 6381 | 主 |
| 172.24.12.24 | 6381 | 从 |
| 172.24.12.24 | 6379 | 主 |
| 172.24.11.11 | 6380 | 从 |
必然会有一台机器有两个主节点,另一台拥有两个从节点。并且,所有主节点与从节点都不会在同一台机器,比如上图中出现的一种划分方案。这不需要我们自己配置,在使用初始化集群创建Cluster的命令时,会自动识别不同机器进行配置。
因为分Solt的特性,如果想要两台机器理论上承受相同的请求量,就需要为拥有两个主节点的那台机器共享一半的槽位,即一台分16384/2个Solt;另一台分剩下的Solt,每个主节点分(16384/2)/2 个Solt。
部署配置
两台机器都创建一个目录:
/data/redis-cluster/
并在该目录下创建三个节点的目录
/data/redis-cluster/node-6379/data/redis-cluster/node-6380/data/redis-cluster/node-6381
将redis.conf(下载安装redis时官方提供的配置文件)拷贝到三个节点的目录下。(所有操作,两台机器相同)。
对于redis的配置文件我不多说,按需配置,比如持久化策略、缓存淘汰策略、最大内存等。我只说下cluster集群需要配置的地方。
1、daemonize yes2、port 63**(分别对每个机器的端口号进行设置)3、dir /data/redis-cluster/node-63**/(指定数据文件存放位置,必须要指定不同的目 录位置,不然会丢失数据)4、cluster-enabled yes(启动集群模式)5、cluster-config-file nodes-63**.conf(集群节点信息文件,这里63**最好和port对应上)6、cluster-node-timeout 50007、注释掉 bind 127.0.0.1,去掉bind绑定访问ip信息8、protected-mode no (关闭保护模式)9、appendonly yes
如果你配置的是使用外网访问的集群,那就需要配置安全访问模式了,即配置密码。如果需要配置密码,还需修改如下配置。
10、requirepass xxx (设置redis访问密码)11、masterauth xxx (设置集群节点间访问密码,跟上面一致)
不同节点的配置文件信息相同,只是端口号、数据文件目录(rdb、aof文件等)、集群节点信息文件这几处配置不同。
cluster-config-file指定的文件,就是保存集群节点信息的文件。cluster-node-timeout节点超时配置。表示当某个节点持续timeout 的时间失联时,才可以认定该节点出现故障,需要进行主从切换。如果没有这个选项,网络抖动会导致主从频繁切换 (数据的重新复制)。
我习惯性把重复性操作写成脚本,所以每台机器上会有一个集群节点的启动脚本,当然,这些脚本只适合集群初始化的时候使用,实际生产环境下,节点的启动和重启都只能老老实实一个一个节点操作。
[redis-cluster-start.sh]/data/redis-5.0.2/src/redis-server data/redis-cluster/node-6379/redis.confsleep 1s/data/redis-5.0.2/src/redis-server data/redis-cluster/node-6380/redis.confsleep 1s/data/redis-5.0.2/src/redis-server data/redis-cluster/node-6381/redis.conf
所有机器所有节点都启动后,用redis-cli创建整个redis集群(redis5以前的版本集群是依靠ruby脚本redis- trib.rb实现的,但5.0之后就不需要那么复杂了。)
[把‘\’去掉,只是为好看分行写,用'\'表示连接]/data/redis-5.0.2/src/redis-cli \--cluster create --cluster-replicas 1 \172.24.11.11:6379 172.24.12.24:6379 172.24.11.11:6381172.24.11.11:6380 172.24.12.24:6380 172.24.12.24:6381
那个"1"指的是一个主节点分配多少个从节点,如果是1,则6个节点会被分为3个一主一从的小集群,如果是2,则6个节点会被分为2个一主两从的小集群。但是集群要求必须至少6个节点,至少要有三个主节点。
当命令执行成功后会提示Solt的预计分配信息,默认会按照主节点的数量平台分配solt。我选择yes使用默认的分配方案,后期有需要再重新分配。
这样整个Cluster就创建好了。连接任意一个节点都可以正常访问集群
./redis-cli -c -h -p (-a访问服务端密码,-c表示集群模式,-h和-p分别指定ip地址和端口号)
如不带密码的访问
/usr/local/redis-5.0.2/src/redis-cli -c -h 172.24.11.11 -p 6379
带密码的访问
/usr/local/redis-5.0.2/src/redis-cli -a xxx -c -h 172.24.11.11 -p 6379
我觉得比较坑的地方
AWS的机器需要配置安全组,需要开放6379、6380、6381的端口,但,不要忘了,这些端口是开放给客户端访问的,监听客户端连接请求的,与客户端通信的,这与ssh的22端口、mysql的6379,redshift的54xx(忘了)一样。而集群之间是需要通信的,比如主从数据的同步、比如master选举。所以,不要忘了,这些端口也是需要开放的,叫集群总线端口,默认端口号是Redis客户端连接的端口 + 10000。

只会搭建当然还不行,平常的集群维护还是要懂的,比如怎么向Cluster中添加一个节点,新增节点后如何分配Solt槽位,怎么移除一个节点,移除后怎么分配Solt槽位。懂得这些就差不多了。
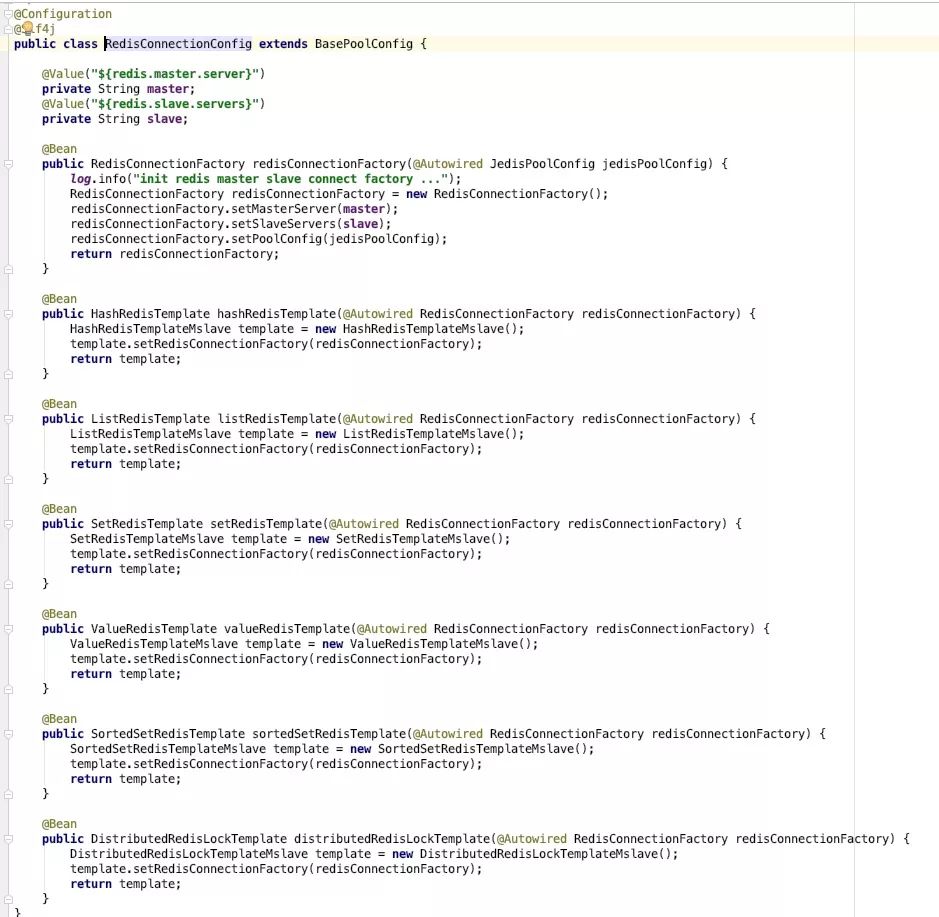
这是有历史原因的,原本项目封装了一套redis的操作模版。但由于一直使用的都是主从模式,这套模版实现读写分离,写请求访问主节点,读请求访问从节点。但是改用Cluster之后就不适用了。也不能重写,因为一套代码适配三个平台,另两个平台还是使用原来的主从读写分离模式呢。
好在前辈将缓存的读写封装成模版类,我可以直接将这些模版类抽象为接口,就可以实现不需要改任何业务代码。而且根据spring配置文件配置的平台,自动选择使用支持哪种模式的模版实现类。(封装的缓存组件需要排除spring的包扫描)
将所有模板类抽象为接口,为两种不同模式分别实现这些接口,最后根据spring配置的平台信息或者其它标志来选择一种实现方式就行了。一行业务代码也不需要修改。

根据不同环境选取不同的实现类。首先提供一个自动配置注解EnableAutoRedisConfig。
/*** @author wujiuye* @version 1.0 on 2019/7/7 {描述:}*/@Retention(RetentionPolicy.RUNTIME)@Documented@Target(ElementType.TYPE)@Import(RedisConfigImportSelector.class)public @interface EnableAutoRedisConfig {}
实现ImportSelector,我是根据是否配置“redis.cluster.host-port”来选择是否使用cluster模式的。不同模式返回不同配置文件,这就是为什么要排除这个组件的包扫描了。
/*** @author wujiuye* @version 1.0 on 2019/7/7 {描述:}*/@Slf4jpublic class RedisConfigImportSelector implements ImportSelector, EnvironmentAware {private Environment environment;@Overridepublic String[] selectImports(AnnotationMetadata annotationMetadata) {if (environment.containsProperty("redis.cluster.host-port")) {log.info("=========== selected redis cluster config ... ");return new String[]{RedisClusterConnectionConfig.class.getName()};} else {log.info("=========== selected redis master slave config ... ");return new String[]{RedisConnectionConfig.class.getName()};}}@Overridepublic void setEnvironment(Environment environment) {this.environment = environment;}}
根据不同模式配置连接工厂,注入模版实现类到spring
主从:
Cluster:



