




Redis集群有hash槽的概念,一个Redis集群总共有16384 个hash槽。这些hash槽会平均分配到各个节点去。如果一个Redis集群有三个节点A,B,C,那么0-5460号槽分配给节点A,5461-10922号槽分配给节点B,10923-16383号槽分配给节点C。
如果向Redis集群中存入一个值,那么这个值会被分配哪个槽里呢?
这里就要用到hash槽的分配算法。算法是这样的:
crc16(key)mod 16384
就是先用crc16算法对key进行计算,计算结果再和16384进行取余操作。
整理了一下关于hash的疑问,一起来看一下:
问题一:为什么hash槽要设置成16384(2的14次方) 个呢?
Redis作者的答复在这里:https://github.com/redis/redis/issues/2576
截了一下图,方便大家看。
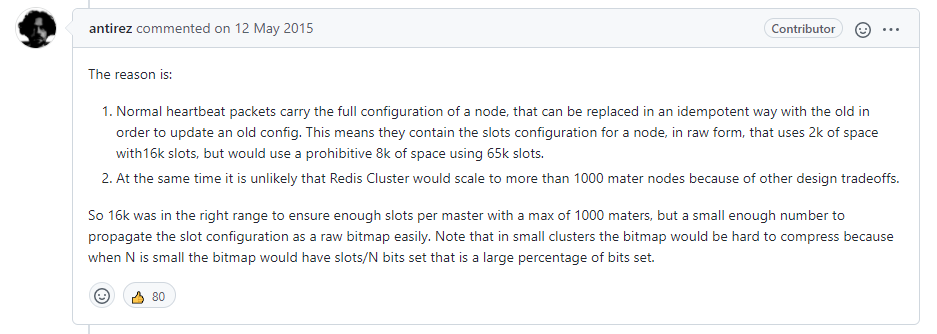
作者大意是说:在正常心跳包中就可以更新节点的完整配置信息。如果插槽的大小是16K个,心跳包大小只要2K;但是如果插槽有65K个,心跳包的大小就需要8K。另外,由于其他权衡设计,Redis集群的节点不太可能超过1K多。所以16K的插槽是在正确的范围内,以保证每个节点有足够的插槽。
从作者的回复中可以推理出一个信息,Redis集群槽信息分布的情况是通过心跳包在集群间同步的。
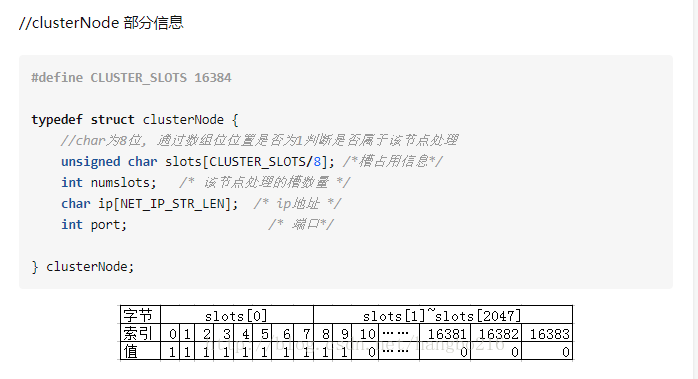
在网上找到一个节点信息的结构体,大家可以参考下:
https://www.zhihu.com/question/53927336/answer/137347302
问题二:这个值能改吗?
不能改,因为这是代码中写死的,不能在配置文件中改。如果你改了源码,重新编译那另当别论。
问题三:如果新增节点,需要怎么重新分配槽?
因为key和槽的关系是永远不会变的,当新增节点的时候,需要把原有的槽分配给新的节点负责,并且把相关的数据迁移过来。
添加一个新的主节点192.168.10.100:6378
redis-cli --cluster add-node 192.168.10.100:6378
新增的节点没有哈希槽,不能分布数据,在原来的任意一个节点上执行:
redis-cli --cluster reshard 192.168.10.100:6379
执行之后,会出现以下类似的输出,然后输入需要分配的哈希槽的数量(比如500),和哈希槽的来源节点(可以输入all或者id)。

问题四:redis集群为什么没有使用一致性hash算法,而是使用了hash槽?
因为节点太少时,一致性哈希算法可能会造成集中在某个hash区间内的值特别多,其他hash区间值相对较少,数据分布不均匀。这样会导致大量的数据请求涌入同一个节点,造成节点过热的问题(如同一时间20W的请求都在某个hash区间内)。而使用hash槽则没有这个问题。
