




工作中遇到需要比较mysql跨区跨库表结构,并生成变更sql的需求,用到了mysql utilities里的mysqldiff工具。
mysql utilities的源码:https://github.com/mysql/mysql-utilities,源码由python写成,工具支持2.6~3.0之间的版本。
命令:
mysqldiff --server1=user:pass@host:port --server2=user:pass@host:port db1.object1:db2.object1
--server1:配置server1的连接。
--server2:配置server2的连接。
--character-set:配置连接时用的字符集。
--width:配置显示的宽度。
--skip-table-options:保持表的选项不变,即对比的差异里面不包括表名、AUTO_INCREMENT、ENGINE、CHARSET等差异。
-d DIFFTYPE,--difftype=DIFFTYPE:差异的信息显示的方式,有 [unified|context|differ|sql],默认是unified。如果使用sql,那么就直接生成差异的SQL。
--changes-for=:修改对象。例如 –changes-for=server2,那么对比以sever1为主,生成的差异的修改也是针对server2的对象的修改。
--show-reverse:在生成的差异修改里面,同时会包含server2和server1的修改。
--force:完成所有的比较,不会在遇到一个差异之后退出。
-vv:便于调试,输出更多多信息。
-q:quiet模式,关闭多余的信息输出。
用法示例:
比较如下两个表tba和tbb:
CREATE TABLE `testa.tba` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(25) NOT NULL,
`age` int(10) unsigned NOT NULL,
`addtime` int(10) unsigned NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `testb.tbb` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(20) NOT NULL,
`age` int(10) NOT NULL,
`addtime` int(10) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
mysqldiff命令:
mysqldiff --server1=root@localhost --server2=root@localhost --changes-for=server2 --difftype=sql testa.tba:testb.tbb --skip-table-options -q;
结果:
# Comparing testa.tba to testb.tbb [FAIL]
# Transformation for --changes-for=server2:
#
ALTER TABLE `testb`.`tbb`
CHANGE COLUMN addtime addtime int(10) unsigned NOT NULL,
CHANGE COLUMN age age int(10) unsigned NOT NULL,
CHANGE COLUMN name name varchar(25) NOT NULL;
# Compare failed. One or more differences found.
在使用它的过程中,发现这个工具中存在一些问题,比如:它会忽略表的注释、null or not null的差异,但其实我们希望这些差异也能显示出来,同时我们又需要它忽略列顺序的差异等等一些问题,这个时候就准备对这个工具进行二次开发,使之能满足我们特定的需求。
在看下它的源码前,可以先思考下,如果不使用这个工具,我们自己写一个工具去表比较两个表结构的差异,并生成变更sql语句,可以怎么做?
为了生成目标表的表更语句,主要包括对表外键、索引、列的修改,我们需要收集所有alter子句的列表。
顺序很重要,我们需要以下列顺序,组织语句。
删除外键约束 删除索引 删除列 添加/更改列 添加索引 添加外键 表option(如AUTOINCREMENT、CHARSET、ENGINE等)更改
对表主要包括对外键、列、索引的变更,这三个思想是一样的。
外键
对于外键,我们需要生成两个集合:drop语句,add语句。
假设需要比较表a和表b,为表b生成alter语句。我们需要有drop语句,即drop掉表b中存在但表a中不存在的外键,也需要有add语句,即add表a中存在但表b中不存在的外键。这里我们需要获取两个对象,即存在表a但不存在于表b的外键列表, 存在于表b但不存在于表a的外键列表。
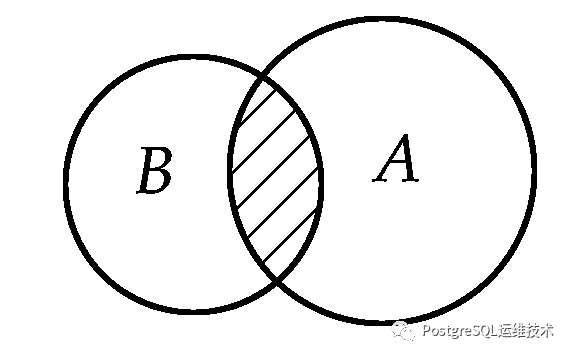
例如,给定list1{s,b,c,d,e,f}和list2{a,b,c,d,e,z},
在list1也在list2 = {b, c, d, e}
在list1中不在list2 = {s,f}
在list2中不在list1 = {a.z] 这里的算法也很简单,只是简单的集合运算。
对应的代码:
def get_common_lists(list1, list2):
"""Compare the items in two lists.This method compares the items in two lists returning those items that appear in both lists as well as two lists that contain those unique items from the original lists. Returns three lists.
"""
s1 = set(list1)
s2 = set(list2)
both = s1 & s2
return(list(both), list(s1 - both), list(s2 - both))
获取到drop keys列表和add keys列表, 遍历drop_keys,拼接“DROP FOREIGN KEY %s”语句,遍历add_keys拼接“ADD CONSTRAINT %s FOREIGN KEY(%s)”语句。
# dest_fkeys:目标表的外键列表,src_fkeys:基准表的外键列表,
_, drop_keys, add_keys = get_common_lists(dest_fkeys, src_fkeys)
# Generate DROP foreign key clauses
for fkey in add_keys:
drop_constraints.append("DROP FOREIGN KEY %s" % fkey[0])
# Generate Add foreign key clauses
clause_fmt = "ADD CONSTRAINT %s FOREIGN KEY(%s) REFERENCES " + \
"`%s`.`%s`(%s)"
for fkey in add_keys:
add_constraints.append(clause_fmt % fkey)
return (drop_constraints, add_constraints)
索引
索引也是一样的思想,获取到drop idx列表和add idx列表, 遍历drop_idx,拼接“DROP (PRIMARY) KEY %s”语句,遍历add_idex拼接“ADD PRIMARY KEY %s”。
_, drop_idx, add_idx = get_common_lists(dest_idx, src_idx)
if not drop_idx and not add_idx:
return ([], [])
# Generate DROP index clauses
drop_idx_recorded = [] # used to avoid duplicate index drops
for index in drop_idx:
if index[2] == "PRIMARY":
drop_indexes.append(" DROP PRIMARY KEY")
elif index[2] not in drop_idx_recorded:
drop_indexes.append(" DROP INDEX %s" % index[2])
drop_idx_recorded.append(index[2])
# Generate ADD index clauses
if len(add_idx) > 0:
add_indexes.extend(self._get_index_sql_clauses(
add_idx,
self.dest_tbl.sql_mode
))
return (drop_indexes, add_indexes)
列
列与外键和索引两个不同的地方在于,除了drop和add, 列还涉及到change。
表a和表b,为表b生成alter语句,只针对列来说,它生成alter语句的规则是:
在表a中但不在表b中的:生成add column语句。 不在表a中但在表b中的:生成drop column语句。 既在表a又在表b中, 但类型、位置不一样的:生成change column语句。
我看的这个版本——1.6.5,列(column)如果只是注释或者null or not null的不同,不会生成change column语句。如果想把注释或者not null的change column语句打出来,就需要进行二次开发。具体的细节就不展开了,正如我上面讲到的,思路比较明晰,理清楚了,改起来也简单。
