




MySQL使用 Nested-Loop Join (NLJ) 算法来执行表之间的连接,NLJ有以下三种实现:
Simple Nested-Loop Join
Index Nested-Loop Join
Bolck Nested-Loop Join
通过下面这段 SQL 我们来分析下这三者的区别。
-- 创建表t1CREATE TABLE t1 (id INT NOT NULL PRIMARY KEY,a INT NOT NULL,b INT NOT NULL,KEY idx_a ( a )) ENGINE = INNODB;-- 往t1里初始化1000条数据delimiter;;CREATE PROCEDURE initdata ()BEGINDECLARE i INT;SET i = 1;WHILE i <= 1000 DOINSERT INTO t1 VALUES ( i, i, i );SET i = i + 1;END WHILE;END;;declimiter;CALL initdata ();-- 创建表t2,并插入100条数据CREATE TABLE t2 LIKE t1;INSERT INTO t2 ( SELECT * FROM t1 WHERE id <= 100 );SELECT * FROM t1 INNER JOIN t2 ON t1.a = t2.a;
如上,t1 和 t2 都有主键索引 id 和索引 a,字段 b 无索引。存储过程 initdata() 往 t1 插入1000条数据,再往 t2 插入100条数据。最后 t1 和 t2 做了连表查询,我特意用了 STRAIGHT_JOIN ,目的是让优化器按照指定的连接方式执行查询,如果用 INNER JOIN 的话,则优化器会以小表 t2 为驱动表,然后取每行字段 a 去 t1 表的索引 idx_a 上做匹配,这样会影响我们分析 SQL 的执行过程。
Index Nested-Loop Join
下图是上面 join 语句的 explain 结果:
图 1 使用索引字段 join 的 explain 结果 |
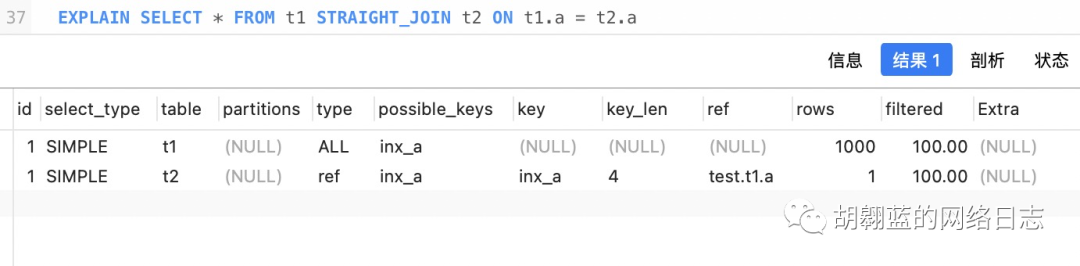
可以看到,表 t1 是驱动表,而且做了全表扫描,被驱动表 t2 的字段 a 上有索引,join 的过程中用上了这个索引,因此这条 SQL 的执行过程是:
从表 t1 读入一条数据记为 R;
从 R 中取出 a 字段,去 t2 表 a 字段的索引 (idx_a) 中查找;
取出表 t2 中满足条件的行,跟 R 组成一行,作为结果集的一部分;
重复执行步骤 1 到 3,直至表 t1 的末尾,循环结束。
这就是“Index Nested-Loop Join” (NLJ) 算法的执行流程,整个过程中表 t1 做了全表扫描,需要扫描 1000 行。对于每一行 R,根据字段 a 去表 t2 中查找,走的是树搜索,因为数据是一一对应的,所以每次只扫描一行。因此扫描的总行数是 1100 行。
Simple Nested-Loop Join
现在,我们把 join 语句改成这样:
SELECT * FROM t1 STRAIGHT_JOIN t2 ON t1.a = t2.b;
然后看看这条 SQL 的 explain 结果:
图 2 不使用索引字段 join 的 explain 结果 |
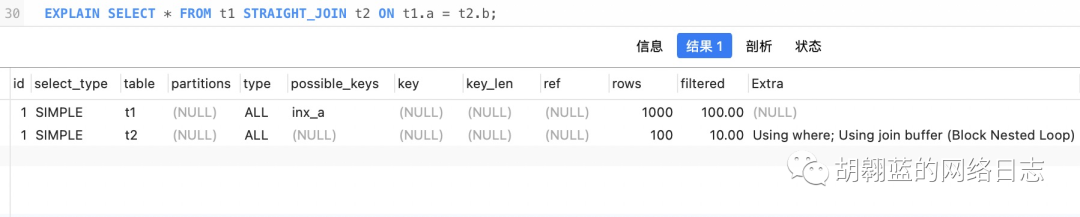
与 NLJ 不同的是,由于字段 b 没有建索引,所以 t1 每次去 t2 匹配的时候,都要做一次全表扫描,因此整个过程需要扫描的行数是 1000 * 100 = 10万行,这个算法就是“Simple Nested-Loop Join”。
类似我们写程序时的嵌套循环,将外层循环的数据传递到内层循环依次去匹配,只要还有表去 join,那么这个过程就会循环下去。如果 t1 和 t2 都是 10万行的表,就要扫描 100 亿行,这个算法看上去太“笨重”了。
事实上,MySQL 并没有使用 Simple Nested-Loop Join 算法,从图2可以看到,表 t2 的 Extra 是 Using where; Using join buffer (Block Nested Loop),所以 MySQL 使用的是“Bolck Nested-Loog Join”算法,简称 BNL。
Bolck Nested-Loog Join
BNL 是通过缓存驱动表的数据来减少被驱动表的扫描次数,MySQL 官方文档以“Join Buffer”来命名这个缓存。
算法的流程是:
将驱动表 t1 的数据读入到线程内存 join buffer 中,由于 SQL 语句是 SELECT *,因此是把整行数据放入;
扫描被驱动表 t2,取出每行数据跟 join buffer 中的数据对比,满足条件的,作为结果集的一部分。
与 Simple Nested-Loop Join 将外层循环的数据传递到内层循环依次去匹配的思想不同,BNL 是扫描被驱动表然后与 join buffer 中缓存的驱动表的数据做匹配,所以整个过程总共扫描的行数是 1000 + 100 = 1100 行,数据匹配过程中,需要判断 1000 * 100 = 10 万次,因为是内存操作,所以速度会快很多,性能也更好。
在实际应用场景下,join buffer 可能放不下驱动表的数据。join buffer 的大小是由参数 join_buffer_size 设置的,默认是256k。如果放不下驱动表所有数据,MySQL的策略是分段放。
如果 join buffer 放不下 t1 的所有数据,执行过程就变成:
将驱动表 t1 的数据读入到线程内存 join buffer 中,假设到第 800 行 join buffer 满了;
扫描被驱动表 t2,取出每行数据跟 join buffer 中的数据对比,满足条件的,作为结果集的一部分;
清空 join buffer;
继续扫描 t1,把剩下的 200 行数据放入到 join buffer 中,然后继续执行第 2 步。
小结
这篇我介绍了 MySQL 执行 join 语句可能使用的三种算法,这三种算法主要是由能否使用被驱动表的索引决定的。通过对三种算法的执行流程,可以得到以下结论:
能否用上被驱动表的索引,对 join 语句的性能影响很大;
不能使用被驱动表的索引,只能使用 Bolck Nested-Loog Join 算法,这样的 SQL 尽量不要用,需要去优化。尤其是在大表上的 join 操作,可能要扫描被驱动表很多次,会占用大量系统资源;
在使用 join 语句时,应该让小表做驱动表。
Reference:
https://dev.mysql.com/doc/refman/5.6/en/nested-loop-joins.html
极客时间《MySQL实战45讲》
