




堆表(heap table)和索引组织表(Index Oragnization Table,简称IOT)是两种数据表的存储结构。pg中的表是堆表。mysql Innodb引擎中的表是索引组织表。oracle中既支持堆表,也支持索引组织表。
在具体介绍堆表和索引组织表之前,我们先看下pg中index scan和index only scan。
Index Scan: 也即普通索引扫描,对于给定的查询,我们先扫描一遍索引,从索引中找到符合要求的记录的位置(指针),再定位到表中具体的Page去取。等于是两次I/O,先走索引,再取表记录。
Index only scan: 建立index时,所包含的字段集合,囊括了我们需要查询的字段,这样就只需在索引中取数据,就不必访问表了。
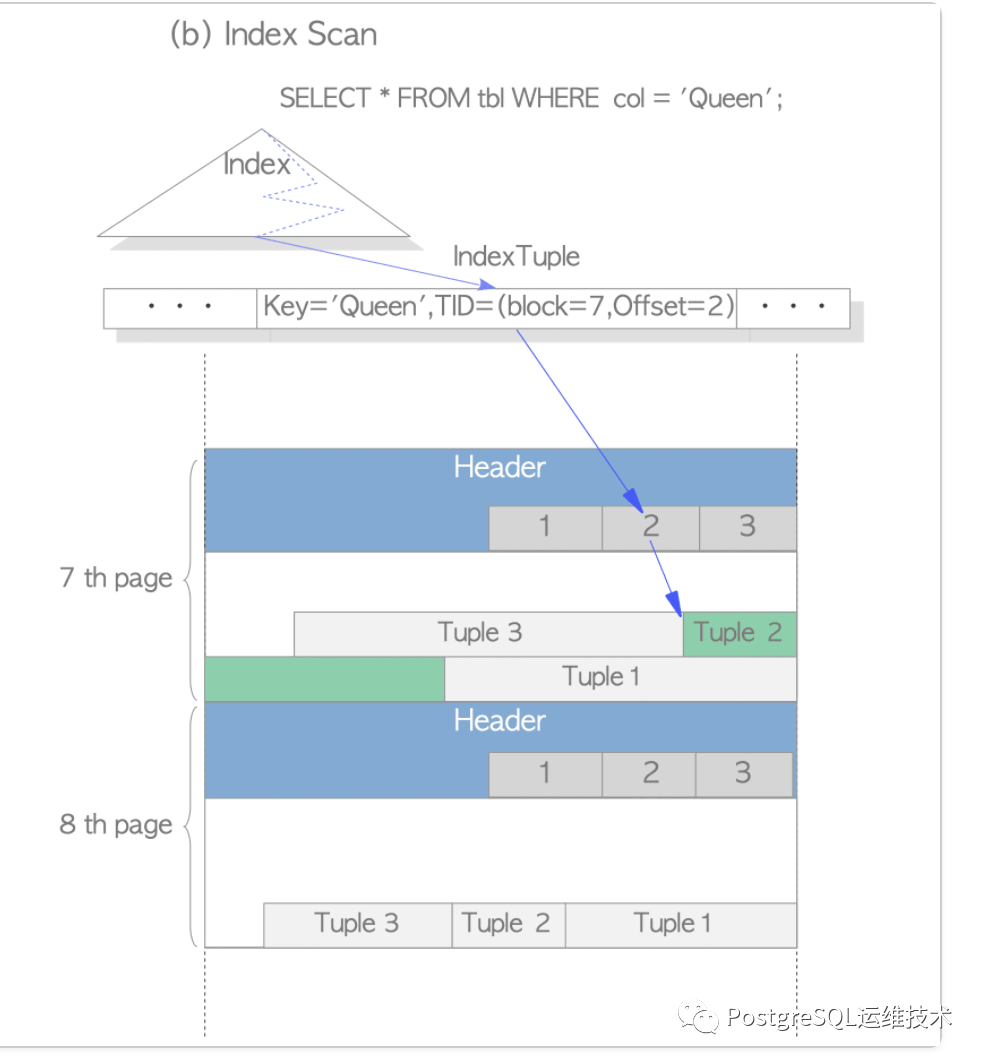
Index Scan示意图
图片来源:https://www.interdb.jp/pg/pgsql01.html
从两者的定义我们看出,pg中索引和表数据是分开存储的,索引中存储了数据行的指针,当使用普通索引查找数据时,需要先扫描索引树,找到对应的行指针,再去表中找到相应的tuple。
而index only scan可以极大的提高性能。因为不需要再去表中查找数据了。
这里我们思考一个问题:
Index only scan依靠存储在索引中的冗余数据,消除了去访问堆表的操作。如果我们将这个概念进一步扩大,并将所有列放在索引中,我们还需要堆表吗?
其实这也就引出了索引组织表的概念,索引组织表的数据是按照主键顺序被存储到一个B+树索引中的,索引就是数据,数据就是索引,二者合二为一。当使用主键去查询一个索引组织表时,不需要再访问表,能从索引中获取到表的全部数据。这也是mysql中的聚簇索引的概念,数据行存储在索引的叶子节点中。在mysql中除了聚簇索引外,还有非聚簇索引(也叫二级索引)。非聚簇索引索引它的叶子节点存的是键值和主键值。

图片来源网络
从上面的分析我们也可以看到索引组织表有些明显的好处,一是节约了磁盘空间,二是降低了IO,提高了查询的性能。尤其是当我们的数据几乎总是通过主键来进行搜索时,查询效率的提升将会很显著。
那索引组织表有什么不好的地方呢?
上面提到了索引组织表的好处,其实当索引组织表上有二级索引,并且频繁使用二级索引进行访问时,它的缺点也很明显了,那就是二级索引需要回表,它的效率要比堆表直接使用行指针访问数据的效率要低的。
还有一点堆表相对于索引组织表来说,因为不需要考虑排序,所以堆表的存储速度要更快一点。
总结一下:
堆表:数据存储在表中,索引存储在索引里,两者分开的。数据在堆中是无序的,索引让键值有序,但数据还是无序的。堆表中主键索引和普通索引一样的,都是存放指向堆表中数据的指针。
索引组织表:数据存储在聚簇索引中,或者说,数据按照主键的顺序来组织数据,两者合二为一。主键索引,叶子节点存放整行数据。其他索引称为辅助索引(二级索引),叶子节点存放键值和主键值。
参考:
https://use-the-index-luke.com/sql/clustering/index-organized-clustered-index
https://www.cnblogs.com/---wunian/p/9204822.html
