






预计阅读本文需要:28分钟;
已收录github仓库欢迎朋友Star:https://github.com/Datalong/Code2020
1 定义
在《Java编程思想》中,流定义为代表任何有能力产出数据的数据源对象或者有能力接受数据的接收端对象;
❝也就是说,流的本质其实就是「数据传输」,就是计算机「各部件」的数据流动;
❞
思考
“输入”与“输出”有时候让我有时候些疑惑。你说一个程序的输入往往是另外一个程序的输出。那么「OutputStream」流到底是一个输出到目的地的流?还是一个产生输出的流呢?「InputStream」流会不会输出它的数据给读数据的程序?就我个人而言,在第一天学习Java io的时候就感觉到了一丝疑惑。我试着给输入和输出起不一样的「别名」,让它们在概念上与数据的来源与数据的流向相联系起来;
2 分类
注意:这里的输入、输出是针对「程序」而言。
按照流向分:
「输出流」:内存中的程序输出到磁盘、光盘等存储设备; 
「输入流」:读外部数据比如磁盘等存储设备的数据到程序(内存); 
❝在Java中,输入流主要是「InputStream」和Reader作为基类,而输出流则主要是「OutputStream」和Writer作为基类。它们都是一些抽象基类,并不能直接用于创建对象实例;
❞
处理数据单位不同分:
在介绍字节流和字符流之前,我们需要知道「字节」和「字符」的关系:
❝1字符=2字节;
❞
1字节(byte)=8位;
一个汉字占两个字节长度(因为汉字博大精深,所以有些汉字也会占到「三个字节」的长度);
「字节流」:每次读取(写出)一个字节,当传输的「资源文件」有中文时,就会出现乱码; 「字符流」:每次读取(写出)两个字节,有中文时,使用该流就可以正确传输显示中文;
❝在Java中,字节流主要是由InputStream和OutputStream作为基类,根据这两个派生而来类都含有read()和write()的基本方法,用于读写「单个字节或者字节数组」;
❞
InputStream & OutputStream类
「InputStream」类是一个抽象类 ,是所有字节输入流类的父类;
「OutputStream」类是一个抽象类,是所有字节输出流的父类
「InputStream」常见子类有:
❝FileInputStream:看这个名字就知道用于从文件中读取信息,
❞
ByteArrayInputStream: 字节数组输入流,
ObjectInputStream:序列化时使用 一般和ObjectOutputStream一起使用,
FilterInputStream: 过滤输入流,为基础的输入流提供一些额外的操作;
「OutputStream」常见子类有:
❝FileOutPutStream: 文件输出流对文件进行操作,
❞
ByteArrayOutputStream: 字节数组输出流,
ObjectOutputStream: 序列化时使用 一般和OjbectInputStream一起使用,
FilterOutputStream:过滤输出流,为基础的输出流提供一些额外的操作,
我们一个一个过要不然怎么能叫一文带你看懂JAVA IO流了呢,那样不就是标题党了吗[滑稽]。
FileInputStream & FileOutPutStream类
FileInputStream是文件字节输入流,就是对文件数据以字节的方式来处理,如「音乐、视频、图片」等;
FileOutPutStream是「文件字节输出流」,
FileInputStream里面的方法
//通过文件的名字来创建一个对象
public FileInputStream(String name) throws FileNotFoundException{}
//通过File对象来创建一个对象
public FileInputStream(File file) throws FileNotFoundException{}
/**
* 通过FileDescriptor来创建一个对象
* FileDescriptor是一个文件描述符号
* 有in,out,err三种类型
* in:标准输入描述符,out:标准输出的描述符,err:标准错误输出的描述号
*/
public FileInputStream(FileDescriptor fdObj){}
//打开指定的文件进行读取 ,是java和c之间进行操作的api 我们并不会用到
private native void open0(String name){}
//打开指定的文件进行读取,我们并不会用到 因为在构造方法里面帮我们打开了这个文件
private void open(String name){}
//从输入流中读取一个字节的数据,如果到达文件的末尾则返回-1
public int read() throws IOException{}
//读取一个字节数组
private native int readBytes(byte b[], int off, int len) throws IOException;
private native int read0() throws IOException;
//从输入流中读取b.length的数据到b中
public int read(byte b[]) throws IOException{}
//从输入流中读取off到len之间的数据到b中
public int read(byte b[], int off, int len) throws IOException{}
//跳过并丢弃输入流中的n个数据
public long skip(long n) throws IOException{}
private native long skip0(long n) throws IOException;
//可以从此输入流中读取的剩余字节数
public int available() throws IOException {}
private native int available0() throws IOException;
//关闭此文件输入流并释放与该流关联的所有系统资源
public void close() throws IOException {}
//返回FileDescriptor对象
public final FileDescriptor getFD() throws IOException{}
//该方法返回与此文件输入流关联的通道 NIO中会用到 本文不会提及
public FileChannel getChannel(){}
private static native void initIDs();
private native void close0() throws IOException;
//没有更多引用时,调用此方法来关闭输入流 一般不使用
protected void finalize() throws IOException {}
由于篇幅起见「FileOutputStream」代码里面的方法我就不仔细的带你们看了(我不会说我是因为懒才不带你们看的,溜。)

public class Test {
public static void main(String []args) throws IOException {
//根据文件夹的名字来创建对象
FileOutputStream fileOutputStream = new FileOutputStream("D:\\hello.txt");
//往文件里面一个字节一个字节的写入数据
fileOutputStream.write((int)'h');
fileOutputStream.write((int)'e');
fileOutputStream.write((int)'l');
fileOutputStream.write((int)'l');
fileOutputStream.write((int)'o');
String s = " world";
//入文件里面一个字节数组的写入文件
fileOutputStream.write(s.getBytes());
fileOutputStream.close();
//传文件夹的名字来创建对象
FileInputStream fileInputStream = new FileInputStream("D:\\hello.txt");
int by = 0;
//一个字节一个字节的读出数据
while((by = fileInputStream.read()) != -1){
System.out.println((char)by);
}
//关闭流
fileInputStream.close();
//通过File对象来创建对象
fileInputStream = new FileInputStream("new File("D:\\hello.txt")");
byte []bytes = new byte[10];
//一个字节数组的读出数据
while ((by = fileInputStream.read(bytes)) != -1){
for(int i = 0; i< by ; i++){
System.out.print((char) bytes[i]);
}
}
//关闭流
fileInputStream.close();
}
}
按照流的角色划分为节点流和处理流
节点流:就是可以从/向一个「特定的IO设备」(节点,磁盘)读写数据的流。如FileInputStream;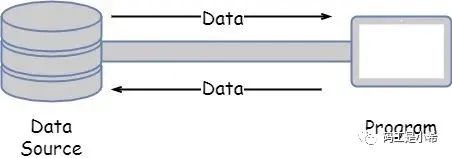 可以从上图看出,当使用节点流进行输入和输出数据过程中,程序直接连接到「实际的数据源」,和实际的输入/输出节点连接。节点流也被称为低级流。
可以从上图看出,当使用节点流进行输入和输出数据过程中,程序直接连接到「实际的数据源」,和实际的输入/输出节点连接。节点流也被称为低级流。
处理流(也叫包装流):是对一个已存在的流的「连接和封装」,通过所封装的流的功能调用实现「数据读写」。如BufferedReader。处理流的构造方法总是要带一个其他的流对象做参数,流对象经过其他流的「多次包装」,称为流的链接;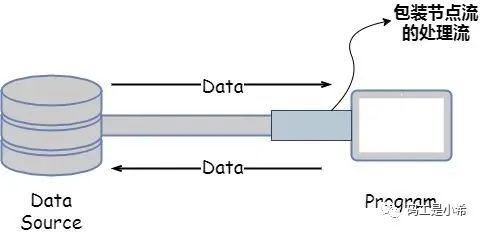
❝当使用处理流进行输入/输出操作时,程序并不会直接连接到实际的数据源,也就是说没有与「实际的输入和输出节点」连接。只要使用相同的处理流,程序就可以采用完全相同的输入/输出代码来访问不同的数据源,随着处理流所包装的节点流的变化,程序实际「访问的数据源」也会相应地发生变化;
❞
「注意」:一个IO流可以既是输入流又是字节流又或是以其他方式分类的流类型,是不冲突的。比如FileInputStream,它既是输入流又是字节流还是文件节点流;
Java IO流共涉及「40」多个类,这些类看上去很杂乱,但实际上「很有规则」,而且彼此之间存在非常紧密的联系,他们都是从如下4个抽象类基类中「派生」出来;
「InputStream/Reader」: 所有的输入流的基类,前者是字节输入流,后者是字符输入流; 「OutputStream/Writer」: 所有输出流的基类,前者是字节输出流,后者是字符输出流;我们知道,流的作用就像是一个数据管道,而数据就像是管道中的一滴滴水。字符流和字节流的处理单位不同,但处理方式相似。 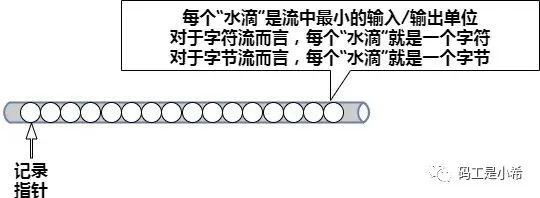
❝输入流使用隐式的「记录指针」来表示当前正准备从哪个“水滴”开始读取,每当程序从「InputStream」或「Reader」中取出“水滴”之后,记录指针自己向后移动,除此之外,「InputStream」和「Reader」里面都提供了一些方法来控制记录指针的移动;
❞
而对于输出流「OutputStream」和「Writer」来说,它们同样是把输出设备抽象成一个“水管”,当执行输出的时候,程序相当于把水管中的“水滴”依次放出。输出流同样采用隐式指针来表示当前输出水滴的位置,每当程序从「OutputStream」或「Writer」中取出水滴的时候,指针也会自动向后移动;
以上展示了JavaIO的基本概念模型,但Java的处理流模型则给我们另一种「输入/输出」流设计的角度: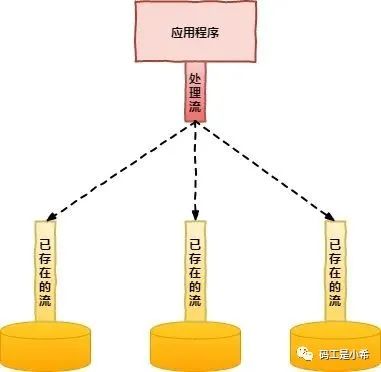 处理流可以在任何已存在的流基础之上,这就允许Java应用程序采用相同的代码,透明的方式来访问不同的输入和输出设备的「数据流」。而在处理流中主要是以增加缓冲的方式来提供输入和输出的效率,且可能提供了一系列「便捷的方法」来一次性输入和输出大批量的内容,而不是输入/输出一个或多个“水滴”。
处理流可以在任何已存在的流基础之上,这就允许Java应用程序采用相同的代码,透明的方式来访问不同的输入和输出设备的「数据流」。而在处理流中主要是以增加缓冲的方式来提供输入和输出的效率,且可能提供了一系列「便捷的方法」来一次性输入和输出大批量的内容,而不是输入/输出一个或多个“水滴”。
❝在处理流中有一个专门提供了一个内存区域用于输入和输出大批量内容的流——「缓冲流」(Buffered Stream);
❞
如果每次操作都是以一个字节/字符为单位,显然这样的数据传输效率很低。为了提高数据传输效率,通常使用缓冲流,即为一个流配有一个「Buffer」,这个缓冲区就是专门用于传送数据的一块内存。
当向一个缓冲流写入数据时,系统将数据发送到缓冲区,而不是直接发送到外部设备。缓冲区自动记录数据,当缓冲区满时,系统将数据「全部发送」到相应的外部设备。而且当从一个缓冲流中读取数据时,系统实际是「从缓冲区中」读取数据。当缓冲区空时,系统就会从相关外部设备自动读取数据,并读取尽可能多的数据填满缓冲区。由此可见,缓冲流提供了内存与外部设备之间的数据传输效率;

从上述我们其实可以窥见JavaIO的特性:
❝「先进先出」,最先写入输出流的数据最先被输入流读取;「顺序存取」,数据的获取和发送是沿着数据序列顺序进行,不能随机访问中间的数据。(但RandomAccessFile可以从文件的任意位置进行存取(输入输出)操作);「只读或只写」,每个流只能是输入流或输出流的一种,不能同时具备两个功能。
❞
小结
可能看了上面的分类,会有读者不清楚什么时候使用字节流,什么时候用输出流。笔者在此整理这几个步骤:
首先自己要知道是选择输入流还是输出流。这就要根据自己的「情况决定」,如果想从程序写东西到别的地方,那么就选择输入流,反之就选输出流;
然后考虑传输数据时,是每次传一个字节还是两个字节,每次传输一个字节就选字节流,如果「存在中文」,那肯定就要选字符流了。
通过前面两步就可以选出一个合适的节点流了,比如字节输入流 InputStream,如果要在此基础上增强功能,那么就在处理流中选择一个合适的即可;
按操作方式分类: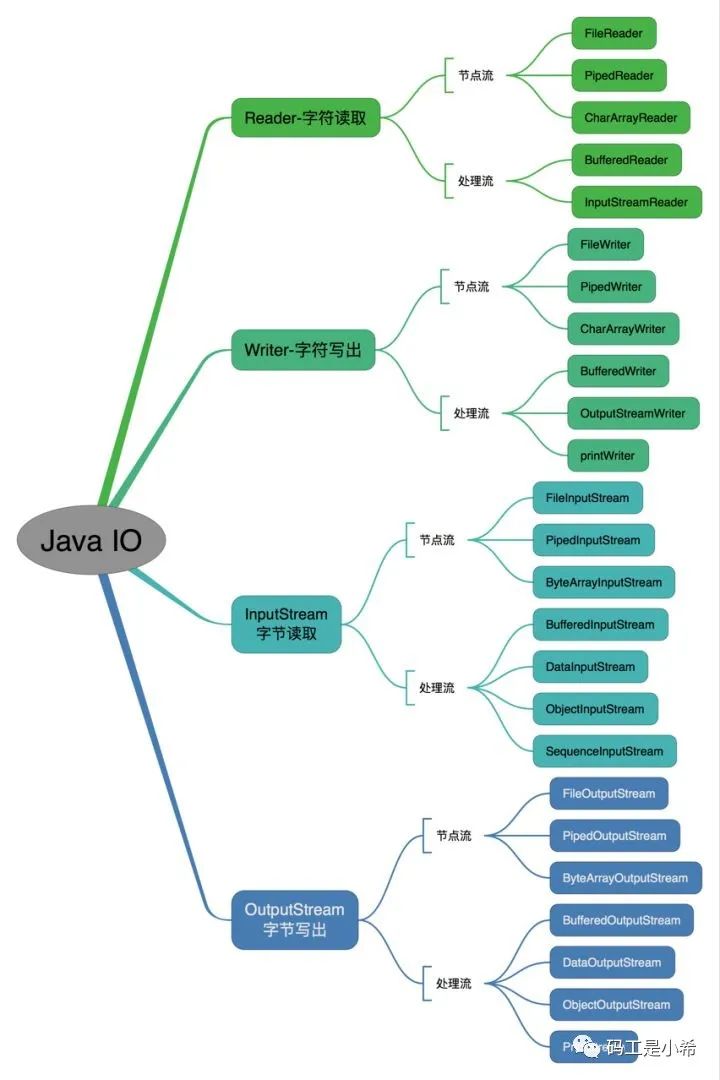 按操作对象分类:
按操作对象分类: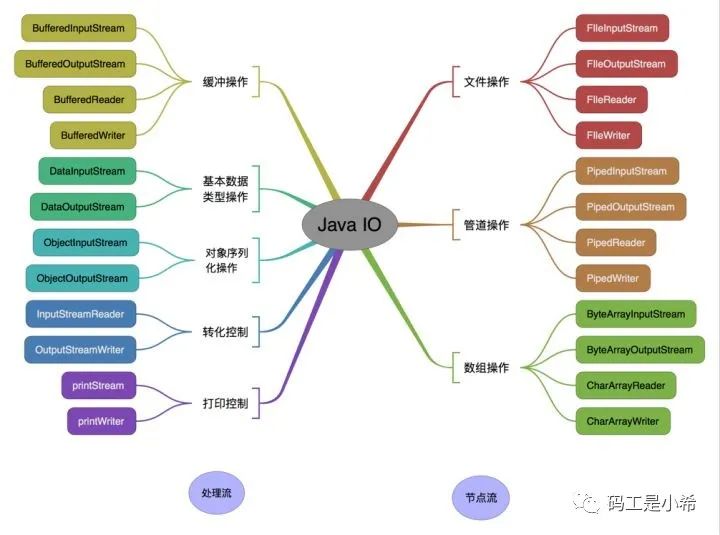
阻塞模型&IO复用
阻塞与非阻塞
阻塞
❝我们知道在调用某个函数的时候无非就是两种情况,要么马上返回,然后根据返回值进行接下来的业务处理。当在使用「阻塞IO」的时候,应用程序会被无情的「挂起」,等待内核完成操作,因为此时的内核可能将CPU时间切换到了其他需要的进程中,在我们的应用程序看来感觉被卡主(阻塞)了;
❞
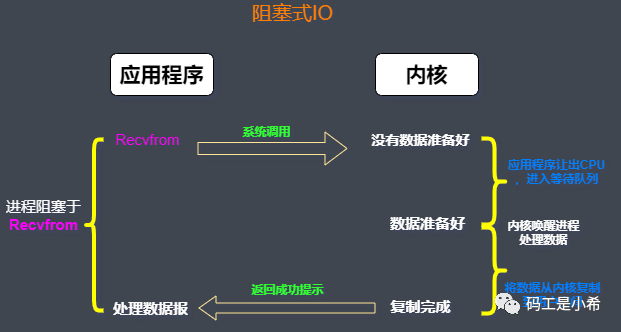
传统阻塞模型
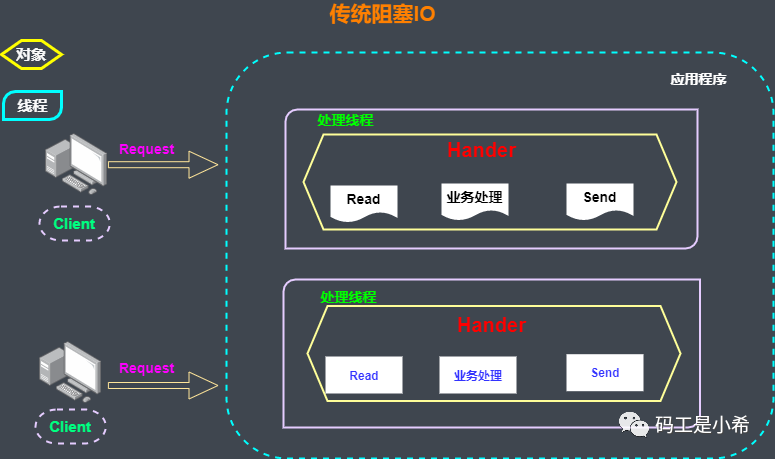
「特点:」
通过阻塞式IO获取「输入」的数据 其中每个连接都采用独立的线程完成数据输入,业务处理以及数据返回的操作
❝这种方案有什么问题?
❞
首先当并发较大的时候,需要创建大量的线程来处理连接,需要占用「大量」的系统资源。
连接建立完成以后,如果当前线程没有数据可读,将会阻塞在「read」操作上造成线程资源的浪费
❝鉴于上面的两个问题,通常是解决方案是啥呢?
❞
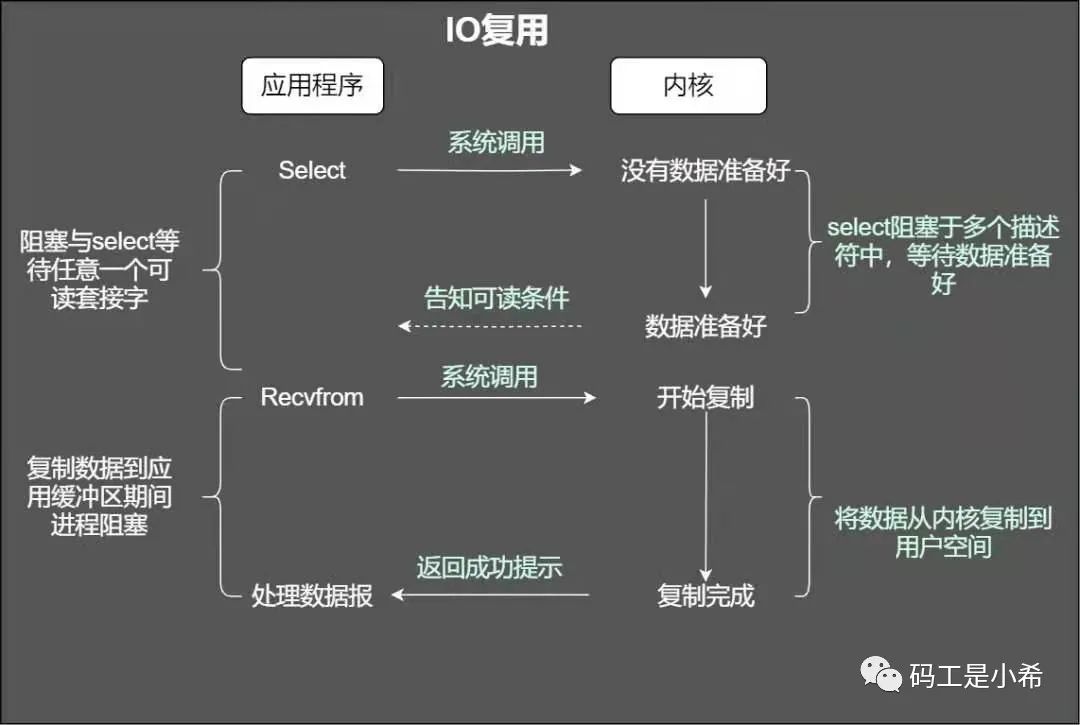
第一种是采用「IO复用的模型」,所谓IO复用模型即「多个连接共享」一个阻塞对象,应用程序只会在一个阻塞对象上等待。当某个连接有新的数据处理,操作系统直接「通知」应用程序,线程从阻塞状态返回并开始业务处理;
第二种方案即采用「线程池复用」的方式。将连接完成后的业务处理任务分配给线程,一个线程处理多个连接的业务。IO复用结合线程池的方案即Reactor模式;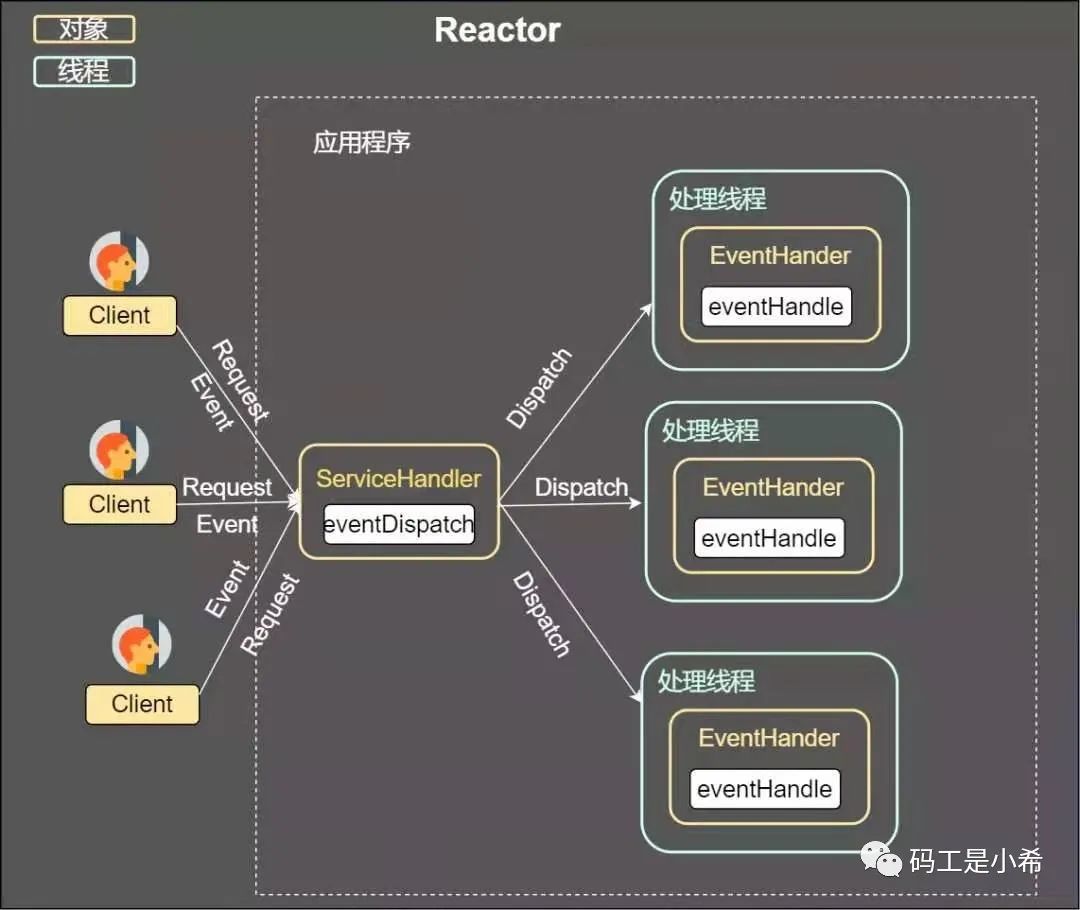 Reactor
Reactor
从上图我们可以发现,通过一个或者多个请求传递给服务器,通过统一的事件管理机制进行请求分发,这种模式即「事件驱动处理模式」。
❝通常一个服务端处理网络请求的过程是啥样的?
❞
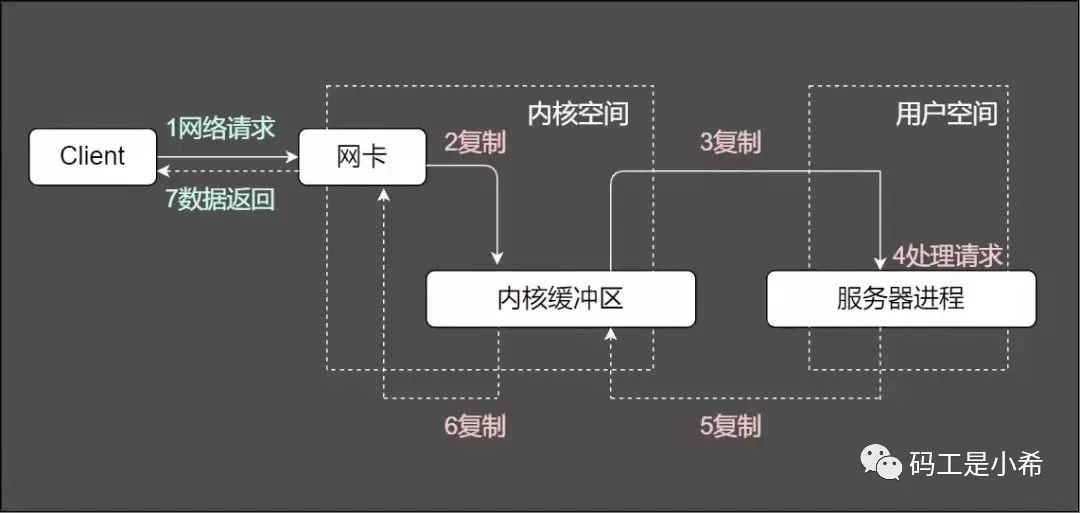 服务端将这些请求分别「同步分派」给多个处理线程,即IO多路复用统一监听事件,收到事件再「进行分发」。那么图中重要的两个关键字是啥意思?
服务端将这些请求分别「同步分派」给多个处理线程,即IO多路复用统一监听事件,收到事件再「进行分发」。那么图中重要的两个关键字是啥意思?
Reactor
❝在一个单独的线程运行,主要负责监听和分发事件。就仿佛我们手机设置的「转接」,将来自前任的电话转接给适当的联系人;
❞
Handlers
❝主要负责处理执行IO实际的事情。
❞
根据Reactor的数量和处理的资源大小通常又分为「单Reactor线程,单Reactor多线程,主从Reactor多线程」。这部分将在文章后面进行详细阐述,先和大家一起复习几个基本概念
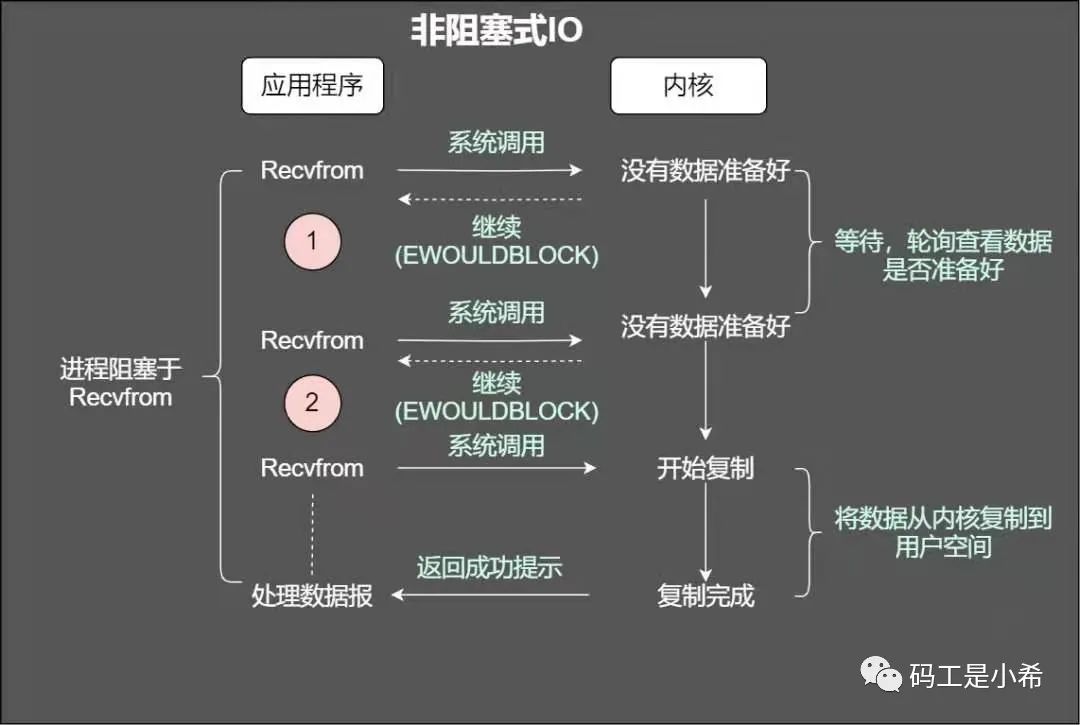
非阻塞
❝当使用非阻塞函数的时候,和阻塞IO类比,内核会立即返回,返回后获得「足够」的CPU时间继续做其他的事情。
❞
这样说可能有点不太好理解:
阿星经常去楼下的小卖部买烟,因为那小姐姐确实乖,即使不买去看看也饱了那种。有一天去买烟,让我等下,他去仓库看看,就一直在那里等着小姐姐回复,就仿佛阻塞在了小姐姐的店。
❝那么阻塞IO是个啥样子嘞?
❞
小姐姐,今天有黄鹤楼烟没,小姐姐看看了柜台,没有,到处找也没有了,然后告诉我这周没有了,下周应该会有货,好嘛,我寂寞的小手颤抖了,其实我就是想去小姐姐家买东西,于是下周我又去问小姐姐,小姐姐果然有心,就知道我回去她家店买,直接给我留了两包黄鹤楼,就这样「反反复复」,和小姐姐的感情越来越好,这样就是阻塞IO的「轮询」,我没有被阻塞而是不断地咨询小姐姐(轮询)。
抽烟的人,经常一句话就是“这一根抽了就不抽了”,怎么能忍住一周?看来轮询效率太低,直接给小姐姐打电话:“小姐姐,烟到了麻烦通知一声,我来你家拿”,这就是「IO多路复用」。
感情嘛,最激烈的时期不外乎是最开始的那么两个月,不,渣男,怎么可能就两个月,感情真是越来越好,然后我就给小姐姐说:“小姐姐,我给你个地址,还有微信,到时候到货了麻烦给我寄过来”,这尼玛,不仅加了微信,还给我送到了家,这就是「异步IO」,至于后续的故事是怎么样的想知道?
好勒,就是写IO模型,配上线程/进程所向披靡;
「非阻塞IO之读」(继续查阅资料)
咱们知道套接字有个「缓冲区」,如果缓冲区没有数据可读,那么在非阻塞的情况下调用read就会立即返回,返回自然会有个状态,不然我们一脸懵逼,无法进行下一步。返回可能是「EWOULDBLOCK或者EAGAIN」出错信息。
「非阻塞IO之写」
刚才我们说了,有个叫做缓冲区的概念,当然也有「发送缓冲区」,如果发送缓冲区满了,不能容纳更多的字节,这个时候操作系统内核就会尽全力从应用程序拷贝数据到发送缓冲区并立即从write调用返回。在拷贝的过程中,可能全部拷贝了,也可能一字节也没拷贝,所以使用返回值来告诉应用程序到底有多少数据拷贝到了发送发送缓冲区,方便再次调用「write」,输出未完成的字节。
总结下两种方式:
「阻塞IO」是:拷贝-知道所有数据拷贝到发送缓冲区。
「非阻塞IO」是拷贝-返回-再拷贝-再返回。ok,read和write的骚操作如下图

说了这么多,当面试官问你的时候,能不能对答如流嘞,总结如下:
「read」总是在接受缓存区有数据的时候直接返回,而不是等到应用程序哥顶的数据充满才返回。如果此时缓冲区是空的,那么阻塞模式会等待,非阻塞则会返回-1并有「EWOULDBLOCK或EAGAIN」错误 和read不太一样的是,在阻塞模式下,write只有在发送缓冲区足矣容纳应用程序的输出字节时才会返回。在「非阻塞的模式」下,能写入多少则写入多少,并返回实际写入的字节数;
❝当使用fgets等待标准输入的时候,如果此时套接字有数据但不能读出。IO多路复用意味着可以将标准输入、套接字等都当做IO的一路,任何一路IO有事件发生,都将通知相应的应用程序去处理相应的IO事件,在我们看来就反复同时可以处理多个事情。这就是IO复用。
❞
字节流和字符流的区别
本质区别只有一个:字节流是原生的操作,字符流是经过处理后的操作。
为什么要有字符流而不直接用字节流呢?
我相信有些读者心里肯定要问这个问题,我刚开始学习的时候也想过这个问题,为什么不直接用字节流解决呢,还非要搞个字符流出来呢。
我的理解是字节流处理「多个字节」表示的东西的时候有可能会出现乱码的问题,比如汉字,用字节流读取的时候有可能因为「一位字节没有读到」就变成了乱码,字符流呢就完美解决了这个问题,字符流你们可以这样理解,「字节流和编码表」的组合就是字符流。因为有了编码表所以「可以确定」这个汉字有多少个字节,这样字节流就可以根据位数准确的读写汉字了;
以上纯为个人理解,如有不对的地方请在评论区给我留言哦。
ByteArrayInputStream & ByteArrayOutputStream
「ByteArrayInputStream」是字节数组输入流,它里面包含一个内部的缓冲区(就是一个字节数组),该缓冲区含有从流中读取的字节。
「ByteArrayOutputStream」是字节数组输出流
ByteArrayInputStream里面的方法:
//通过byte数组来创建对象
public ByteArrayInputStream(byte buf[]) {}
//通过byte数组,并给定开始下标和结束下标来创建对象
public ByteArrayInputStream(byte buf[], int offset, int length){}
//从这个输入流读取下一个字节 末尾会返回
public synchronized int read(){}
//从输入流中读取off到len之间的数据到b中
public synchronized int read(byte b[], int off, int len){}
//跳过并丢弃输入流中的n个数据
public synchronized long skip(long n){}
//可以从此输入流中读取的剩余字节数
public synchronized int available(){}
//判断这个输入流是否支持标记,他一直返回true
public boolean markSupported(){}
//将mark的值设置为当前读取的下标,readAheadLimit这个参数没有意义,因为没用到
public void mark(int readAheadLimit){}
//将当前的下标设置为mark一般和mark()方法一起使用
public synchronized void reset(){}
//关闭这个输入流,因为ByteArrayInputStream操作的是数组所以没有必要关闭流
public void close() throws IOException{}
由于篇幅起见ByteArrayOutputStream代码里面的方法我就不仔细的带你们看了(我不会说我是因为懒才不带你们看的,溜
举个例子,从一个字符串读取数组
```java
public class Test {
public static void main(String[] args) throws IOException {
//创建一个字节输出流对象
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
//一个字节一个字节的写入数据
byteArrayOutputStream.write('h');
byteArrayOutputStream.write('e');
byteArrayOutputStream.write('l');
byteArrayOutputStream.write('l');
byteArrayOutputStream.write('o');
//一个字节数组的写入数据
byteArrayOutputStream.write(" world".getBytes());
ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(byteArrayOutputStream.toByteArray();
//从这个流中读取数据
int b = 0;
//从这个流中一个字节一个字节的读数据
while ((b = byteArrayInputStream.read()) != -1) {
System.out.println((char) b);
}
byteArrayInputStream = new ByteArrayInputStream(bytes);
byte[] bs = new byte[10];
//从这个流中一次性读取bs.length的数据
while ((b = byteArrayInputStream.read(bs)) != -1) {
for (int i = 0; i < b; i++) {
System.out.print((char) bs[i]);
}
System.out.println();
}
}
}
如上代码所示,我平时用的也就这几个方法。
ObjectInputStream & ObjectOutpuStream
「ObjectInputStream」是反序列化流,一般和ObjectOutputStream配合使用;
❝用ObjectOutputStream将java对象序列化然后存入文件中,然后用ObjectInputStream读取出来;这个类的作用,我的理解是有些类在这个程序生命周期结束后,还会被用到所以要序列化保存起来.
❞
ObjectInputStream & ObjectOutpuStream
常用的其实就两个方法:
public final Object readObject(){}
public final void writeObject(Object obj) throws IOException{}
class Data implements Serializable {
private int n;
public Data(int n){
this.n=n;
}
@Override
public String toString(){
return Integer.toString(n);
}
}
public class Test {
public static void main(String[] args) throws IOException, ClassNotFoundException {
Data w=new Data(2);
ObjectOutputStream out=new ObjectOutputStream(new FileOutputStream("worm.out"));
//序列化对象,把对象写到worm.out里面
out.writeObject("Worm storage\n");
//序列化对象,把对象写到worm.out里面
out.writeObject(w);
out.close();
//从worm.out里面读取对象
ObjectInputStream in=new ObjectInputStream(new FileInputStream("worm.out"));
//读取String对象
String s=(String)in.readObject();
//读取Data对象
Data d=(Data)in.readObject();
System.out.println(s+"Data = "+d);
}
}
File的文件读写操作及BufferedInputStream,BufferedOutputStream我另开一篇文章写,里面要介绍的东西很多,我一篇文章介绍不完。
-- End --
往期推荐
我是小希,怕什么真理无穷,进一步有进一步
的欢喜,大家加油!!
【码工是小希】建立了读者技术交流群,群内会有各种大佬在线Batte解答疑问,更有号主呕心沥血整理的精品资料汇总等你来拿,没有套路的那种,白嫖的不香吗;
特色:每天群里会组织技术问答活动,累计积分更够奖金到手,相信你能慢慢的积累,最终厚积薄发的!还能侃职场,反正各种合法的瞎聊(禁止广告)。技术推文允许进入;
备注:“进群”即可

如果本文对大家有那么一点点帮助,请一定给个 点赞 + 再看 支持呀 谢谢你!
