





在Oracle Clusterware需要从集群中逐出特定节点或一组节点的情况时,基于服务器权重的节点驱逐可充当断裂机制,通过服务器上的负载附加信息来识别要驱逐的节点或节点组。其中所有节点被驱逐的可能性是一样的。
本课程视频,点击阅读原文即可下载
基于权重的集群驱逐(Server Weight-Based Node Eviction)是一项Oracle 12.2版本引入的一项新特性。在此之前,Oracle集群在处理脑裂问题时,通过判断子群(各自独立)的规模情况,来决定在脑裂问题发生时,终止哪个子群,判断的依据如下:
如果子群规模(包含节点数量)不等,则大的子群获胜,例如,{1} {2,3,4}后者获胜,子群{1}被驱逐;
如果子群规模(包含节点数量)相等,则包含最小节点号的子群获胜,例如,{1,4}{2,3}, 子群{1,4}获胜,子群{2,3}被驱逐。
而在Oracle 12.2版本上引入的这项新特性,一定程度上增加了我们对于集群的控制。这种控制使得我们能避免由于一些规则原来的限定,而减少对大范围的应用产生影响。
注意:
以下针对weight以及权重表述的是同一个意思。
使用前提条件
权重(Weight)分配只能在admin-managed的节点生效
可以对于server或者对于注册到集群的应用进行权重(Weight)分配
使用说明
权重分配给server
使用crsctl set server css_critical yes命令
权重分配给数据库实例或服务
在srvctl add/modify databse 或 srvctladd/modify service命令中带上“-css_critical yes”参数
权重分配给非ora.*资源
在crsctl add/modify resource命令中,加入-attr "CSS_CRITICAL=yes"参数
注意:
有些权重的分配需要重启集群才能生效,而有些资源的分配,则不需要重启资源。
根据目前发现,非ora.*资源并非所有都能直接加入属性直接修改,但是属性中可以看到有CSS_CRITICAL属性,可能是当前版本未开发修改接口。
实验环境说明
使用软件环境说明:
OS:MacOS 10.11.6
VirtualBox:v5.1.30 r118389 (Qt5.6.3)
虚拟机环境说明:
OEL(OracleEnterprise Linux) 6.5 , x86_64
Oracle 12.2.0.1 (2-node RAC)
实验前的准备工作
VirtualBox虚拟机中的网卡情况如下:

其中网卡1为Public网络,网卡2为心跳网络分别对应OEL6.5中的eth0网卡和eth1网卡。
为了模拟心跳网络中断,我们在系统中编写了如下两个脚本去模拟心跳网络中断以及恢复:
Milo-Mac:lab milo$ ls -l
total 16
-rwxr--r-- 1 milo staff 111 1 24 21:38 interconnect_down.sh
-rwxr--r-- 1 milo staff 109 1 24 21:39 interconnect_up.sh
Milo-Mac:lab milo$
#### 模拟心跳网络中断:
Milo-Mac:lab milo$ sh interconnect_down.sh
查看虚拟机的网卡的连通情况:
[root@rac122a ~]# mii-tool eth0
eth0: no autonegotiation, 100baseTx-FD, link ok
[root@rac122a ~]# mii-tool eth1
eth1: autonegotiation restarted, no link
[root@rac122b ~]# mii-tool eth0
eth0: no autonegotiation, 100baseTx-FD, link ok
[root@rac122b ~]# mii-tool eth1
eth1: autonegotiation restarted, no link
可以看到在脚本运行后,私网网卡eth1显示为no link表示网线没有连接到网卡中,即我们认为心跳网络出现故障。
Milo-Mac:lab milo$ ls -l
total 16
-rwxr--r-- 1 milo staff 111 1 24 21:38 interconnect_down.sh
-rwxr--r-- 1 milo staff 109 1 24 21:39 interconnect_up.sh
Milo-Mac:lab milo$
#### 恢复心跳网络:
Milo-Mac:lab milo$ sh interconnect_up.sh查看虚拟机的网卡的连通情况:
[root@rac122a ~]# mii-tool eth0
eth0: no autonegotiation, 100baseTx-FD, link ok
[root@rac122a ~]# mii-tool eth1
eth1: no autonegotiation, 100baseTx-FD, link ok
[root@rac122b ~]# mii-tool eth0
eth0: no autonegotiation, 100baseTx-FD, link ok
[root@rac122b ~]# mii-tool eth1
eth1: no autonegotiation, 100baseTx-FD, link ok可以看到在脚本运行后,私网网卡eth1显示为link ok表示网线连接到网卡中,即我们认为心跳网络恢复,当然实际情况是我们还需要重新禁用和启用eth1网卡,才能使其完全恢复,因此需要在两个节点都执行以下脚本:
[root@rac122a ~]# sh recover_interconnect.sh
Device state: 3 (disconnected)
Active connection state: activated
Active connection path: org/freedesktop/NetworkManager/ActiveConnection/2上述相关脚本如下:
Milo-Mac:lab milo$ cat interconnect_down.sh
VBoxManage controlvm "12c_rac_node1" setlinkstate2 off
VBoxManage controlvm "12c_rac_node2" setlinkstate2 off
Milo-Mac:lab milo$ cat interconnect_up.sh
VBoxManage controlvm "12c_rac_node1" setlinkstate2 on
VBoxManage controlvm "12c_rac_node2" setlinkstate2 on
[root@rac122a ~]# cat recover_interconnect.sh
ifdown eth1 && ifup eth1
经过上述测试,我们已经可以模拟心跳网络故障以及恢复心跳网络故障。
以下测试场景不再赘述,上述故障模拟以及故障恢复过程。
测试场景
[oracle@rac122a ~]$ crsctl get server css_critical
CRS-5092: Current value of the server attribute CSS_CRITICAL is no.
[oracle@rac122b ~]$ crsctl get server css_critical
CRS-5092: Current value of the server attribute CSS_CRITICAL is no.
当前系统上存在的服务也为设置:
[oracle@rac122b ~]$ crsctl stat res ora.milodb.milodb_srv1.svc -f | grep CSS
CSS_CRITICAL=no
[oracle@rac122b ~]$ crsctl stat res ora.milodb.milodb_srv2.svc -f | grep CSS
CSS_CRITICAL=no
模拟心跳网络故障
Milo-Mac:lab milo$ sh interconnect_down.sh
节点1集群的alert日志:
2018-01-25 08:17:33.423 [OCSSD(3896)]CRS-1612: Network communication with node rac122b (2) missing for 50% of timeout interval. Removal of this node from cluster in 14.610 seconds
2018-01-25 08:17:41.435 [OCSSD(3896)]CRS-1611: Network communication with node rac122b (2) missing for 75% of timeout interval. Removal of this node from cluster in 6.600 seconds
2018-01-25 08:17:45.438 [OCSSD(3896)]CRS-1610: Network communication with node rac122b (2) missing for 90% of timeout interval. Removal of this node from cluster in 2.600 seconds
2018-01-25 08:17:49.554 [OCSSD(3896)]CRS-1607: Node rac122b is being evicted in cluster incarnation 412297497; details at (:CSSNM00007:) in u01/app/grid/diag/crs/rac122a/crs/trace/ocssd.trc.
节点2集群的alert日志:
2018-01-25 08:17:34.128 [OCSSD(25756)]CRS-1612: Network communication with node rac122a (1) missing for 50% of timeout interval. Removal of this node from cluster in 14.450 seconds
2018-01-25 08:17:41.140 [OCSSD(25756)]CRS-1611: Network communication with node rac122a (1) missing for 75% of timeout interval. Removal of this node from cluster in 7.440 seconds
2018-01-25 08:17:46.193 [OCSSD(25756)]CRS-1610: Network communication with node rac122a (1) missing for 90% of timeout interval. Removal of this node from cluster in 2.380 seconds
…省略部分信息
从上述信息来看,根据之前的集群脑裂出现的规则,在同等规模的子群中,节点1节点号小,因而存活,节点2被驱逐出集群。
将心跳网络恢复以及集群状态恢复正常后,我们将对server级别的权重进行设置。
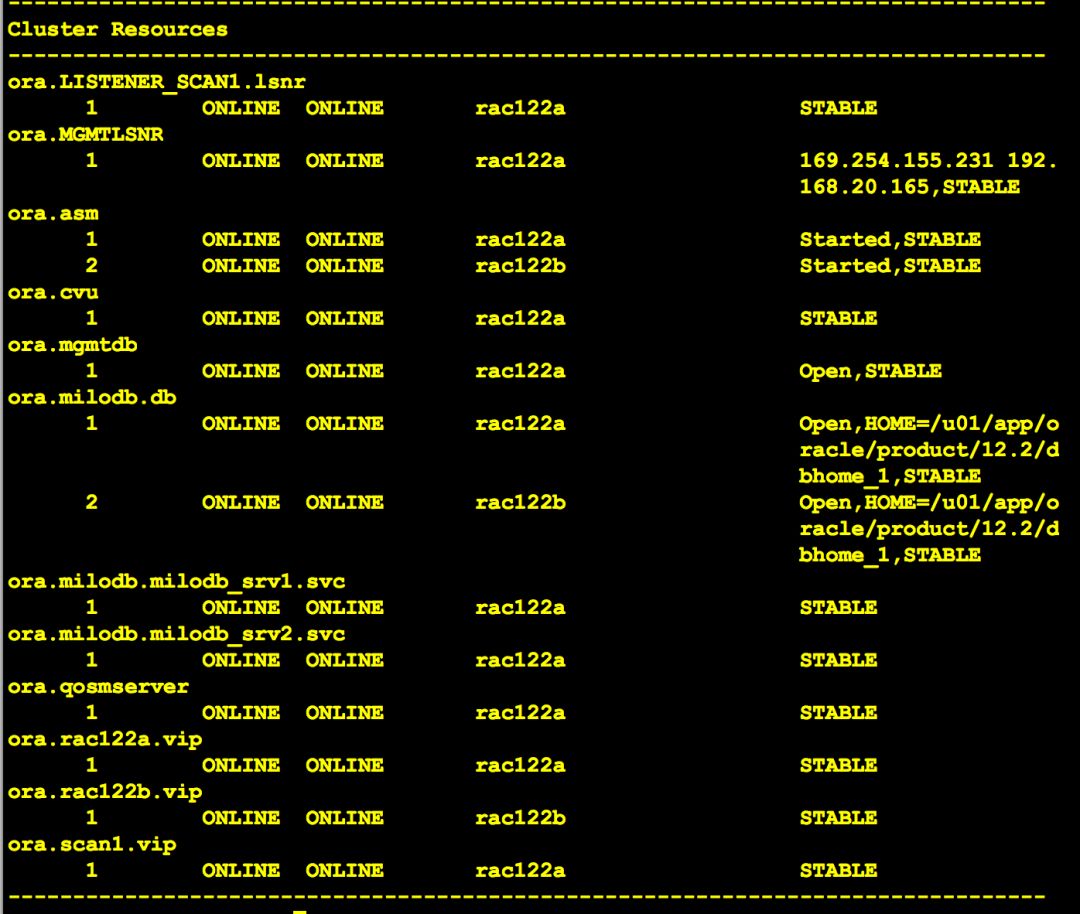
[root@rac122a ~]# crsctl get server css_critical
CRS-5092: Current value of the server attribute CSS_CRITICAL is no.
[root@rac122b ~]# crsctl get server css_critical
CRS-5092: Current value of the server attribute CSS_CRITICAL is no.
[root@rac122b ~]# crsctl set server css_critical yes
CRS-4416: Server attribute 'CSS_CRITICAL' successfully changed. Restart Oracle High Availability Services for new value to take effect.
设置完成后,提示需要重启OHAS才能生效。
$ srvctl stop instance -d milodb -i milodb2
# crsctl stop crs
# crsctl start crs
模拟网路故障:
Milo-Mac:lab milo$ sh interconnect_down.sh
此时,我们来观察集群的一些日志情况:
节点1集群的alert日志:
2018-01-25 09:44:03.671 [OCSSD(3717)]CRS-1612: Network communication with node rac122b (2) missing for 50% of timeout interval. Removal of this node from cluster in 14.890 seconds
2018-01-25 09:44:11.731 [OCSSD(3717)]CRS-1611: Network communication with node rac122b (2) missing for 75% of timeout interval. Removal of this node from cluster in 6.830 seconds
2018-01-25 09:44:15.739 [OCSSD(3717)]CRS-1610: Network communication with node rac122b (2) missing for 90% of timeout interval. Removal of this node from cluster in 2.830 seconds
2018-01-25 09:44:18.573 [OCSSD(3717)]CRS-1609: This node is unable to communicate with other nodes in the cluster and is going down to preserve cluster integrity; details at (:CSSNM00008:) in u01/app/grid/diag/crs/rac122a/crs/trace/ocssd.trc.
2018-01-25 09:44:18.573 [OCSSD(3717)]CRS-1656: The CSS daemon is terminating due to a fatal error; Details at (:CSSSC00012:) in u01/app/grid/diag/crs/rac122a/crs/trace/ocssd.trc
2018-01-25 09:44:18.616 [OCSSD(3717)]CRS-1652: Starting clean up of CRSD resources.
2018-01-25 09:44:20.608 [OCSSD(3717)]CRS-1608: This node was evicted by node 2, rac122b; details at (:CSSNM00005:) in u01/app/grid/diag/crs/rac122a/crs/trace/ocssd.trc.
节点2集群的alert日志:
2018-01-25 09:44:04.327 [OCSSD(8586)]CRS-1612: Network communication with node rac122a (1) missing for 50% of timeout interval. Removal of this node from cluster in 14.020 seconds
2018-01-25 09:44:11.609 [OCSSD(8586)]CRS-1611: Network communication with node rac122a (1) missing for 75% of timeout interval. Removal of this node from cluster in 6.730 seconds
2018-01-25 09:44:15.611 [OCSSD(8586)]CRS-1610: Network communication with node rac122a (1) missing for 90% of timeout interval. Removal of this node from cluster in 2.730 seconds
2018-01-25 09:44:19.777 [OCSSD(8586)]CRS-1607: Node rac122a is being evicted in cluster incarnation 412336033; details at (:CSSNM00007:) in u01/app/grid/diag/crs/rac122b/crs/trace/ocssd.trc.
此时,我们从集群的alert日志中看到由于节点1被集群驱逐了。
通过从节点2的ocssd.trc日志我们看到如下信息:
[grid@rac122b trace]$ cat ocssd.trc |egrep -i weight| tail -300
……省略部分信息
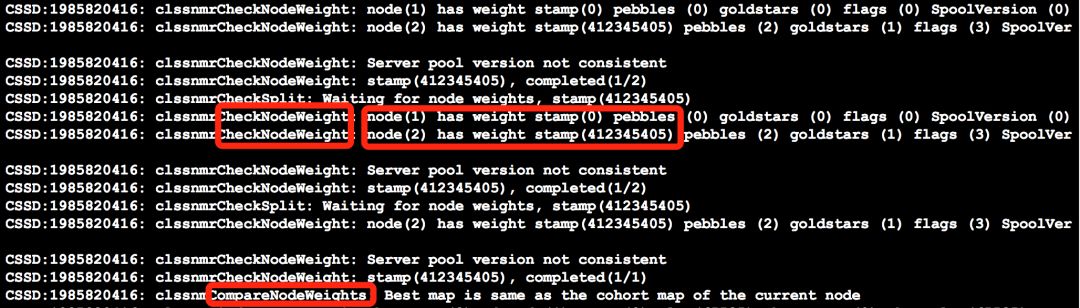
2018-01-25 09:44:18.347 : CSSD:1494243072: clssnmrCheckNodeWeight: node(1) has weight stamp(0) pebbles (0) goldstars (0) flags (0) SpoolVersion (0)
2018-01-25 09:44:18.347 : CSSD:1494243072: clssnmrCheckNodeWeight: node(2) has weight stamp(412336032) pebbles (0) goldstars (1) flags (3) SpoolVersion (0)
2018-01-25 09:44:18.347 : CSSD:1494243072: clssnmrCheckNodeWeight: Server pool version not consistent
2018-01-25 09:44:18.347 : CSSD:1494243072: clssnmrCheckNodeWeight: stamp(412336032), completed(1/2)
2018-01-25 09:44:18.347 : CSSD:1494243072: clssnmrCheckSplit: Waiting for node weights, stamp(412336032)
2018-01-25 09:44:19.777 : CSSD:1494243072: clssnmrCheckNodeWeight: node(2) has weight stamp(412336032) pebbles (0) goldstars (1) flags (3) SpoolVersion (0)
2018-01-25 09:44:19.777 : CSSD:1494243072: clssnmrCheckNodeWeight: Server pool version not consistent
2018-01-25 09:44:19.777 : CSSD:1494243072: clssnmrCheckNodeWeight: stamp(412336032), completed(1/1)
2018-01-25 09:44:19.777 : CSSD:1494243072: clssnmCompareNodeWeights: Best map is same as the cohort map of the current node
2018-01-25 09:44:19.777 : CSSD:1494243072: clssnmFindBestMap: Using base map(2) of node(1) count(0), low(65535), bestcount(0), best_low(65535), cur_weightpebbles (0) goldstars (0) flags (0) SpoolVersion (0)best_weightpebbles (0) goldstars (0) flags (0) SpoolVersion (0)
2018-01-25 09:44:19.777 : CSSD:1494243072: clssnmCompareNodeWeights: count(1), low(2), bestcount(0), best_low(65535), cur_weight: pebbles(0) goldstars(1) pubnw(1) flexasm(1)best_weight: pebbles(0) goldstars(0)pubnw(0) flexasm(0)
从上述信息来看,CSSD进程会去检查节点的权重情况(CheckNodeWeight)以及比较节点的权重(CompareNodeWeights)节点2的权重大,此时,节点2这个子群战胜了节点1子群,因而我们看到的情况是节点1被集群驱逐。
将心跳网络恢复以及集群状态恢复正常后,我们将对service级别的权重进行设置。
恢复集群server的权重:
[root@rac122b ~]# crsctl get server css_critical
CRS-5092: Current value of the server attribute CSS_CRITICAL is yes.
[root@rac122b ~]# crsctl set server css_critical no
CRS-4416: Server attribute 'CSS_CRITICAL' successfully changed. Restart Oracle High Availability Services for new value to take effect.
[root@rac122b ~]# crsctl get server css_critical
CRS-5092: Current value of the server attribute CSS_CRITICAL is no.
[root@rac122b ~]#
设置完成后,提示需要重启OHAS才能生效。
$ srvctl stop instance -d milodb -i milodb2
# crsctl stop crs
# crsctl start crs
这里我们添加两个专门用于做权重控制的服务(不对外使用):
srvctl add service -db milodb -service milodb_wt_srv1 -preferred milodb1
srvctl add service -db milodb -service milodb_wt_srv2 -preferred milodb2
srvctl start service -database milodb -service milodb_wt_srv1
srvctl start service -database milodb -service milodb_wt_srv2

在实例1上的服务不设置权重:
[oracle@rac122b ~]$ crsctl stat res ora.milodb.milodb_wt_srv1.svc -f | grep CSS
CSS_CRITICAL=no
在实例2上的服务设置权重:
[oracle@rac122b ~]$ crsctl stat res ora.milodb.milodb_wt_srv2.svc -f | grep CSS
CSS_CRITICAL=no
[oracle@rac122b ~]$ srvctl modify service -db milodb -service milodb_wt_srv2 -css_critical yes
[oracle@rac122b ~]$ crsctl stat res ora.milodb.milodb_wt_srv2.svc -f | grep CSS
CSS_CRITICAL=yes
[oracle@rac122b ~]$
此时,我们来观察集群的一些日志情况:
节点1集群的alert日志:
2018-01-25 11:33:30.343 [OCSSD(3652)]CRS-1612: Network communication with node rac122b (2) missing for 50% of timeout interval. Removal of this node from cluster in 14.910 seconds
2018-01-25 11:33:38.351 [OCSSD(3652)]CRS-1611: Network communication with node rac122b (2) missing for 75% of timeout interval. Removal of this node from cluster in 6.900 seconds
2018-01-25 11:33:42.576 [OCSSD(3652)]CRS-1610: Network communication with node rac122b (2) missing for 90% of timeout interval. Removal of this node from cluster in 2.680 seconds
2018-01-25 11:33:45.255 [OCSSD(3652)]CRS-1609: This node is unable to communicate with other nodes in the cluster and is going down to preserve cluster integrity; details at (:CSSNM00008:) in u01/app/grid/diag/crs/rac122a/crs/trace/ocssd.trc.
2018-01-25 11:33:45.255 [OCSSD(3652)]CRS-1656: The CSS daemon is terminating due to a fatal error; Details at (:CSSSC00012:) in u01/app/grid/diag/crs/rac122a/crs/trace/ocssd.trc
2018-01-25 11:33:45.269 [OCSSD(3652)]CRS-1652: Starting clean up of CRSD resources.
2018-01-25 11:33:47.289 [OCSSD(3652)]CRS-1608: This node was evicted by node 2, rac122b; details at (:CSSNM00005:) in u01/app/grid/diag/crs/rac122a/crs/trace/ocssd.trc.
节点2集群的alert日志:
2018-01-25 11:33:29.844 [OCSSD(3983)]CRS-1612: Network communication with node rac122a (1) missing for 50% of timeout interval. Removal of this node from cluster in 14.900 seconds
2018-01-25 11:33:37.946 [OCSSD(3983)]CRS-1611: Network communication with node rac122a (1) missing for 75% of timeout interval. Removal of this node from cluster in 6.790 seconds
2018-01-25 11:33:41.947 [OCSSD(3983)]CRS-1610: Network communication with node rac122a (1) missing for 90% of timeout interval. Removal of this node from cluster in 2.790 seconds
2018-01-25 11:33:46.684 [OCSSD(3983)]CRS-1607: Node rac122a is being evicted in cluster incarnation 412345406; details at (:CSSNM00007:) in u01/app/grid/diag/crs/rac122b/crs/trace/ocssd.trc.
2018-01-25 11:33:47.755 [ORAAGENT(5634)]CRS-5818: Aborted command 'check' for resource 'ora.SYSTEMDG.dg'. Details at (:CRSAGF00113:) {0:1:11} in u01/app/grid/diag/crs/rac122b/crs/trace/crsd_oraagent_grid.trc.
2018-01-25 11:33:47.759 [ORAAGENT(5634)]CRS-5818: Aborted command 'check' for resource 'ora.DATADG.dg'. Details at (:CRSAGF00113:) {0:1:11} in u01/app/grid/diag/crs/rac122b/crs/trace/crsd_oraagent_grid.trc.
2018-01-25 11:33:49.250 [OCSSD(3983)]CRS-1601: CSSD Reconfiguration complete. Active nodes are rac122b .
2018-01-25 11:33:49.617 [CRSD(5349)]CRS-5504: Node down event reported for node 'rac122a'.
从节点2的ocssd日志看到,同样由于节点2的权重高,因而最终将节点1驱逐除了集群:
后续测试将两个服务都设置权重时,情况与不设置权重的情况一致,即节点1驱逐节点2。
通过上述场景的测试,我们得知:
基于权重的节点驱逐可以在集群出现脑裂时,通过控制减少消除一些影响;
配置server方式的权重,需要修改配置后,重启crs才能生效;
通过服务的方式配置节点的权重不需要重启资源,可以实现动态控制,更灵活。
当然,由于在该特性是12.2引入的,属于新特性,可能会存在一些bug,建议在使用前应该经过充分测试后使用。
作者介绍:
罗雪原,云和恩墨南区交付技术顾问。
个人有着8年的Oracle技术支持经验,曾服务过金融、保险、电力、政府、运营商等客户,有着较丰富的Troubleshooting以及优化经验。
,回复:prelection,你可以找到本文的相关视频文档。

相关阅读:
Oracle 12.2 新特性 | PDB不同字符集变更深入解析

